La mauvaise performance de std:: vector est-elle due au fait de ne pas appeler realloc un nombre logarithmique de fois?
EDIT: j'ai ajouté deux autres benchmarks, pour comparer l'utilisation de realloc avec le tableau C et de reserve() avec le std::vector. De la dernière analyse il semble que realloc influence beaucoup, même si appelé seulement 30 fois. Vérifier la documentation je suppose que c'est dû au fait que realloc peut retourner un pointeur complètement nouveau, en copiant l'ancien.
Pour compléter le scénario j'ai également ajouté le code et le graphique pour allouer complètement le tableau pendant le initialisation. La différence avec reserve() est tangible.
compilent les options: seulement l'optimisation décrite dans le graphique, compilant avec g++ et rien de plus.
question originale:
j'ai fait un benchmark de std::vector vs un nouveau tableau/supprimer, quand j'ajoute 1 milliard d'entiers et le deuxième code est considérablement plus rapide que celui qui utilise le vecteur, en particulier avec l'optimisation activée.
je soupçonne que cela est causé par le vecteur appel interne realloc beaucoup trop de fois. Ce serait le cas si vector ne se développe pas en doublant sa taille à chaque fois qu'il est rempli (ici le nombre 2 n'a rien de spécial, ce qui importe est que sa taille se développe géométriquement).
Dans ce cas, les appels à realloc seraient seulement O(log n) au lieu de O(n) .
si c'est ce qui cause la lenteur du premier code, Comment puis-je dire std:: vecteur de croissance géométrique?
