Si Python est interprété, que sont-ils?dossiers pyc?
9 réponses
ils contiennent byte code , qui est ce à quoi l'interpréteur Python compile le source. Ce code est ensuite exécuté par la machine virtuelle de Python.
la documentation de Python explique la définition comme ceci:
Python est un langage interprété, comme contrairement à un compilé, bien que les la distinction peut être floue en raison de la présence du compilateur de bytecode. Cela signifie que les fichiers sources peut être exécuter directement, sans explicitement créer un exécutable qui est alors exécuter.
il m'a été donné de comprendre que Python est un langage interprété...
ce mème populaire est incorrect, ou, plutôt, construit sur une incompréhension des niveaux (naturels) de langue: une erreur similaire serait de dire "la Bible est un livre à couverture dure". Laissez-moi expliquer que similé...
"La Bible" est "un livre", dans le sens de être un classe (réelle, physique des objets identifiés comme) livres; les livres identifiés comme "copies de la Bible" sont censés avoir quelque chose de fondamental en commun ( le contenu, bien que même ceux-ci peuvent être dans des langues différentes, avec des traductions acceptables Différentes, des niveaux de notes de bas de page et d'autres annotations) -- cependant, ces livres sont parfaitement bien autorisés à différer dans une myriade d'aspects qui sont pas considéré comme fondamental -- type de reliure, couleur de reliure, police(s) utilisée (s) dans l'impression, illustrations, s'il y en a, larges marges d'écriture ou non, nombres et genres de signets, etc., etc.
il est tout à fait possible qu'une typique impression de la Bible serait en effet en Reliure hardcover -- après tout, c'est un livre qui est généralement destiné à être lu encore et encore, signalisé à plusieurs endroits, le pouce à travers la recherche des indicateurs de chapitre et de vers, etc, etc, et une bonne Reliure hardcover peut faire une copie donnée en dernier plus longtemps sous une telle utilisation. Cependant, il s'agit de questions (pratiques) banales qui ne peuvent pas être utilisées pour déterminer si un objet de livre donné est une copie de la Bible ou non: les impressions papier sont parfaitement possibles!
de même, Python est "un langage" dans le sens de définir une classe de langage implémentations qui doivent tous être similaires à certains égards fondamentaux (syntaxe, la plupart sémantique à l'exception des parties de ces quand ils sont explicitement autorisés à différer) mais sont entièrement autorisés à différer dans à peu près chaque détail "d'implémentation" -- y compris la façon dont ils traitent les fichiers source qu'ils reçoivent, s'ils compilent les sources à des formes de niveau inférieur (et, si oui, quelle forme -- et s'ils sauvegardent ces formes compilées, sur disque ou ailleurs), comment ils exécutent ces formes, et ainsi de suite.
L'implémentation classique, CPython, est souvent appelée simplement "Python" pour faire court -- mais c'est il s'agit de l'une des nombreuses implémentations de qualité de production, à côté de L'IronPython de Microsoft (qui compile vers les codes CLR, par exemple ".NET"), Jython (qui compile vers les codes JVM), PyPy (qui est écrit en Python lui-même et peut compiler vers une grande variété de formes "back-end" incluant le langage machine généré "just-in-time"). Ils sont tous Python (=="implémentations du langage Python") tout comme beaucoup d'objets de livres superficiellement différents peuvent tous être des Bibles (=="copies de la Bible").
si vous êtes intéressé par CPython en particulier: il compile les fichiers source dans une forme de niveau inférieur spécifique à Python (connu sous le nom de" bytecode"), le fait automatiquement lorsqu'il est nécessaire (quand il n'y a pas de fichier bytecode correspondant à un fichier source, ou le fichier bytecode est plus ancien que la source ou compilé par une version Python différente), sauve habituellement les fichiers bytecode sur le disque (pour éviter de les recompiler dans le futur). OTOH IronPython compilera généralement les codes CLR (sauvegarde les sauvegarder sur le disque ou pas, selon) Et Jython aux codes JVM (les sauvegarder sur le disque ou pas -- il utilisera l'extension .class si elle les sauve).
