Java, Comment obtenir le nombre de messages dans un sujet dans apache kafka
j'utilise apache kafka pour la messagerie. J'ai implémenté le producteur et le consommateur en Java. Comment pouvons-nous obtenir le nombre de messages dans un topic?
13 réponses
la seule façon qui vient à l'esprit pour cela du point de vue du consommateur est de consommer réellement les messages et de les compter alors.
le courtier Kafka expose les compteurs JMX pour le nombre de messages reçus depuis le démarrage, mais vous ne pouvez pas savoir combien d'entre eux ont déjà été purgés.
dans les scénarios les plus courants, les messages de Kafka sont mieux vus comme un flot infini et obtiennent une valeur discrète du nombre de messages qui est actuellement maintenu sur le disque n'est pas pertinent. En outre les choses deviennent plus compliquées en traitant avec un faisceau de courtiers qui ont tous un sous-ensemble des messages dans un sujet.
Ce n'est pas java, mais peut être utile
./bin/kafka-run-class.sh kafka.tools.GetOffsetShell
--broker-list <broker>: <port>
--topic <topic-name> --time -1 --offsets 1
| awk -F ":" '{sum += } END {print sum}'
en fait, je l'utilise pour comparer mon POC. L'article que vous voulez utiliser ConsumerOffsetChecker. Vous pouvez l'exécuter en utilisant le script bash comme ci-dessous.
bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --topic test --zookeeper localhost:2181 --group testgroup
Et ci-dessous est le résultat :
 Comme vous pouvez le voir sur la zone rouge 999 est le nombre de messages actuellement dans la rubrique.
Comme vous pouvez le voir sur la zone rouge 999 est le nombre de messages actuellement dans la rubrique.
mise à jour: ConsumerOffsetChecker est déprécié depuis 0.10.0, vous pouvez vouloir commencer à utiliser ConsumerGroupCommand.
utiliser https://prestodb.io/docs/current/connector/kafka-tutorial.html
un super moteur SQL, fourni par Facebook, qui se connecte sur plusieurs sources de données (Cassandra, Kafka, JMX, Redis ...).
PrestoDB fonctionne comme un serveur avec des travailleurs optionnels (il y a un mode autonome sans travailleurs supplémentaires), puis vous utilisez un petit JAR exécutable (appelé presto CLI) pour faire des requêtes.
une fois que vous avez bien configuré le serveur Presto, vous pouvez utiliser le SQL traditionnel:
SELECT count(*) FROM TOPIC_NAME;
pour obtenir tous les messages stockés pour le sujet, vous pouvez chercher le consommateur au début et à la fin du flux pour chaque partition et la somme des résultats""
List<TopicPartition> partitions = consumer.partitionsFor(topic).stream()
.map(p -> new TopicPartition(topic, p.partition()))
.collect(Collectors.toList());
consumer.assign(partitions);
consumer.seekToEnd(Collections.emptySet());
Map<TopicPartition, Long> endPartitions = partitions.stream()
.collect(Collectors.toMap(Function.identity(), consumer::position));
consumer.seekToBeginning(Collections.emptySet());
System.out.println(partitions.stream().mapToLong(p -> endPartitions.get(p) - consumer.position(p)).sum());
commande Apache Kafka pour obtenir des messages un manipulés sur toutes les partitions d'un sujet:
kafka-run-class kafka.tools.ConsumerOffsetChecker
--topic test --zookeeper localhost:2181
--group test_group
Imprime:
Group Topic Pid Offset logSize Lag Owner
test_group test 0 11051 11053 2 none
test_group test 1 10810 10812 2 none
test_group test 2 11027 11028 1 none
la colonne 6 contient les messages non traités. Additionnez - les comme ceci:
kafka-run-class kafka.tools.ConsumerOffsetChecker
--topic test --zookeeper localhost:2181
--group test_group 2>/dev/null | awk 'NR>1 {sum += }
END {print sum}'
awk lit les lignes, saute la ligne d'en-tête et additionne la sixième colonne et à la fin imprime la somme.