Notez que l'appel de réserve, une fois fonctionnerait dans ce cas, mais pas dans le cas plus général où le nombre de push_back n'est pas connu à l'avance.
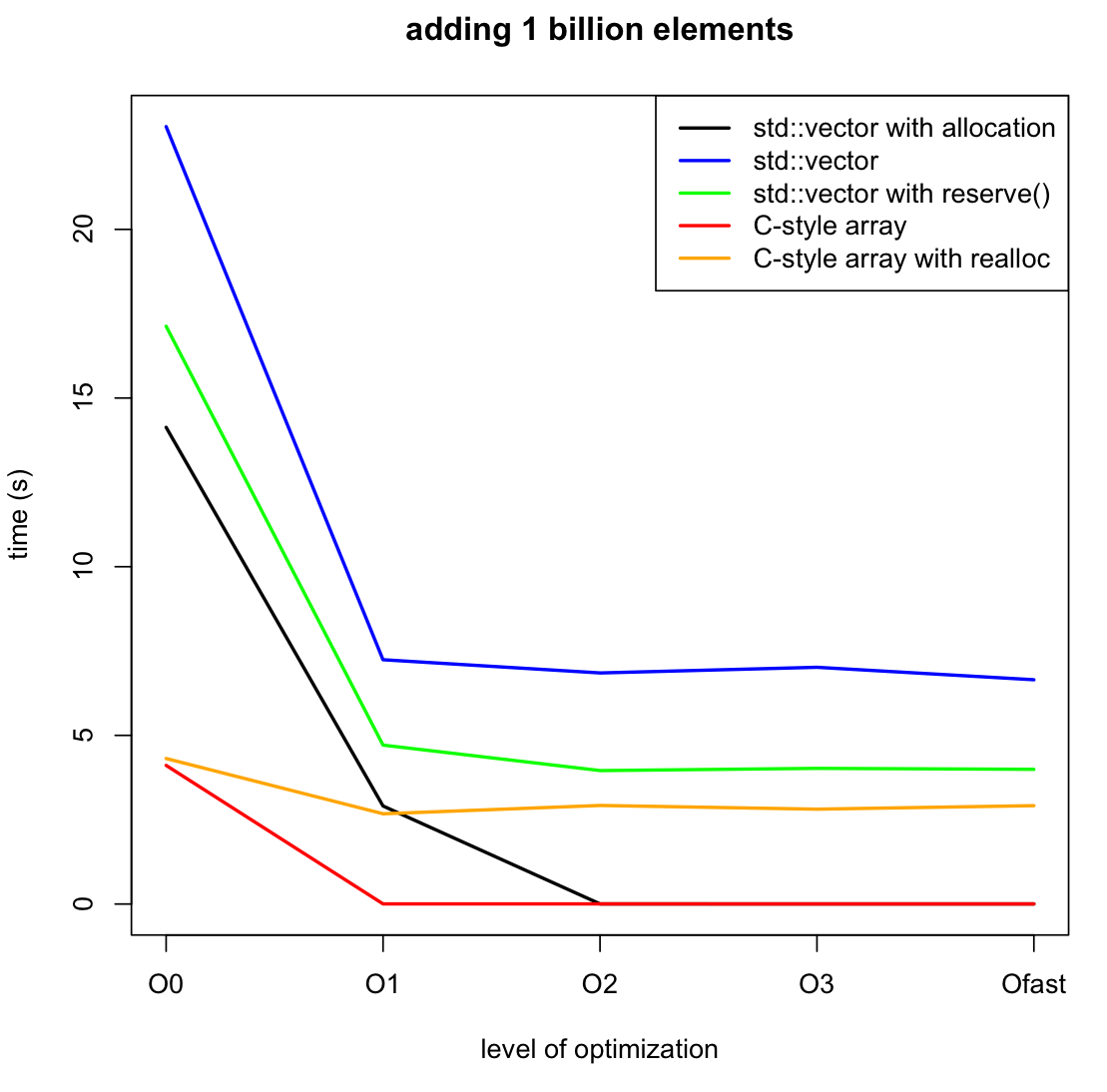
ligne noire
#include<vector>
int main(int argc, char * argv[]) {
const unsigned long long size = 1000000000;
std::vector <int> b(size);
for(int i = 0; i < size; i++) {
b[i]=i;
}
return 0;
}
ligne bleue
#include<vector>
int main(int argc, char * argv[]) {
const int size = 1000000000;
std::vector <int> b;
for(int i = 0; i < size; i++) {
b.push_back(i);
}
return 0;
}
ligne verte
#include<vector>
int main(int argc, char * argv[]) {
const int size = 1000000000;
std::vector <int> b;
b.reserve(size);
for(int i = 0; i < size; i++) {
b.push_back(i);
}
return 0;
}
ligne rouge
int main(int argc, char * argv[]) {
const int size = 1000000000;
int * a = new int [size];
for(int i = 0; i < size; i++) {
a[i] = i;
}
delete [] a;
return 0;
}
ligne orange
#include<vector>
int main(int argc, char * argv[]) {
const unsigned long long size = 1000000000;
int * a = (int *)malloc(size*sizeof(int));
int next_power = 1;
for(int i = 0; i < size; i++) {
a[i] = i;
if(i == next_power - 1) {
next_power *= 2;
a=(int*)realloc(a,next_power*sizeof(int));
}
}
free(a);
return 0;
}
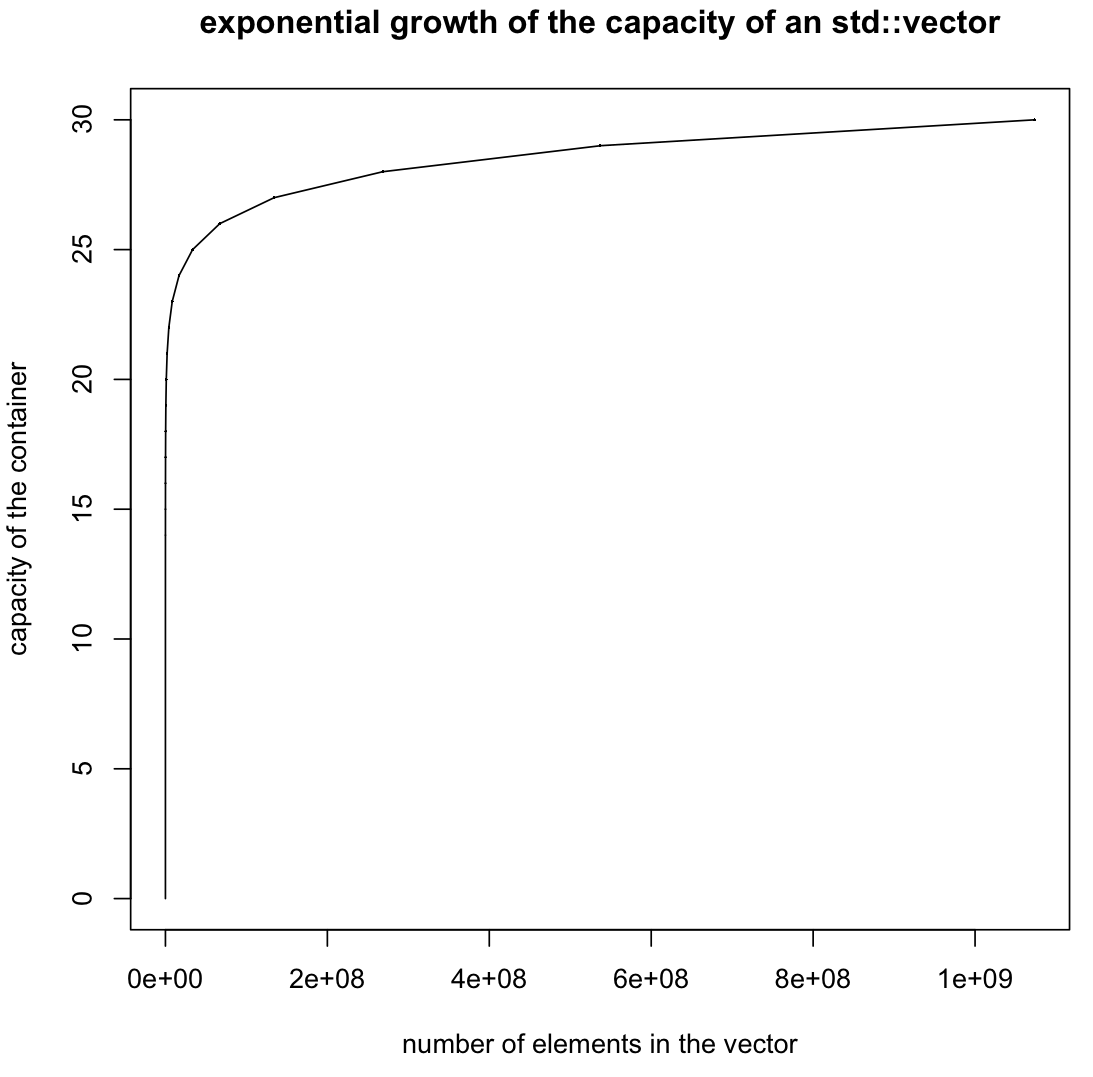
EDIT: en cochant la case .capacity() , comme l'a suggéré, nous avons vu que la croissance est exponentielle. Alors pourquoi le vecteur est si lent?
5 réponses
le tableau de style C optimisé est optimisé à rien.
xorl %eax, %eax
retq
, c'est le programme.
chaque fois que vous avez un programme optimisé à près de 0s vous devriez considérer cette possibilité.