ces formulaires de niveau inférieur sont ensuite exécutés par des" machines virtuelles "appropriées également appelées" interprètes " -- la VM de CPython, L'exécution .Net, la VM Java (alias JVM), selon le cas.
donc, dans ce sens (que font les implémentations typiques), Python est un "langage interprété" si et seulement si C# et Java sont: tous ont une stratégie de mise en œuvre typique de produire bytecode d'abord, puis l'exécuter via un VM/interpréteur.
plus probablement, l'accent est mis sur la façon" lourde", lente, et haute cérémonie le processus de compilation est. CPython est conçu pour compiler aussi vite que possible, aussi léger que possible, avec aussi peu de cérémonie que possible -- le compilateur fait très peu de vérification et d'optimisation des erreurs, de sorte qu'il peut fonctionner rapidement et en petites quantités de mémoire, qui à son tour permet d'exécuter automatiquement et de manière transparente à chaque fois que nécessaire, sans même avoir besoin d'avoir conscience qu'il s'agit d'une compilation en cours, la plupart du temps. Java et C# acceptent généralement plus de travail lors de la compilation (et donc n'effectuent pas de compilation automatique) afin de vérifier les erreurs plus complètement et effectuer plus d'optimisations. C'est un continuum de niveaux de gris, pas noir ou blanc, et il serait totalement arbitraire de mettre un seuil à un certain niveau donné et dire que seulement au-dessus de ce niveau, vous l'appelez "compilation"!- )
il n'existe pas de langage interprété. Que l'on utilise un interpréteur ou un compilateur est purement un trait du implementation et n'a absolument rien à voir avec le langage.
chaque langue peut être implémentée par un interpréteur ou un compilateur. La grande majorité des langues ont au moins une mise en œuvre de chaque type. (Par exemple, il y a des interprètes pour C et c++ et il existe des compilateurs pour JavaScript, PHP, Perl, Python et Ruby. En outre, la majorité des implémentations de langues modernes combinent en fait à la fois un interpréteur et un compilateur (ou même plusieurs compilateurs).
un langage n'est qu'un ensemble de règles mathématiques abstraites. Un interprète est l'une des stratégies concrètes de mise en œuvre d'une langue. Ces deux-là vivent sur des niveaux d'abstraction complètement différents. Si les anglais ont tapé la langue, le terme "langage interprété" serait une erreur de type. L'affirmation " Python est un langage interprété "n'est pas seulement fausse (parce qu'être fausse signifierait que l'affirmation a même du sens, même si elle est fausse), elle ne fait simplement pas sens , parce qu'un langage peut jamais être défini comme" interprété."
en particulier, si vous regardez les implémentations Python existantes, ce sont les stratégies d'implémentation qu'ils utilisent:
- IronPython: compile à DLR arbres qui le DLR compile puis à CIL bytecode. Ce qui arrive au bytecode CIL dépend des clients sur lesquels vous lancez, mais Microsoft .NET, GNU Portable.NET et Novell Mono finira par le compiler en code machine natif.
- Jython: interprète le code source de Python jusqu'à ce qu'il identifie les chemins de code chauds, qu'il compile ensuite pour jvml bytecode. Ce qu'il advient du bytecode JVML dépend de quel JVM vous êtes en cours d'exécution sur. Maxine le compilera directement en code natif non optimisé jusqu'à ce qu'il identifie les chemins de code chauds, qu'il recompile ensuite en code natif optimisé. HotSpot interprétera d'abord le bytecode JVML, puis compilera éventuellement les chemins de code chauds vers le code machine optimisé.
- PyPy: compile de PyPy bytecode, qui est ensuite interprété par la PyPy VM jusqu'à ce qu'il identifie le chaud chemins de code qui compile en code natif, JVML bytecode ou CIL bytecode selon la plateforme que vous exécutez sur.
- Disponible: compile Disponible bytecode qui l'interprète.
- Stackless Python: compile Disponible bytecode qui l'interprète.
