Inline étiquettes dans Matplotlib
dans Matplotlib, il n'est pas trop difficile de faire une légende ( example_legend() , ci-dessous), mais je pense qu'il est préférable de mettre des étiquettes à droite sur les courbes tracées (comme dans example_inline() , ci-dessous). Cela peut être très délicat, parce que je dois spécifier les coordonnées à la main, et, si je re-formate le tracé, je dois probablement repositionner les étiquettes. Existe-t-il un moyen de générer automatiquement des étiquettes sur les courbes dans Matplotlib? Points Bonus pour pouvoir orienter le texte à un angle correspondant à la l'angle de la courbe.
import numpy as np
import matplotlib.pyplot as plt
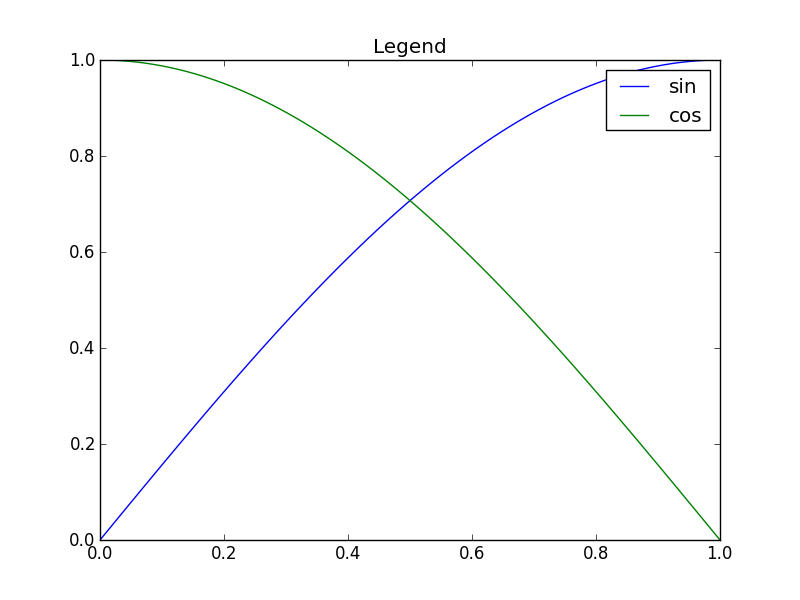
def example_legend():
plt.clf()
x = np.linspace(0, 1, 101)
y1 = np.sin(x * np.pi / 2)
y2 = np.cos(x * np.pi / 2)
plt.plot(x, y1, label='sin')
plt.plot(x, y2, label='cos')
plt.legend()
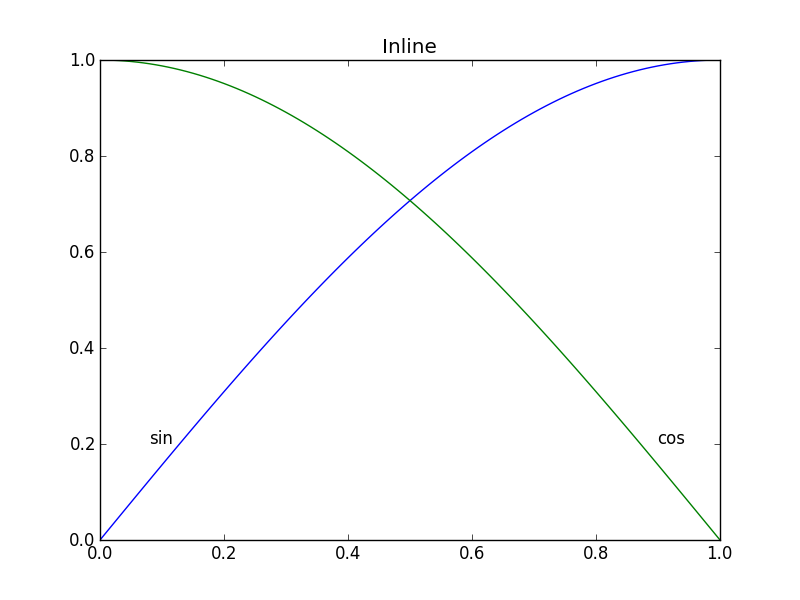
def example_inline():
plt.clf()
x = np.linspace(0, 1, 101)
y1 = np.sin(x * np.pi / 2)
y2 = np.cos(x * np.pi / 2)
plt.plot(x, y1, label='sin')
plt.plot(x, y2, label='cos')
plt.text(0.08, 0.2, 'sin')
plt.text(0.9, 0.2, 'cos')
3 réponses
bonne question, il y a un moment j'ai expérimenté un peu avec cela, mais je ne l'ai pas beaucoup utilisé parce que ce n'est toujours pas pare-balles. J'ai divisé la surface de la parcelle en une grille 32x32 et j'ai calculé un 'champ potentiel' pour la meilleure position d'une étiquette pour chaque ligne selon les règles suivantes:
- espace blanc est un bon endroit pour une étiquette L'étiquette
- doit être près de la ligne correspondante L'étiquette
- doit être éloignée de la d'autres lignes
le code était quelque chose comme ceci:
import matplotlib.pyplot as plt
import numpy as np
from scipy import ndimage
def my_legend(axis = None):
if axis == None:
axis = plt.gca()
N = 32