l'optimiseur voit que vous ne faites rien avec la mémoire allouée, note que la mémoire d'allocation non utilisée peut avoir zéro effets secondaires, et élimine les allocation.
et écrire à la mémoire puis Ne jamais le lire a également zéro effets secondaires.
en comparaison, le compilateur a de la difficulté à prouver que l'allocation du vecteur est inutile. Probablement les développeurs de compilateurs pourraient lui apprendre à reconnaître les vecteurs std inutilisés comme ils reconnaissent les matrices c brutes inutilisées, mais cette optimisation est vraiment un cas de coin, et il provoque beaucoup de problèmes de profilage dans mon expérience.
noter que le vector-with-reserve à tout niveau d'optimisation est essentiellement la même vitesse que la version de style C non optimisée.
dans le code de style C, la seule chose à optimiser est"ne faites rien". Dans le code vectoriel, la version non optimisée est remplie de cadres de pile supplémentaires et de vérifications de débogage pour s'assurer que vous ne dépassez pas les limites (et que vous ne vous écrasez pas proprement si vous le faites).
notez que sur un système Linux, allouer d'énormes morceaux de mémoire ne fait que jouer avec la table mémoire virtuelle. Ce n'est que lorsque la mémoire est touchée qu'elle trouve une mémoire physique nulle pour vous.
sans réserve, le vecteur std doit deviner une petite taille initiale, le redimensionner une copie, et répéter. Cela entraîne une perte de rendement de 50%, ce qui me semble raisonnable.
