Est-il problématique que Spring Data REST expose des entités via des ressources REST sans utiliser DTOs?
dans mon expérience limitée, on m'a dit à plusieurs reprises que vous ne devriez pas passer autour des entités à l'avant ou via le repos, mais plutôt d'utiliser un DTO.
Ne pas le Printemps de Données Reste à faire exactement cela? J'ai regardé brièvement dans les projections, mais celles-ci semblent limiter les données qui est retourné, et toujours en attendant une entité comme paramètre à une méthode de post pour sauver à la base de données. Est-ce que je manque quelque chose ici, ou est-ce que je (et mes collègues) incorrect en ce que vous ne devriez jamais passe autour et à l'entité?
3 réponses
tl;dr
Non. Les DTO ne sont qu'un moyen de découpler le modèle de domaine côté serveur de la représentation exposée dans les ressources HTTP. Vous pouvez également utiliser d'autres moyens de découplage, ce qui est ce que Spring Data REST fait.
Détails
Oui, le Printemps de Données RESTE inspecte le modèle de domaine que vous avez sur le côté serveur de la raison sur la façon dont les représentations pour les ressources qu'il expose. Toutefois, il applique un couple de concepts cruciaux que atténuer les problèmes un naïf exposition des objets du domaine.
Spring Data REST recherche des agrégats et forme par défaut les représentations en conséquence.
le problème fondamental avec le naïf "je jette mes objets de domaine devant Jackson" est que du modèle d'entité simple, il est très difficile de raisonner au sujet des limites de représentation raisonnables. Particulièrement les modèles d'entity dérivés des tables de base de données ont l'habitude de connecter pratiquement tout à tout. Cela découle du fait que des concepts de domaine importants comme les agrégats ne sont tout simplement pas présents dans la plupart des technologies de persistance (lire: surtout dans les bases de données relationnelles).
cependant, je dirais que dans ce cas le "N'exposez pas votre modèle de domaine" agit plus sur les symptômes de cela que le cœur du problème. Si vous concevez correctement votre modèle de domaine, il y a un chevauchement Énorme entre ce qui est bénéfique dans le modèle de domaine et ce à quoi ressemble une bonne représentation. pour conduire efficacement ce modèle à travers des changements d'état. Quelques règles simples:
- pour chaque relation avec une autre entité, demandez-vous: ne pourrait-il pas plutôt s'agir d'une référence d'identification? En utilisant une référence d'objet vous tirez beaucoup de sémantique de l'autre côté de la relation dans votre entité. Le fait de se tromper conduit généralement à des entités qui se réfèrent à des entités, ce qui est un problème à un niveau plus profond. Au niveau de la représentation cela vous permet de couper données, cadence, etc.
- évitez les relations bidirectionnelles car elles sont notoirement difficiles à mettre à jour.
Spring Data REST fait pas mal de choses pour transférer réellement ces relations d'entités dans les mécanismes appropriés au niveau HTTP: des liens en général et, plus important encore, des liens vers des ressources dédiées qui gèrent ces relations. Il le fait en inspectant les dépôts déclarés pour les entités et essentiellement remplace une introduction par ailleurs nécessaire de l'entité liée par un lien vers une ressource d'association qui vous permet de gérer cette relation de manière explicite.
cette approche joue généralement bien avec les garanties de cohérence décrites par les agrégats DDD au niveau HTTP. PUT les requêtes ne couvrent pas plusieurs agrégats par défaut, ce qui est une bonne chose car cela implique une cohérence de la ressource correspondant aux concepts de votre domaine.
Il n'y a pas forcer les utilisateurs à Otd si la DTO des copies les champs de l'objet du domaine.
vous pouvez introduire autant de DTOs pour vos objets de domaine que vous le souhaitez. Dans la plupart des cas, les champs capturé dans le domaine de l'objet se reflètent dans la représentation d'une certaine façon. Je n'ai pas encore de voir l'entité Customer contenant un firstname, lastname et emailAddress propriété, et ceux qui sont complètement hors de propos dans la représentation.
l'introduction des Dto ne garantit pas un découplage par aucun moyen. J'ai vu beaucoup trop de projets où ils ont été introduits pour des raisons de transport de fret, simplement dupliqué tous les champs de l'entité les soutenant et par cela a juste causé un effort supplémentaire parce que chaque nouveau champ a dû être ajouté au DTOs aussi bien. Mais bon, le découplage! Pas. \_(ツ)_/
cela dit, il y a bien sûr des situations où vous voudriez modifier légèrement la représentation de ces propriétés, surtout si vous utilisez fortement dactylographié valeur des objets pour par exemple un EmailAddress (bon!!!), mais encore envie de rendre ce simple String en JSON. Mais en aucun cas est - ce un problème: Spring Data REST utilise Jackson sous les couvertures qui vous offre une grande variété de moyens pour modifier la représentation-annotations, mixins pour garder les annotations en dehors de vos types de domaine, sérialiseurs personnalisés, etc. Il y a donc une couche cartographique entre les deux.
