JSON à pandas DataFrame
Ce que j'essaie de faire est d'extraire les données d'altitude d'une API google maps le long d'un chemin spécifié par les coordonnées de latitude et de longitude comme suit:
from urllib2 import Request, urlopen
import json
path1 = '42.974049,-81.205203|42.974298,-81.195755'
request=Request('http://maps.googleapis.com/maps/api/elevation/json?locations='+path1+'&sensor=false')
response = urlopen(request)
elevations = response.read()
Cela me donne une donnée qui ressemble à ceci:
elevations.splitlines()
['{',
' "results" : [',
' {',
' "elevation" : 243.3462677001953,',
' "location" : {',
' "lat" : 42.974049,',
' "lng" : -81.205203',
' },',
' "resolution" : 19.08790397644043',
' },',
' {',
' "elevation" : 244.1318664550781,',
' "location" : {',
' "lat" : 42.974298,',
' "lng" : -81.19575500000001',
' },',
' "resolution" : 19.08790397644043',
' }',
' ],',
' "status" : "OK"',
'}']
Lors de la mise en as DataFrame voici ce que je reçois:

pd.read_json(elevations)
Et voici ce que je veux:
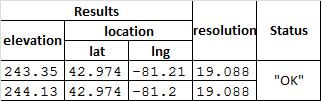
Je ne suis pas sûr si cela est possible, mais surtout ce que je cherche est un moyen de pouvoir mettre l'altitude, la latitude et les données de longitude ensemble dans un dataframe pandas (ne doit pas avoir d'en-têtes multilignes de fantaisie).
Si quelqu'un peut aider ou donner des conseils sur le travail avec ces données qui serait génial! Si vous ne pouvez pas dire que je n'ai pas beaucoup travaillé avec les données json auparavant...
Modifier:
Cette méthode n'est pas si attrayante mais semble fonctionner:
data = json.loads(elevations)
lat,lng,el = [],[],[]
for result in data['results']:
lat.append(result[u'location'][u'lat'])
lng.append(result[u'location'][u'lng'])
el.append(result[u'elevation'])
df = pd.DataFrame([lat,lng,el]).T
Finit par dataframe ayant des colonnes latitude, longitude, altitude
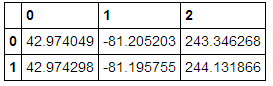
4 réponses
J'ai trouvé une solution rapide et facile à ce que je voulais en utilisant la fonction json_normalize incluse dans la dernière version de pandas 0.13.
from urllib2 import Request, urlopen
import json
from pandas.io.json import json_normalize
path1 = '42.974049,-81.205203|42.974298,-81.195755'
request=Request('http://maps.googleapis.com/maps/api/elevation/json?locations='+path1+'&sensor=false')
response = urlopen(request)
elevations = response.read()
data = json.loads(elevations)
json_normalize(data['results'])
Cela donne un joli dataframe aplati avec les données json que j'ai obtenues de l'API google maps.
Vérifiez ce snip out.
# reading the JSON data using json.load()
file = 'data.json'
with open(file) as train_file:
dict_train = json.load(train_file)
# converting json dataset from dictionary to dataframe
train = pd.DataFrame.from_dict(dict_train, orient='index')
train.reset_index(level=0, inplace=True)
J'espère que ça aide:)
Vous pouvez d'abord importer vos données json dans un dictionnaire Python:
data = json.loads(elevations)
Puis modifiez les données à la volée:
for result in data['results']:
result[u'lat']=result[u'location'][u'lat']
result[u'lng']=result[u'location'][u'lng']
del result[u'location']
Reconstruire la chaîne json:
elevations = json.dumps(data)
Enfin :
pd.read_json(elevations)
Vous pouvez également éviter de vider les données dans une chaîne, je suppose que Panda peut directement créer un DataFrame à partir d'un dictionnaire (Je ne l'ai pas utilisé depuis longtemps :p)
Le problème est que vous avez plusieurs colonnes dans le cadre de données qui contiennent des dicts avec des dicts plus petits à l'intérieur. JSON utile est souvent fortement imbriqué. J'ai écrit de petites fonctions qui tirent l'information que je veux dans une nouvelle colonne. De cette façon, je l'ai dans le format que je veux utiliser.
for row in range(len(data)):
#First I load the dict (one at a time)
n = data.loc[row,'dict_column']
#Now I make a new column that pulls out the data that I want.
data.loc[row,'new_column'] = n.get('key')