Avec réserve, en effet, il fait le travail. Le travail prend un peu moins de 5s.
ajouter à vector via push back fait qu'il pousse géométriquement. La croissance géométrique résulte en une moyenne asymptotique de 2-3 copies de chaque morceau de données étant faites.
Comme pour le realloc, std::vector ne pas realloc. Il alloue un nouveau tampon, et copie les anciennes données, puis écarte l'ancienne.
Realloc tente de faire pousser le buffer, et s'il ne peut pas, il copie le buffer en bits.
qui est plus efficace que le vecteur std peut gérer les types de copie bitwise. Je parie que la version realloc ne copie jamais; il y a toujours de l'espace mémoire pour faire pousser le vecteur (dans un vrai programme, ce n'est peut-être pas le cas).
Le manque de realloc en std bibliothèque allocateurs est un défaut mineur. Vous devez inventer une nouvelle API pour cela, parce que vous voulez qu'elle fonctionne pour la copie non-bitwise (quelque chose comme "essayer de développer la mémoire allouée", qui si elle échoue laisse à vous de faire croître l'allocation).
quand j'ajoute 1 milliard d'entiers et le deuxième code est dramatiquement plus rapide que celui qui utilise le vecteur
C'est-à-dire... complètement surprenant. L'un de vos cas concerne un conteneur de taille dynamique qui doit être réajusté en fonction de sa charge, et l'autre concerne un conteneur de taille fixe qui ne l'est pas. Ce dernier doit simplement faire beaucoup moins de travail, pas de ramification, pas d'allocations supplémentaires. La juste comparaison serait:
std::vector<int> b(size);
for(int i = 0; i < size; i++) {
b[i] = i;
}
Cela fait maintenant la même chose que votre exemple de tableau (bien, presque - new int[size] par défaut-initialise tous les int s tandis que std::vector<int>(size) zéro-initialise les, donc c'est encore plus de travail).
il n'est pas vraiment logique de comparer ces deux-là. Si le tableau de taille fixe int s'adapte à votre cas d'utilisation, alors utilisez-le. Si ce n'est pas le cas, alors ne le fais pas. Vous avez besoin d'un conteneur de taille dynamique ou pas. Si vous le faites, exécution plus lente qu'une solution de taille fixe est quelque chose que vous abandonnez implicitement.
si c'est ce qui cause la lenteur du premier code, Comment puis-je dire
std::vectorà se développer géométriquement?
std::vector est déjà mandaté pour croître géométriquement déjà, c'est la seule façon de maintenir O(1) amorti push_back complexité.
Est la mauvaise performance de std::vector en raison de ne pas appeler le realloc logarithmique nombre de fois?
Votre test n'appuie pas cette conclusion et ne prouve pas le contraire. Cependant, je suppose que la réaffectation est appelée nombre linéaire de fois à moins qu'il n'y ait des preuves contraires.
mise à jour: votre nouveau test est apparemment une preuve contre votre réallocation Non-logarithmique hypothèse.
je soupçonne que cela est causé par le vecteur appel interne realloc beaucoup trop de fois.
mise à jour: votre nouveau test montre que une partie de la différence est due à des réaffectations... mais pas toutes. Je soupçonne que le reste est dû au fait que optimizer a été en mesure de prouver (mais seulement dans le cas de la non-croissance) que les valeurs du tableau ne sont pas utilisées, et a choisi de ne pas boucle et écrire à tous les. Si vous deviez vous assurer que les valeurs écrites sont effectivement utilisées, alors je m'attendrais à ce que le tableau sans croissance ait des performances optimisées similaires à celles du vecteur de réservation.