ne pas utiliser DTOs par défaut n'est pas une mauvaise chose en soi. Imaginez le tollé des utilisateurs sur la partie réutilisable nécessaire si nous avons exigé des Otd d'être écrit pour tout! Un DTO est juste signifie à une fin. Si cette fin peut être atteinte d'une manière différente (et elle le peut généralement), pourquoi insister sur les DTO?
il suffit de ne pas utiliser le repos de données de printemps où il ne correspond pas à vos exigences.
en continuant sur les efforts de personnalisation il vaut la peine de noter que le repos de données de ressort existe pour couvrir exactement les parties de L'API, qui suivent juste la base L'API REST de mise en œuvre de modèles qu'elle met en œuvre. Et cette fonctionnalité est en place pour vous donner plus de temps pour penser à
- comment façonner votre modèle de domaine
- quelles parties de votre API sont mieux exprimées par des interactions basées sur l'hypermédia.
voici une diapositive de L'exposé que J'ai donné à SpringOne Platform 2016 qui résume la situation.
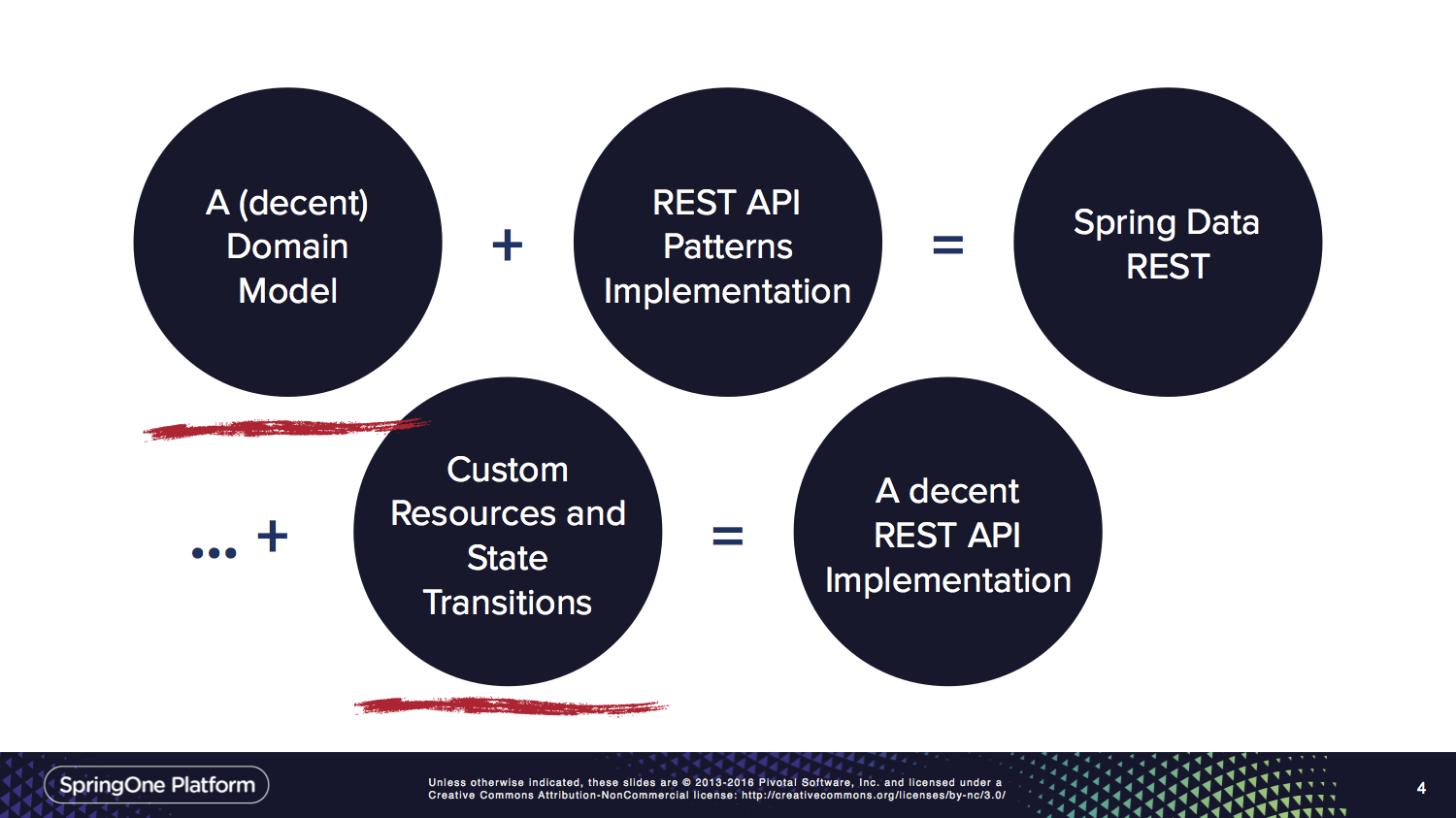
le diapo pont peut être trouvé ici. Il y a aussi un enregistrement de la conversation disponible sur InfoQ.