- Unladen Swallow: compile Disponible bytecode qui l'interprète jusqu'à ce qu'il identifie le chaud chemins de code qui compile à l'IR LLVM qui le compilateur LLVM ensuite compilé en code machine natif.
vous pourriez remarquer que chacune des implémentations dans cette liste (plus certaines autres que je n'ai pas mentionnées, comme tinypy, Shedskin ou Psyco) a un compilateur. En fait, pour autant que je sache, il n'y a actuellement pas D'implémentation Python qui soit purement interprétée, il n'y a pas d'implémentation prévue et il n'y a jamais eu d'implémentation.
non seulement le terme "langue interprétée" n'a pas de sens, même si vous l'interprétez comme signifiant "la langue avec interprété mise en œuvre", c'est clairement pas le cas. Celui qui vous a dit ça ne sait évidemment pas de quoi il parle.
en particulier, les fichiers .pyc que vous voyez sont mis en cache par des fichiers de code Produits par CPython, Python Stackless ou unladen Swallow.
ceux-ci sont créés par l'interpréteur Python lorsqu'un fichier .py est importé, et ils contiennent le" bytecode compilé "du module/programme importé, l'idée étant que la" traduction "du code source au bytecode (qui ne doit être faite qu'une seule fois) peut être sautée sur les import S suivants si le .pyc est plus récent que le fichier .py correspondant, ce qui accélère un peu le démarrage. Mais c'est toujours interprété.
C'EST POUR LES DÉBUTANTS,
Python compile automatiquement votre script en code compilé, appelé code octet, avant de l'exécuter.
exécuter un script n'est pas considéré comme une importation et no .pyc sera créé.
par exemple, si vous avez un fichier de script abc.py qui importe un autre module xyz.py , quand vous lancez abc.py , xyz.pyc sera créé puisque xyz est importé, mais pas abc.le fichier pyc sera créé depuis abc.py n'est pas importé.
Si vous avez besoin de créer un .fichier pyc pour un module qui n'est pas importé, vous pouvez utiliser les modules py_compile et compileall .
le module py_compile peut compiler manuellement n'importe quel module. Une façon est d'utiliser la fonction py_compile.compile dans ce module de manière interactive:
>>> import py_compile
>>> py_compile.compile('abc.py')
ceci écrira le .pyc au même emplacement que abc.py (vous pouvez remplacer qu'avec le paramètre facultatif cfile ).
vous pouvez également compiler automatiquement tous les fichiers dans un répertoire ou des répertoires en utilisant le module compileall.
python -m compileall
si le nom du répertoire (le répertoire courant dans cet exemple) est omis, le module compile tout ce qui se trouve sur sys.path
pour accélérer le chargement des modules, Python cache le contenu compilé des modules .pyc.
CPython compile son code source en "byte code", et pour des raisons de performance, il cache ce code byte sur le système de fichiers à chaque fois que le fichier source change. Cela rend le chargement des modules Python beaucoup plus rapide car la phase de compilation peut être contournée. Lorsque votre fichier source est foo.py , CPython cache le code octet dans un foo.fichier pyc juste à côté de la source.
en python3, la machine d'importation de Python est étendue pour écrire et rechercher des fichiers de cache de code octet dans un seul répertoire à l'intérieur de chaque répertoire de paquets Python. Ce répertoire s'appellera _ _ pycache__.