la différence (entre le code de réservation et le vecteur de non-réservation) dans la construction optimisée est très probablement due à faire des réallocations plus (comparé à des réallocations Non du tableau réservé). Si le nombre de réaffectations est trop est de la situation et subjective. L'inconvénient de faire moins de réaffectations est plus de gaspillage d'espace en raison de la surallocation.
noter que le coût de réattribution de grands tableaux vient principalement de la copie d'éléments, plutôt que l'attribution de mémoire elle-même.
dans la construction non optimisée, il y a probablement des frais généraux linéaires supplémentaires en raison d'appels de fonction qui n'ont pas été élargis en ligne.
comment dire std:: vecteur de se développer géométriquement?
la croissance géométrique est requise par la norme. Il n'y a aucun moyen, et pas besoin de dire std::vector pour utiliser la croissance géométrique.
Notez que l'appel de réserve, une fois fonctionnerait dans ce cas, mais pas dans le cas plus général où le nombre de push_back n'est pas connu à l'avance.
Cependant, un cas général dans lequel le nombre de push_back n'est pas connu à l'avance est un cas où le tableau Non-croissant n'est même pas une option et donc sa performance est hors de propos pour ce cas général.
il ne s'agit pas de comparer la croissance géométrique à la croissance arithmétique (ou autre). Il s'agit de comparer la pré-allocation de tout l'espace nécessaire à la croissance de l'espace selon les besoins. Donc, commençons par comparer std::vector à un code qui utilise réellement la croissance géométrique, et utiliser les deux de manière à mettre la croissance géométrique à utiliser 1 . Donc, voici une classe simple qui fait la croissance géométrique:
class my_vect {
int *data;
size_t current_used;
size_t current_alloc;
public:
my_vect()
: data(nullptr)
, current_used(0)
, current_alloc(0)
{}
void push_back(int val) {
if (nullptr == data) {
data = new int[1];
current_alloc = 1;
}
else if (current_used == current_alloc) {
int *temp = new int[current_alloc * 2];
for (size_t i=0; i<current_used; i++)
temp[i] = data[i];
swap(temp, data);
delete [] temp;
current_alloc *= 2;
}
data[current_used++] = val;
}
int &at(size_t index) {
if (index >= current_used)
throw bad_index();
return data[index];
}
int &operator[](size_t index) {
return data[index];
}
~my_vect() { delete [] data; }
};
...et voici quelques codes pour l'exercer (et faites la même chose avec std::vector ):
int main() {
std::locale out("");
std::cout.imbue(out);
using namespace std::chrono;
std::cout << "my_vect\n";
for (int size = 100; size <= 1000000000; size *= 10) {
auto start = high_resolution_clock::now();
my_vect b;
for(int i = 0; i < size; i++) {
b.push_back(i);
}
auto stop = high_resolution_clock::now();
std::cout << "Size: " << std::setw(15) << size << ", Time: " << std::setw(15) << duration_cast<microseconds>(stop-start).count() << " us\n";
}
std::cout << "\nstd::vector\n";
for (int size = 100; size <= 1000000000; size *= 10) {
auto start = high_resolution_clock::now();
std::vector<int> b;
for (int i = 0; i < size; i++) {
b.push_back(i);
}
auto stop = high_resolution_clock::now();
std::cout << "Size: " << std::setw(15) << size << ", Time: " << std::setw(15) << duration_cast<microseconds>(stop - start).count() << " us\n";
}
}
j'ai compilé avec g++ -std=c++14 -O3 my_vect.cpp . Quand j'exécute cela, j'obtiens ce résultat:
my_vect
Size: 100, Time: 8 us
Size: 1,000, Time: 23 us
Size: 10,000, Time: 141 us
Size: 100,000, Time: 950 us
Size: 1,000,000, Time: 8,040 us
Size: 10,000,000, Time: 51,404 us
Size: 100,000,000, Time: 442,713 us
Size: 1,000,000,000, Time: 7,936,013 us
std::vector
Size: 100, Time: 40 us
Size: 1,000, Time: 4 us
Size: 10,000, Time: 29 us
Size: 100,000, Time: 426 us
Size: 1,000,000, Time: 3,730 us
Size: 10,000,000, Time: 41,294 us
Size: 100,000,000, Time: 363,942 us
Size: 1,000,000,000, Time: 5,200,545 us
je pourrais sans doute optimiser le my_vect pour suivre le std::vector (par exemple, allouer initialement de l'espace pour, disons, 256 articles serait probablement une assez grande aide). Je n'ai pas essayé de faire assez d'essais (et d'analyse statistique) pour être sûr que std::vector est vraiment de manière fiable plus rapide que my_vect l'un ou l'autre. Néanmoins, cela semble indiquer que lorsque nous comparons des pommes à des pommes, nous obtenons des résultats qui sont au moins à peu près comparables (p. ex., à l'intérieur d'un facteur constant et assez faible l'un de l'autre).