Nlines = len(axis.lines)
print Nlines
xmin, xmax = axis.get_xlim()
ymin, ymax = axis.get_ylim()
# the 'point of presence' matrix
pop = np.zeros((Nlines, N, N), dtype=np.float)
for l in range(Nlines):
# get xy data and scale it to the NxN squares
xy = axis.lines[l].get_xydata()
xy = (xy - [xmin,ymin]) / ([xmax-xmin, ymax-ymin]) * N
xy = xy.astype(np.int32)
# mask stuff outside plot
mask = (xy[:,0] >= 0) & (xy[:,0] < N) & (xy[:,1] >= 0) & (xy[:,1] < N)
xy = xy[mask]
# add to pop
for p in xy:
pop[l][tuple(p)] = 1.0
# find whitespace, nice place for labels
ws = 1.0 - (np.sum(pop, axis=0) > 0) * 1.0
# don't use the borders
ws[:,0] = 0
ws[:,N-1] = 0
ws[0,:] = 0
ws[N-1,:] = 0
# blur the pop's
for l in range(Nlines):
pop[l] = ndimage.gaussian_filter(pop[l], sigma=N/5)
for l in range(Nlines):
# positive weights for current line, negative weight for others....
w = -0.3 * np.ones(Nlines, dtype=np.float)
w[l] = 0.5
# calculate a field
p = ws + np.sum(w[:, np.newaxis, np.newaxis] * pop, axis=0)
plt.figure()
plt.imshow(p, interpolation='nearest')
plt.title(axis.lines[l].get_label())
pos = np.argmax(p) # note, argmax flattens the array first
best_x, best_y = (pos / N, pos % N)
x = xmin + (xmax-xmin) * best_x / N
y = ymin + (ymax-ymin) * best_y / N
axis.text(x, y, axis.lines[l].get_label(),
horizontalalignment='center',
verticalalignment='center')
plt.close('all')
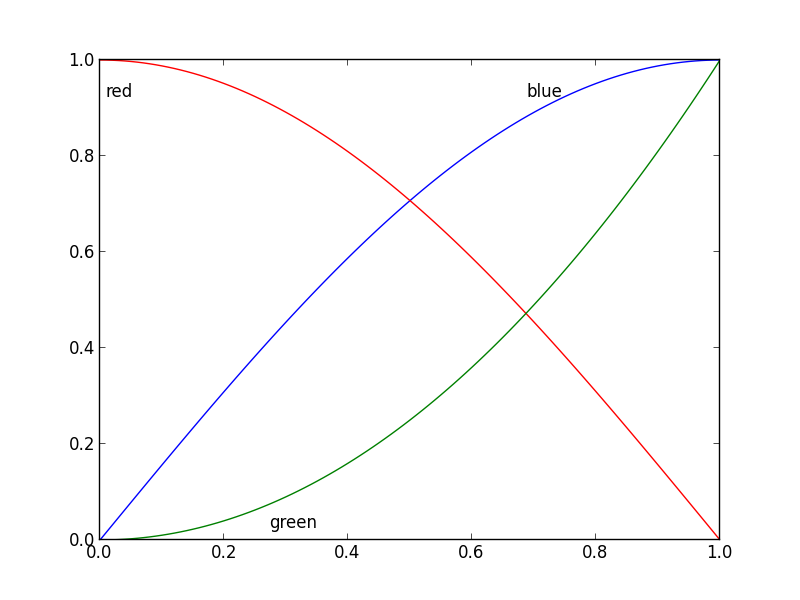
x = np.linspace(0, 1, 101)
y1 = np.sin(x * np.pi / 2)
y2 = np.cos(x * np.pi / 2)
y3 = x * x
plt.plot(x, y1, 'b', label='blue')
plt.plot(x, y2, 'r', label='red')
plt.plot(x, y3, 'g', label='green')
my_legend()
plt.show()
et la parcelle qui en résulte:
mise à jour: utilisateur cphyc a gentiment créé un dépôt Github pour le code dans cette réponse (voir ici ), et a regroupé le code dans un paquet qui peut être installé en utilisant pip install matplotlib-label-lines .