Spring Data REST existe pour que vous puissiez vous concentrer sur les cercles soulignés. En aucun cas nous ne pensons que vous pouvez construire une API vraiment grande uniquement en commutant les données de ressort reste sur. Nous voulons juste réduire la quantité de boilerplate pour vous d'avoir plus de temps pour penser aux bits intéressants.
comme les données du printemps en général réduit la quantité de code boilerplate à écrire pour les opérations standard de persistance. Personne ne prétendrait que vous pouvez réellement construire une application du monde réel à partir seulement des opérations CRUD. Mais en prenant l'effort hors des parties ennuyeuses, Nous vous permettons de réfléchir plus intensément sur les vrais défis de domaine (et vous devriez réellement le faire :)).
vous pouvez être très sélectif dans l'annulation de certaines ressources pour prendre complètement le contrôle de leur comportement, y compris la cartographie manuelle des types de domaines a DTOs si tu veux. Vous pouvez également placer la fonctionnalité personnalisée à côté de ce que le repos de données de ressort fournit et juste accrocher les deux ensemble. Être sélectif sur ce que vous utilisez.
un échantillon
vous pouvez trouver un exemple légèrement avancé de ce que j'ai décrit dans Spring RESTBucks, un Ressort (Données de REPOS) en fonction de la mise en œuvre de la RESTBucks exemple dans les Services Web RESTful livre. Il utilise le repos de données de printemps pour gérer Order cas des réglages de sa gestion à introduisez des exigences personnalisées et entièrement mettre en œuvre la partie de paiement de l'histoire manuellement.
Spring Data REST permet de créer très rapidement un prototype et une API REST basée sur une structure de base de données. Nous parlons de minutes par rapport à des jours, en comparant avec d'autres technologies de programmation.
le prix à payer pour cela, c'est que votre API REST est étroitement liée à la structure de votre base de données. Parfois, c'est un gros problème. Parfois, il n'est pas. Cela dépend essentiellement de la qualité de la conception de votre base de données et de votre capacité à la modifier en fonction de l'utilisateur de L'API. besoin.
en bref, je considère le repos de données de ressort comme un outil qui peut vous sauver beaucoup de temps dans certaines circonstances spéciales. Non pas comme une balle d'argent qui peut être appliquée à n'importe quel problème.
nous avions l'habitude d'utiliser des Dto incluant les couches entièrement traditionnelles ( base de données, DTO, dépôt, Service, contrôleurs,...) pour chaque entité dans nos projets. Sauter les DTO nous sauvera un jour la vie:)
Donc pour un simple City entité id,name,country,state nous avons fait comme ci-dessous:
Citytableauid,name,county,....colonnesCityDTOid,name,county,....propriétés ( exactement le même que la base de données)CityRepositoryavec unfindCity(id),....CityServicefindCity(id) { CityRepository.findCity(id) }CityControllerfindCity(id) { ConvertToJson( CityService.findCity(id)) }
trop de codes boilerplate juste pour exposer une information de ville au client. Comme il s'agit d'une entité simple, aucun commerce n'est fait tout au long de ces couches, seuls les objets passent.
Un changement de City entity commençait à partir de la base de données et changeait tous les calques. (Par exemple, en ajoutant un location propriété, bien parce qu'à la fin le location la propriété devrait être exposée à l'utilisateur as json). L'ajout d'un findByNameAndCountryAllIgnoringCase la méthode nécessite que toutes les couches soient changées ( chaque couche doit avoir une nouvelle méthode).
Compte Tenu Du Repos Des Données De Printemps ( of course with Spring Data) c'est plus simple!
public interface CityRepository extends CRUDRepository<City, Long> {
City findByNameAndCountryAllIgnoringCase(String name, String country);
}
city l'entité est exposée au client avec un code minimum et vous avez toujours le contrôle sur la façon dont la ville est exposée. Validation,Security,Object Mapping ... tout y est. De sorte que vous pouvez modifier chaque chose.
par exemple, si je veux que le client ne sache pas city changement de nom de propriété de l'entité (séparation des couches), je peux utiliser custom Object mapper mentionné https://docs.spring.io/spring-data/rest/docs/3.0.2.RELEASE/reference/html/#customizing-sdr.custom-jackson-deserialization
Pour résumer
nous utilisons les données de printemps repos autant que possible, dans les cas d'utilisation compliquée, nous pouvons encore aller à la stratification traditionnelle et laisser le Service et Controller faire quelques affaires.