1. Comme note d'accompagnement, je me sens obligé de souligner que cela ne compare toujours pas vraiment des pommes aux pommes--mais au moins aussi longtemps que nous sommes seulement instantiating std::vector plus int , de nombreuses différences évidentes sont essentiellement couverts.
Ce poste sont les
- classes d'emballage sur
realloc,mremappour fournir la fonctionnalité de réaffectation. - une classe vectorielle personnalisée.
- Un test de performance.
// C++17
#include <benchmark/benchmark.h> // Googleo benchmark lib, for benchmark.
#include <new> // For std::bad_alloc.
#include <memory> // For std::allocator_traits, std::uninitialized_move.
#include <cstdlib> // For C heap management API.
#include <cstddef> // For std::size_t, std::max_align_t.
#include <cassert> // For assert.
#include <utility> // For std::forward, std::declval,
namespace linux {
#include <sys/mman.h> // For mmap, mremap, munmap.
#include <errno.h> // For errno.
auto get_errno() noexcept {
return errno;
}
}
/*
* Allocators.
* These allocators will have non-standard compliant behavior if the type T's cp ctor has side effect.
*/
// class mrealloc are usefull for allocating small space for
// std::vector.
//
// Can prevent copy of data and memory fragmentation if there's enough
// continous memory at the original place.
template <class T>
struct mrealloc {
using pointer = T*;
using value_type = T;
auto allocate(std::size_t len) {
if (auto ret = std::malloc(len))
return static_cast<pointer>(ret);
else
throw std::bad_alloc();
}
auto reallocate(pointer old_ptr, std::size_t old_len, std::size_t len) {
if (auto ret = std::realloc(old_ptr, len))
return static_cast<pointer>(ret);
else
throw std::bad_alloc();
}
void deallocate(void *ptr, std::size_t len) noexcept {
std::free(ptr);
}
};
// class mmaprealloc is suitable for large memory use.
//
// It will be usefull for situation that std::vector can grow to a huge
// size.
//
// User can call reserve without worrying wasting a lot of memory.
//
// It can prevent data copy and memory fragmentation at any time.
template <class T>
struct mmaprealloc {
using pointer = T*;
using value_type = T;
auto allocate(std::size_t len) const
{
return allocate_impl(len, MAP_PRIVATE | MAP_ANONYMOUS);
}
auto reallocate(pointer old_ptr, std::size_t old_len, std::size_t len) const
{
return reallocate_impl(old_ptr, old_len, len, MREMAP_MAYMOVE);
}
void deallocate(pointer ptr, std::size_t len) const noexcept
{
assert(linux::munmap(ptr, len) == 0);
}
protected:
auto allocate_impl(std::size_t _len, int flags) const
{
if (auto ret = linux::mmap(nullptr, get_proper_size(_len), PROT_READ | PROT_WRITE, flags, -1, 0))
return static_cast<pointer>(ret);
else
fail(EAGAIN | ENOMEM);
}
auto reallocate_impl(pointer old_ptr, std::size_t old_len, std::size_t _len, int flags) const
{
if (auto ret = linux::mremap(old_ptr, old_len, get_proper_size(_len), flags))
return static_cast<pointer>(ret);
else
fail(EAGAIN | ENOMEM);
}
static inline constexpr const std::size_t magic_num = 4096 - 1;
static inline auto get_proper_size(std::size_t len) noexcept -> std::size_t {
return round_to_pagesize(len);