Imprime
5
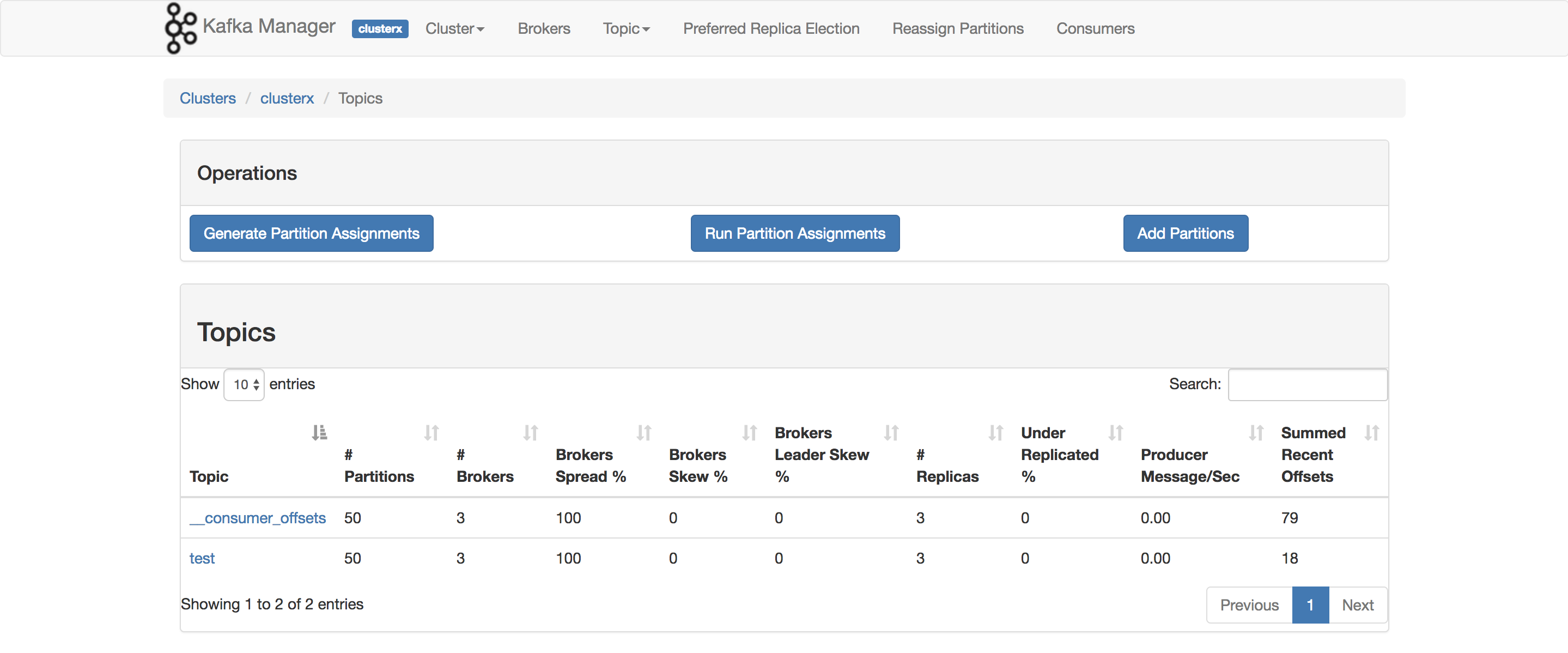
dans les versions les plus récentes de Kafka Manager, il y a une colonne intitulée additionné récents décalages .
parfois, l'intérêt est de savoir le nombre de messages dans chaque partition, par exemple, lors de l'essai d'un partitionneur personnalisé.Les étapes suivantes ont été testées pour fonctionner avec Kafka 0.10.2.1-2 de Confluent 3.2. Étant donné un sujet de Kafka, kt et la ligne de commande suivante:
$ kafka-run-class kafka.tools.GetOffsetShell \
--broker-list host01:9092,host02:9092,host02:9092 --topic kt
qui imprime la sortie d'échantillon montrant le nombre de messages dans les trois partitions:
kt:2:6138
kt:1:6123
kt:0:6137
le nombre de lignes pourrait être plus ou moins selon le nombre de partitions du sujet.
en utilisant le client Java de Kafka 2.11-1.0.0, vous pouvez faire la chose suivante:
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("test"));
while(true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
// after each message, query the number of messages of the topic
Set<TopicPartition> partitions = consumer.assignment();
Map<TopicPartition, Long> offsets = consumer.endOffsets(partitions);
for(TopicPartition partition : offsets.keySet()) {
System.out.printf("partition %s is at %d\n", partition.topic(), offsets.get(partition));
}
}
}
sortie est quelque chose comme ceci:
offset = 10, key = null, value = un
partition test is at 13
offset = 11, key = null, value = deux
partition test is at 13
offset = 12, key = null, value = trois
partition test is at 13
./kafka-console-consumer.sh -à partir de début --nouvelle-consommateurs --bootstrap-serveur yourbroker:9092 --propriété d'impression.clé=true --propriété d'impression.valeur=false -- propriété print.partition --sujet yourtopic --timeout-ms 5000 | tail-n 10|grep "a Traité un total de"
extraits de Kafka docs
dépréciations en 0.9.0.0
le kafka-consumer-offset-checker.sh (kafka.outils.ConsumerOffsetChecker) a été déprécié. Aller de l'avant, s'il vous plaît utiliser kafka-consumer-groups.sh (kafka.admin.ConsumerGroupCommand) pour cette fonctionnalité.
J'exécute Kafka broker avec SSL activé à la fois pour le serveur et le client. Sous la commande j'utilise
kafka-consumer-groups.sh --bootstrap-server Broker_IP:Port --list --command-config /tmp/ssl_config
kafka-consumer-groups.sh --bootstrap-server Broker_IP:Port --command-config /tmp/ssl_config --describe --group group_name_x
où /tmp/ssl_config est comme ci-dessous
security.protocol=SSL
ssl.truststore.location=truststore_file_path.jks
ssl.truststore.password=truststore_password
ssl.keystore.location=keystore_file_path.jks
ssl.keystore.password=keystore_password
ssl.key.password=key_password
si vous avez accès à l'interface JMX du serveur, les offsets start & end sont présents à:
kafka.log:type=Log,name=LogStartOffset,topic=TOPICNAME,partition=PARTITIONNUMBER
kafka.log:type=Log,name=LogEndOffset,topic=TOPICNAME,partition=PARTITIONNUMBER
(vous devez remplacer TOPICNAME & PARTITIONNUMBER ).
Gardez à l'esprit que vous avez besoin de vérifier pour chacune des répliques de la partition donnée, ou vous avez besoin de trouver lequel des courtiers est le chef de file pour une donnée partition (et cela peut changer avec le temps).
alternativement, vous pouvez utiliser Kafka consommateur méthodes beginningOffsets et endOffsets .