Dans CUDA, qu'est-ce que la mémoire fusionne, et comment est-elle réalisée?
Qu'est-ce que "coalesced" dans Cuda global memory transaction? Je ne pouvais pas comprendre même après avoir parcouru mon guide CUDA. Comment faire? Dans l'exemple de matrice de guide de programmation CUDA, l'accès à la matrice ligne par ligne est appelé "coalesced" ou col.. par le col.. est appelé coalisées? Ce qui est correct et pourquoi?
4 réponses
il est probable que cette information ne s'applique qu'au calcul de la capacité 1.x, ou Cuda 2.0. Les architectures plus récentes et cuda 3.0 ont un accès mémoire global plus sophistiqué et, en fait, les "charges globales coalescées" ne sont même pas profilées pour ces puces.
en outre, cette logique peut être appliquée à la mémoire partagée pour éviter les conflits bancaires.
Une transaction de mémoire coalescée est une transaction dans laquelle tous les threads d'une demi-chaîne accèdent à la mémoire globale en même temps. C'est trop simple, mais la bonne façon de le faire est simplement d'avoir des threads consécutifs accédant à des adresses mémoire consécutives.
Donc, si les threads 0, 1, 2 et 3 lisent la mémoire globale 0x0, 0x4, 0x8 et 0xc, il devrait s'agir d'une lecture coalescée.
Dans un exemple de matrice, gardez à l'esprit que vous voulez que votre matrice réside linéairement en mémoire. Vous pouvez le faire comme vous le souhaitez, et votre accès à la mémoire devrait refléter la façon dont votre matrice est disposée. Donc, la matrice 3x4 ci-dessous
0 1 2 3
4 5 6 7
8 9 a b
Pourrait être fait ligne après la ligne, comme ceci, de sorte que (r, c) correspond à la mémoire (r*4 + c)
0 1 2 3 4 5 6 7 8 9 a b
Supposons que vous ayez besoin d'accéder à l'élément une fois et que vous ayez quatre threads. Quels threads seront utilisés pour quel élément? Probablement soit
thread 0: 0, 1, 2
thread 1: 3, 4, 5
thread 2: 6, 7, 8
thread 3: 9, a, b
Ou
thread 0: 0, 4, 8
thread 1: 1, 5, 9
thread 2: 2, 6, a
thread 3: 3, 7, b
Quel est le meilleur? Qui se traduira par des lectures coalescées, et qui ne le sera pas?
De toute façon, chaque thread fait trois accès. Regardons le premier accès et voyons si les threads accèdent à la mémoire consécutivement. Dans la première option, le premier l'accès est 0, 3, 6, 9. Pas consécutif, pas fusionné. La deuxième option, c'est 0, 1, 2, 3. Consécutives! Fusionné! Yay!!!
Le meilleur moyen est probablement d'écrire votre noyau, puis de le profiler pour voir si vous avez des charges et des magasins globaux Non coalescés.
La coalescence de mémoire est une technique qui permet une utilisation optimale de la bande passante mémoire globale. C'est-à-dire que lorsque des threads parallèles exécutent le même accès d'instruction à des emplacements consécutifs dans la mémoire globale, le modèle d'accès le plus favorable est atteint.
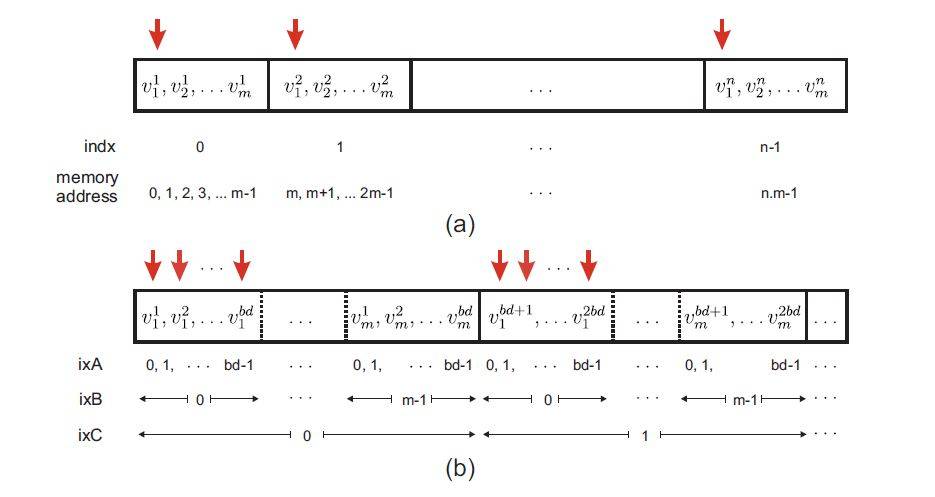
L'exemple de la Figure ci-dessus aide à expliquer l'arrangement coalescé:
Sur La Fig. (a), n de vecteurs de longueur m sont stockés dans un mode linéaire. Élément i du vecteur j est noté v jj'. Chaque thread du noyau GPU est affecté à un vecteurM -length. Les Threads dans CUDA sont regroupés dans un tableau de blocs et chaque thread dans GPU a un id unique qui peut être défini comme indx=bd*bx+tx, où bd représente la dimension du bloc, bx désigne l'index du bloc et tx est l'index du thread dans chaque bloc.