}
static inline auto round_to_pagesize(std::size_t len) noexcept -> std::size_t {
return (len + magic_num) & ~magic_num;
}
static inline void fail(int assert_val)
{
auto _errno = linux::get_errno();
assert(_errno == assert_val);
throw std::bad_alloc();
}
};
template <class T>
struct mmaprealloc_populate_ver: mmaprealloc<T> {
auto allocate(size_t len) const
{
return mmaprealloc<T>::allocate_impl(len, MAP_PRIVATE | MAP_ANONYMOUS | MAP_POPULATE);
}
};
namespace impl {
struct disambiguation_t2 {};
struct disambiguation_t1 {
constexpr operator disambiguation_t2() const noexcept { return {}; }
};
template <class Alloc>
static constexpr auto has_reallocate(disambiguation_t1) noexcept -> decltype(&Alloc::reallocate, bool{}) { return true; }
template <class Alloc>
static constexpr bool has_reallocate(disambiguation_t2) noexcept { return false; }
template <class Alloc>
static inline constexpr const bool has_reallocate_v = has_reallocate<Alloc>(disambiguation_t1{});
} /* impl */
template <class Alloc>
struct allocator_traits: public std::allocator_traits<Alloc> {
using Base = std::allocator_traits<Alloc>;
using value_type = typename Base::value_type;
using pointer = typename Base::pointer;
using size_t = typename Base::size_type;
static auto reallocate(Alloc &alloc, pointer prev_ptr, size_t prev_len, size_t new_len) {
if constexpr(impl::has_reallocate_v<Alloc>)
return alloc.reallocate(prev_ptr, prev_len, new_len);
else {
auto new_ptr = Base::allocate(alloc, new_len);
// Move existing array
for(auto _prev_ptr = prev_ptr, _new_ptr = new_ptr; _prev_ptr != prev_ptr + prev_len; ++_prev_ptr, ++_new_ptr) {
new (_new_ptr) value_type(std::move(*_prev_ptr));
_new_ptr->~value_type();
}
Base::deallocate(alloc, prev_ptr, prev_len);
return new_ptr;
}
}
};
template <class T, class Alloc = std::allocator<T>>
struct vector: protected Alloc {
using alloc_traits = allocator_traits<Alloc>;
using pointer = typename alloc_traits::pointer;
using size_t = typename alloc_traits::size_type;
pointer ptr = nullptr;
size_t last = 0;
size_t avail = 0;
~vector() noexcept {
alloc_traits::deallocate(*this, ptr, avail);
}
template <class ...Args>
void emplace_back(Args &&...args) {
if (last == avail)
double_the_size();
alloc_traits::construct(*this, &ptr[last++], std::forward<Args>(args)...);
}
void double_the_size() {
if (__builtin_expect(!!(avail), true)) {
avail <<= 1;
ptr = alloc_traits::reallocate(*this, ptr, last, avail);
} else {
avail = 1 << 4;
ptr = alloc_traits::allocate(*this, avail);
}
}
};
template <class T>
static void BM_vector(benchmark::State &state) {
for(auto _: state) {
T c;
for(auto i = state.range(0); --i >= 0; )
c.emplace_back((char)i);
}
}
static constexpr const auto one_GB = 1 << 30;
BENCHMARK_TEMPLATE(BM_vector, vector<char>) ->Range(1 << 3, one_GB);
BENCHMARK_TEMPLATE(BM_vector, vector<char, mrealloc<char>>) ->Range(1 << 3, one_GB);
BENCHMARK_TEMPLATE(BM_vector, vector<char, mmaprealloc<char>>) ->Range(1 << 3, one_GB);
BENCHMARK_TEMPLATE(BM_vector, vector<char, mmaprealloc_populate_ver<char>>)->Range(1 << 3, one_GB);
BENCHMARK_MAIN();
- essai de Performance.