voici un organigramme décrivant la façon dont les modules sont chargés:
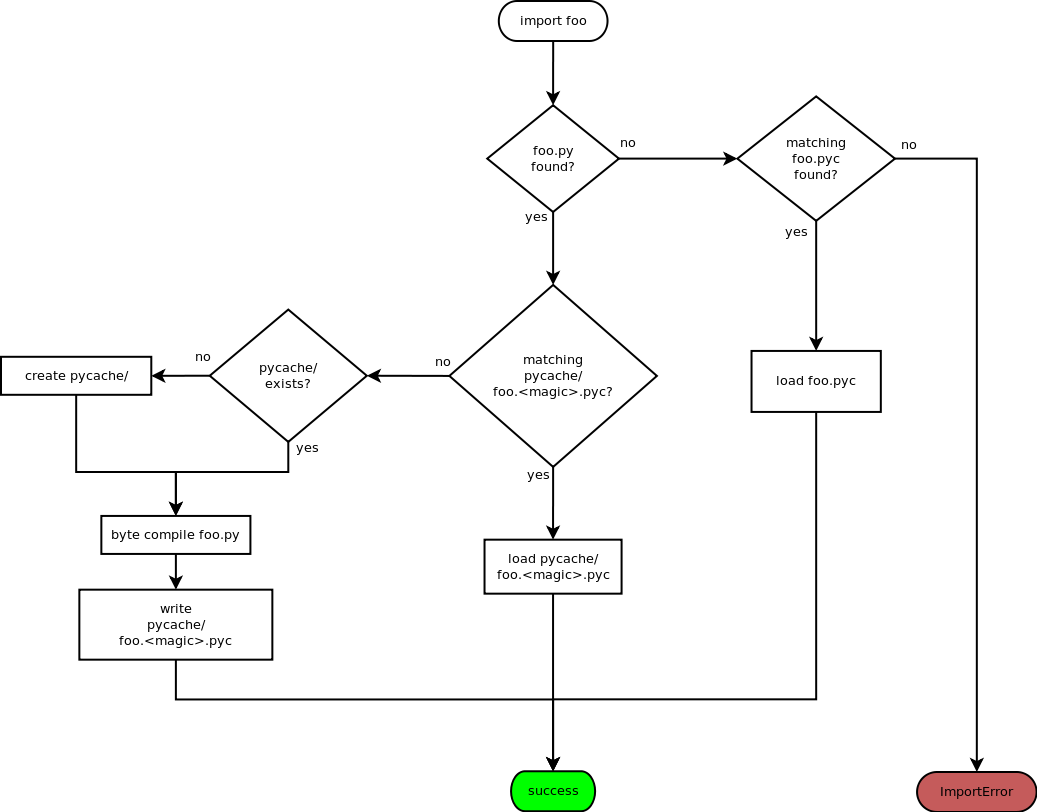
pour plus d'informations:
ref: PEP3147
ref: "Compilé" fichiers Python
Python (au moins l'implémentation la plus courante de celui-ci) suit un modèle de compilation de la source originale aux codes octets, puis d'interprétation des codes octets sur une machine virtuelle. Cela signifie (Encore une fois, l'implémentation la plus commune) n'est ni un interpréteur pur ni un compilateur pur.
l'autre côté de ceci est, cependant, que le processus de compilation est la plupart du temps caché -- le .les fichiers pyc sont essentiellement traités comme un cache; ils accélèrent les choses, mais vous normalement ne pas être au courant d'entre eux. Il les invalide et les recharge automatiquement (recompile le code source) si nécessaire en fonction de l'Heure/Date du fichier.
à propos de la seule fois où j'ai vu un problème avec ceci était quand un fichier compilé bytecode a d'une manière ou d'une autre obtenu une estampille de temps bien dans le futur, ce qui signifie qu'il a toujours semblé plus récent que le fichier source. Comme il avait l'air plus récent, le fichier source n'a jamais été recompilé, donc peu importe les changements que vous avez faits, ils ont été ignorés...
Python *.py fichier est juste un fichier texte dans lequel vous écrire quelques lignes de code. Lorsque vous essayez d'exécuter ce fichier en utilisant say "python filename.py "
cette commande invoque la Machine virtuelle Python. La Machine virtuelle Python a 2 composants:" compilateur "et"interpréteur". L'interprète ne peut pas lire directement le texte en *.fichier py, donc ce texte est d'abord converti en un code octet qui est ciblé sur le PVM (pas matériel mais PVM) . PVM exécute ce code octet. *.le fichier pyc est également généré, dans le cadre de son exécution qui effectue votre opération d'importation sur le fichier dans shell ou dans un autre fichier.
Si ce *.le fichier pyc est déjà généré puis chaque fois que vous exécutez/exécutez votre *.fichier py, le système charge directement votre *.fichier pyc qui n'a besoin d'aucune compilation(cela vous sauvera quelques cycles machine du processeur).
une Fois que l' *.le fichier pyc est généré, pas besoin de *.fichier py, sauf si vous modifiez il.
code Python passe par 2 étapes. Première étape compile le code dans .fichiers pyc qui est en fait un bytecode. Alors ce .le fichier pyc (bytecode) est interprété en utilisant l'interpréteur de CPython. Veuillez vous référer au lien this . Ici, le processus de compilation et d'exécution est expliqué en termes faciles.