Les flèches verticales démontrent le cas où les fils parallèles accèdent aux premiers composants de chaque vecteur, c'est à dire les adresses 0, m, 2m... de la mémoire. Comme indiqué dans la Fig. (a), dans ce cas, l'accès à la mémoire n'est pas consécutive. En réduisant à zéro l'écart entre ces adresses (flèches rouges montrées dans la figure ci-dessus), l'accès à la mémoire devient coalescé.
Cependant, le problème devient légèrement délicat ici, puisque la taille autorisée des threads résidant par bloc GPU est limitée à bd. Par conséquent l'arrangement de données coalescé peut être fait en stockant les premiers éléments du premier bd vecteurs dans l'ordre consécutif, suivi des premiers éléments des seconds vecteurs bd et ainsi de suite. Le reste des éléments vecteurs sont stockés d'une manière similaire, comme le montre la Fig. (b). Si n (Nombre de vecteurs) n'est pas un facteur de bd, Il est nécessaire de remplir les données restantes dans le dernier bloc avec une valeur triviale, par exemple 0.
Dans le stockage de données linéaire de la Fig. (a), de la composante je (0 ≤ j' m) de vecteur indx
(0 ≤ indx n) est adressée par m × indx +i; le même composant dans le conflué
motif de stockage dans la Fig. (b) est traitée comme
(m × bd) ixC + bd × ixB + ixA,
Où ixC = floor[(m.indx + j )/(m.bd)]= bx, ixB = j et ixA = mod(indx,bd) = tx.
En résumé, dans l'exemple de stockage d'un certain nombre de vecteurs de taille m , l'indexation linéaire est mappée à l'indexation coalescée selon:
m.indx +i −→ m.bd.bx +i .bd +tx
Ce réarrangement des données peut conduire à une bande passante mémoire importante plus élevée de la mémoire globale GPU.
Source: "basées sur le processeur d'accélération des calculs en éléments finis non-linéaires analyse de déformation."Revue internationale de méthodes numériques en génie biomédical (2013).
Si les threads d'un bloc accèdent à des emplacements de mémoire globaux consécutifs, tous les accès sont combinés en une seule requête(ou coalescés) par le matériel. Dans l'exemple de matrice, les éléments de matrice dans la rangée sont disposés linéairement, suivis de la rangée suivante, et ainsi de suite. Pour par exemple une matrice 2x2 et 2 threads dans un bloc, les emplacements de mémoire sont disposés comme suit:
(0,0) (0,1) (1,0) (1,1)
Dans l'accès à la ligne, thread1 accède (0,0) et (1,0) qui ne peuvent pas être coalescés. Dans la colonne de l'accès, thread1 accès (0,0) et (0,1) qui peuvent être coalescés parce qu'ils sont adjacents.
Les critères de coalescence sont bien documentés dans le Cuda 3.2 Programming Guide , Section G. 3. 2. La version courte est la suivante: les threads dans la chaîne doivent accéder à la mémoire en séquence, et les mots accessibles doivent > = 32 bits. De plus, l'adresse de base à laquelle la chaîne accède doit être alignée sur 64, 128 ou 256 octets pour les accès 32, 64 et 128 bits, respectivement.
Le matériel Tesla2 et Fermi fait un bon travail de coalescence 8 et 16 bits accès, mais ils sont mieux évités si vous voulez une bande passante de pointe.
Notez que malgré les améliorations apportées au matériel Tesla2 et Fermi, la coalescence N'est en aucun cas obsolète. Même sur le matériel de classe Tesla2 ou Fermi, ne pas fusionner les transactions de mémoire globale peut entraîner une performance 2x. (Sur le matériel de classe Fermi, cela semble être vrai uniquement lorsque ECC est activé. Les transactions de mémoire contiguës mais non coalisées prennent environ 20% sur Fermi.)