tous les essais de performance sont effectués sur:
Debian 9.4, Linux version 4.9.0-6-amd64 (debian-kernel@lists.debian.org)(gcc version 6.3.0 20170516 (Debian 6.3.0-18+deb9u1) ) #1 SMP Debian 4.9.82-1+deb9u3 (2018-03-02)
compilé en utilisant clang++ -std=c++17 -lbenchmark -lpthread -Ofast main.cc
la commande que j'ai utilisée pour exécuter ce test:
sudo cpupower frequency-set --governor performance
./a.out
Voici la sortie de Google benchmark test:
Run on (8 X 1600 MHz CPU s)
CPU Caches:
L1 Data 32K (x4)
L1 Instruction 32K (x4)
L2 Unified 256K (x4)
L3 Unified 6144K (x1)
----------------------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations
----------------------------------------------------------------------------------------------------------
BM_vector<vector<char>>/8 58 ns 58 ns 11476934
BM_vector<vector<char>>/64 324 ns 324 ns 2225396
BM_vector<vector<char>>/512 1527 ns 1527 ns 453629
BM_vector<vector<char>>/4096 7196 ns 7196 ns 96695
BM_vector<vector<char>>/32768 50145 ns 50140 ns 13655
BM_vector<vector<char>>/262144 549821 ns 549825 ns 1245
BM_vector<vector<char>>/2097152 5007342 ns 5006393 ns 146
BM_vector<vector<char>>/16777216 42873349 ns 42873462 ns 15
BM_vector<vector<char>>/134217728 336225619 ns 336097218 ns 2
BM_vector<vector<char>>/1073741824 2642934606 ns 2642803281 ns 1
BM_vector<vector<char, mrealloc<char>>>/8 55 ns 55 ns 12914365
BM_vector<vector<char, mrealloc<char>>>/64 266 ns 266 ns 2591225
BM_vector<vector<char, mrealloc<char>>>/512 1229 ns 1229 ns 567505
BM_vector<vector<char, mrealloc<char>>>/4096 6903 ns 6903 ns 102752
BM_vector<vector<char, mrealloc<char>>>/32768 48522 ns 48523 ns 14409
BM_vector<vector<char, mrealloc<char>>>/262144 399470 ns 399368 ns 1783
BM_vector<vector<char, mrealloc<char>>>/2097152 3048578 ns 3048619 ns 229
BM_vector<vector<char, mrealloc<char>>>/16777216 24426934 ns 24421774 ns 29
BM_vector<vector<char, mrealloc<char>>>/134217728 262355961 ns 262357084 ns 3
BM_vector<vector<char, mrealloc<char>>>/1073741824 2092577020 ns 2092317044 ns 1
BM_vector<vector<char, mmaprealloc<char>>>/8 4285 ns 4285 ns 161498
BM_vector<vector<char, mmaprealloc<char>>>/64 5485 ns 5485 ns 125375
BM_vector<vector<char, mmaprealloc<char>>>/512 8571 ns 8569 ns 80345
BM_vector<vector<char, mmaprealloc<char>>>/4096 24248 ns 24248 ns 28655
BM_vector<vector<char, mmaprealloc<char>>>/32768 165021 ns 165011 ns 4421
BM_vector<vector<char, mmaprealloc<char>>>/262144 1177041 ns 1177048 ns 557
BM_vector<vector<char, mmaprealloc<char>>>/2097152 9229860 ns 9230023 ns 74
BM_vector<vector<char, mmaprealloc<char>>>/16777216 75425704 ns 75426431 ns 9
BM_vector<vector<char, mmaprealloc<char>>>/134217728 607661012 ns 607662273 ns 1
BM_vector<vector<char, mmaprealloc<char>>>/1073741824 4871003928 ns 4870588050 ns 1
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/8 3956 ns 3956 ns 175037
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/64 5087 ns 5086 ns 133944
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/512 8662 ns 8662 ns 80579
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/4096 23883 ns 23883 ns 29265
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/32768 158374 ns 158376 ns 4444
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/262144 1171514 ns 1171522 ns 593
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/2097152 9297357 ns 9293770 ns 74
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/16777216 75140789 ns 75141057 ns 9
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/134217728 636359403 ns 636368640 ns 1
BM_vector<vector<char, mmaprealloc_populate_ver<char>>>/1073741824 4865103542 ns 4864582150 ns 1