Implémentation de BlockingQueue: quelles sont les différences entre Synchrousqueue et LinkedBlockingQueue
Je vois ces implémentations de BlockingQueue et je ne peux pas comprendre les différences entre eux. Ma conclusion jusqu'à présent:
- Je n'aurai jamais besoin de Synchronequeue
- LinkedBlockingQueue assure FIFO, BlockingQueue doit être créé avec le paramètre true pour faire FIFO
- Synchronequeue casse la plupart des méthodes de collections (contient, taille, etc.)
Alors, quand ai-je besoin de Synchronequeue ? Est le les performances de cette implémentation sont meilleures que LinkedBlockingQueue ?
Pour le rendre plus compliqué... pourquoi exécuteurs.newCachedThreadPool utilise Synchrousqueue lorsque les autres (exécuteurs.newSingleThreadExecutor et exécuteurs.newFixedThreadPool) utiliser LinkedBlockingQueue?
MODIFIER
La première question est résolue. Mais je ne comprends toujours pas pourquoi les exécuteurs .newCachedThreadPool utiliser Synchronequeue lorsque les autres (exécuteurs.newSingleThreadExecutor et exécuteurs.newFixedThreadPool) utiliser LinkedBlockingQueue?
Ce que je reçois est, avec Synchrousqueue, le producteur sera bloqué s'il n'y a pas de thread libre. Mais puisque le nombre de threads est pratiquement illimité (de nouveaux threads seront créés si nécessaire), cela n'arrivera jamais. Alors, pourquoi devrait-il utiliser Synchronequeue?
3 réponses
SynchronousQueue est un type de file d'attente très spécial-il implémente une approche de rendez-vous (le producteur attend que le consommateur soit prêt, le consommateur attend que le producteur soit prêt) derrière l'interface de Queue.
Par conséquent, vous pouvez en avoir besoin uniquement dans les cas particuliers lorsque vous avez besoin de cette sémantique particulière, par exemple, threading unique d'une tâche sans mettre en file d'attente d'autres demandes.
Une autre raison d'utiliser SynchronousQueue est la performance. La mise en œuvre de SynchronousQueue semble être fortement optimisé, donc si vous n'avez besoin de rien de plus qu'un point de rendez-vous (comme dans le cas de Executors.newCachedThreadPool(), où les consommateurs sont créés "à la demande", de sorte que les éléments de file d'attente ne s'accumulent pas), vous pouvez obtenir un gain de performance en utilisant SynchronousQueue.
Un test synthétique simple montre que dans un scénario simple producteur-consommateur unique sur une machine dual-core, le débit de SynchronousQueue est ~20 fois plus élevé que le débit de LinkedBlockingQueue et ArrayBlockingQueue avec une longueur de file d'attente = 1. Lorsque la longueur de la file d'attente est augmentée, leur débit augmente et atteint presque le débit de SynchronousQueue. Cela signifie que SynchronousQueue a une faible surcharge de synchronisation sur les machines multi-cœurs par rapport aux autres Files d'attente. Mais encore une fois, cela n'a d'importance que dans des circonstances spécifiques lorsque vous avez besoin d'un point de rendez-vous déguisé en Queue.
Modifier:
Voici un test:
public class Test {
static ExecutorService e = Executors.newFixedThreadPool(2);
static int N = 1000000;
public static void main(String[] args) throws Exception {
for (int i = 0; i < 10; i++) {
int length = (i == 0) ? 1 : i * 5;
System.out.print(length + "\t");
System.out.print(doTest(new LinkedBlockingQueue<Integer>(length), N) + "\t");
System.out.print(doTest(new ArrayBlockingQueue<Integer>(length), N) + "\t");
System.out.print(doTest(new SynchronousQueue<Integer>(), N));
System.out.println();
}
e.shutdown();
}
private static long doTest(final BlockingQueue<Integer> q, final int n) throws Exception {
long t = System.nanoTime();
e.submit(new Runnable() {
public void run() {
for (int i = 0; i < n; i++)
try { q.put(i); } catch (InterruptedException ex) {}
}
});
Long r = e.submit(new Callable<Long>() {
public Long call() {
long sum = 0;
for (int i = 0; i < n; i++)
try { sum += q.take(); } catch (InterruptedException ex) {}
return sum;
}
}).get();
t = System.nanoTime() - t;
return (long)(1000000000.0 * N / t); // Throughput, items/sec
}
}
Et voici un résultat sur ma machine:
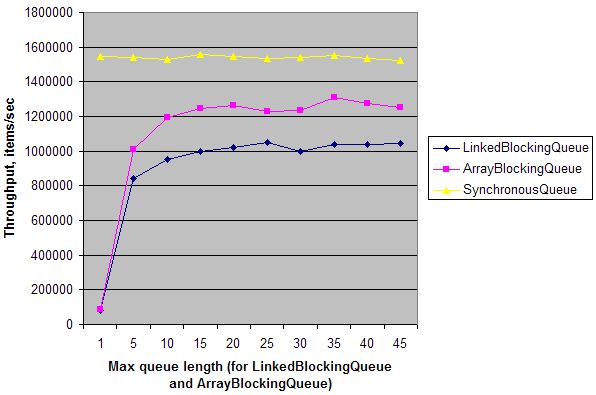
Actuellement la valeur par défaut Executors (ThreadPoolExecutor basé) peut soit utiliser un ensemble de threads pré-créés d'une taille fixe et un BlockingQueue d'une certaine taille pour tout débordement ou créer des threads jusqu'à une taille maximale si (et seulement si) cette file d'attente est pleine.
Cela conduit à des propriétés surprenantes. Par exemple, comme les threads supplémentaires ne sont créés qu'une fois la capacité de la file d'attente atteinte, l'utilisation d'un LinkedBlockingQueue (qui est illimité) signifie que les nouveaux threads ne seront jamais créés, même si la taille du pool actuel est zéro. Si vous utilisez un ArrayBlockingQueue, les nouveaux threads ne sont créés que s'ils sont pleins, et il y a une probabilité raisonnable que les travaux suivants soient rejetés si le pool n'a pas effacé d'espace d'ici là.
Un SynchronousQueue ayant une capacité nulle, un producteur bloque jusqu'à ce qu'un consommateur soit disponible ou qu'un thread soit créé. Cela signifie que malgré les chiffres impressionnants produits par @ axtavt, un pool de threads mis en cache a généralement les pires performances du point de vue du producteur vue.
Malheureusement, il n'y a pas actuellement une belle version de bibliothèque d'une implémentation de compromis qui créera des threads pendant les rafales ou l'activité jusqu'à un maximum à partir d'un minimum bas. Vous avez soit une piscine cultivable ou fixe. Nous en avons un en interne, mais il n'est pas encore prêt pour la consommation publique.
Le pool de threads du cache crée des threads à la demande. Il a besoin d'une file d'attente qui passe la tâche à un consommateur en attente ou échoue. S'il n'y a pas de consommateur en attente, il crée un nouveau thread. Synchronequeue ne contient pas d'élément, il passe l'élément ou échoue.