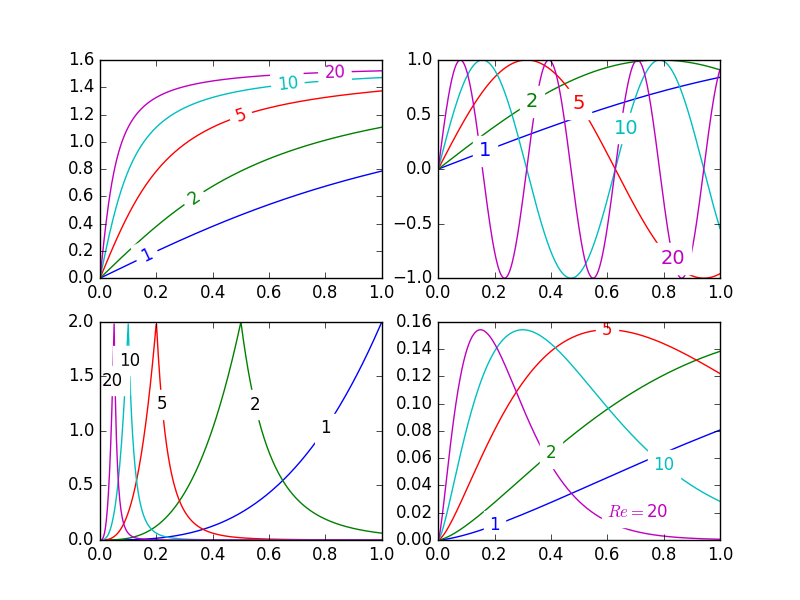
Belle Image:
Dans matplotlib c'est assez facile à tracés de contour d'étiquette (soit automatiquement ou en plaçant manuellement des étiquettes avec des clics de souris). Il ne semble pas (encore) y avoir de capacité équivalente pour étiqueter les séries de données de cette façon! Il peut y avoir une raison sémantique pour ne pas inclure cette caractéristique qui me manque.
quoi qu'il en soit, j'ai écrit le module suivant qui prend tout permet un étiquetage semi-automatique de parcelle. Il ne nécessite que numpy et quelques fonctions de la bibliothèque standard math .
Description
le comportement par défaut de la fonction labelLines est de placer les étiquettes uniformément le long de l'axe x (en plaçant automatiquement à la valeur correcte y - bien sûr). Si vous voulez, vous pouvez simplement passer un tableau des coordonnées x de chacune des étiquettes. Vous pouvez même modifier l'emplacement d'une étiquette (comme indiqué dans le graphique en bas à droite) et espacer le reste uniformément si vous le souhaitez.
de plus, la fonction label_lines ne tient pas compte des lignes qui n'ont pas d'étiquette assignée dans la commande plot (ou plus précisément si l'étiquette contient '_line' ).
les arguments de mots clés passés à labelLines ou labelLine sont transmis à l'appel de fonction text (certains arguments de mots clés sont définis si le code appelant choisit de ne pas spécifier).
Questions
- Annotation boundary boxes sometimes interfer undesirably with other curves. Comme le montrent les annotations
1et10en haut à gauche. Je ne suis même pas sûr que cela puisse être évité. - il serait bien de spécifier une position
yà la place parfois. - C'est toujours un processus itératif afin d'obtenir des annotations au bon endroit
- il ne fonctionne que lorsque le
x- axe les valeurs sontfloats
Pièges
- par défaut, la fonction
labelLinessuppose que toutes les séries de données couvrent la plage spécifiée par les limites des axes. Regardez la courbe bleue en haut à gauche de la jolie photo. S'il n'y avait que des données disponibles pour la gammex0.5-1, alors nous ne pourrions pas placer une étiquette à l'endroit désiré (qui est un peu moins que0.2). Voir cette question pour un exemple particulièrement désagréable. À l'heure actuelle, le code n'identifie pas intelligemment ce scénario et ne réarrange pas les étiquettes, mais il y a une solution de rechange raisonnable. La fonction labelLines prend l'argumentxvals; une liste dex- valeurs spécifiées par l'utilisateur au lieu de la distribution linéaire par défaut sur la largeur. Ainsi, l'utilisateur peut décider quellesx-valeurs à utiliser pour le placement de l'étiquette de chaque donnée série.
aussi, je crois que c'est la première réponse pour compléter le bonus objectif d'aligner les étiquettes avec la courbe qu'ils sont sur. :)
label_lines.py:
from math import atan2,degrees
import numpy as np
#Label line with line2D label data
def labelLine(line,x,label=None,align=True,**kwargs):
ax = line.axes
xdata = line.get_xdata()
ydata = line.get_ydata()
if (x < xdata[0]) or (x > xdata[-1]):
print('x label location is outside data range!')
return
#Find corresponding y co-ordinate and angle of the line
ip = 1
for i in range(len(xdata)):
if x < xdata[i]:
ip = i
break
y = ydata[ip-1] + (ydata[ip]-ydata[ip-1])*(x-xdata[ip-1])/(xdata[ip]-xdata[ip-1])
if not label:
label = line.get_label()
if align:
#Compute the slope
dx = xdata[ip] - xdata[ip-1]
dy = ydata[ip] - ydata[ip-1]
ang = degrees(atan2(dy,dx))
#Transform to screen co-ordinates
pt = np.array([x,y]).reshape((1,2))
trans_angle = ax.transData.transform_angles(np.array((ang,)),pt)[0]
else:
trans_angle = 0
#Set a bunch of keyword arguments
if 'color' not in kwargs:
kwargs['color'] = line.get_color()
if ('horizontalalignment' not in kwargs) and ('ha' not in kwargs):
kwargs['ha'] = 'center'
if ('verticalalignment' not in kwargs) and ('va' not in kwargs):
kwargs['va'] = 'center'
if 'backgroundcolor' not in kwargs:
kwargs['backgroundcolor'] = ax.get_facecolor()
if 'clip_on' not in kwargs:
kwargs['clip_on'] = True
if 'zorder' not in kwargs:
kwargs['zorder'] = 2.5
ax.text(x,y,label,rotation=trans_angle,**kwargs)
def labelLines(lines,align=True,xvals=None,**kwargs):
ax = lines[0].axes
labLines = []
labels = []
#Take only the lines which have labels other than the default ones
for line in lines:
label = line.get_label()
if "_line" not in label:
labLines.append(line)
labels.append(label)
if xvals is None:
xmin,xmax = ax.get_xlim()
xvals = np.linspace(xmin,xmax,len(labLines)+2)[1:-1]
for line,x,label in zip(labLines,xvals,labels):
labelLine(line,x,label,align,**kwargs)
code de Test pour générer la jolie image ci-dessus:
from matplotlib import pyplot as plt
from scipy.stats import loglaplace,chi2
from label_lines import *
X = np.linspace(0,1,500)
A = [1,2,5,10,20]
funcs = [np.arctan,np.sin,loglaplace(4).pdf,chi2(5).pdf]
plt.subplot(221)
for a in A:
plt.plot(X,np.arctan(a*X),label=str(a))
labelLines(plt.gca().get_lines(),zorder=2.5)
plt.subplot(222)
for a in A:
plt.plot(X,np.sin(a*X),label=str(a))
labelLines(plt.gca().get_lines(),align=False,fontsize=14)
plt.subplot(223)
for a in A:
plt.plot(X,loglaplace(4).pdf(a*X),label=str(a))
xvals = [0.8,0.55,0.22,0.104,0.045]
labelLines(plt.gca().get_lines(),align=False,xvals=xvals,color='k')
plt.subplot(224)
for a in A:
plt.plot(X,chi2(5).pdf(a*X),label=str(a))
lines = plt.gca().get_lines()
l1=lines[-1]
labelLine(l1,0.6,label=r'$Re=${}'.format(l1.get_label()),ha='left',va='bottom',align = False)
labelLines(lines[:-1],align=False)
plt.show()
la réponse de @Jan Kuiken est certainement réfléchie et complète, mais il y a quelques mises en garde:
- il ne fonctionne pas dans tous les cas
- cela nécessite une bonne quantité de code supplémentaire
- il peut varier considérablement d'une parcelle à l'autre
une approche beaucoup plus simple consiste à annoter le dernier point de chaque parcelle. Le point d'être encerclé, pour mettre l'accent. Ceci peut être accompli avec une ligne supplémentaire:
from matplotlib import pyplot as plt
for i, (x, y) in enumerate(samples):
plt.plot(x, y)
plt.text(x[-1], y[-1], 'sample {i}'.format(i=i))
une variante serait d'utiliser ax.annotate .