Comment utiliser le gradient de butée dans Tensorflow
je me demande comment utiliser stop_gradient dans tensorflow, et la documentation n'est pas claire pour moi.
j'utilise actuellement stop_gradient pour produire le gradient de la fonction de perte W. R. T. le mot embeddings dans un modèle CBOW word2vec. Je veux juste obtenir la valeur, et de ne pas faire la rétropagation (comme je génère des exemples de confrontation).
actuellement, j'utilise le code:
lossGrad = gradients.gradients(loss, embed)[0]
real_grad = lossGrad.eval(feed_dict)
mais quand j'exécute ceci, il fait la rétropogation de toute façon! Ce que je fais mal, et tout aussi important, comment puis-je résoudre ce problème?
CLARIFICATION: pour clarifier par " rétropropagation "j'entends"calcul des valeurs et mise à jour des paramètres du modèle".
UPDATE
si je cours les deux lignes ci-dessus après la première étape d'entraînement, j'obtiens une perte différente après 100 étapes d'entraînement que lorsque je ne Cours pas ces deux lignes. J'ai peut-être fondamentalement malentendu quelque chose à propos de Tensorflow.
j'ai essayé d'utiliser set_random_seed tant au début de la déclaration graphique qu'avant chaque étape de formation. La perte totale est cohérente entre les passages multiples, mais pas entre l'inclusion/l'exclusion de ces deux lignes. Donc, si ce n'est pas le RNG qui cause la disparité, et ce n'est pas une mise à jour imprévue des paramètres du modèle entre les étapes de formation, avez-vous une idée de ce qui causerait ce comportement?
SOLUTION
Welp, c'est un peu en retard, mais voici comment je l'ai résolu. Je voulais seulement optimiser certaines variables, mais pas toutes. J'ai pensé que la façon de prévenir l'optimisation de certaines variables serait d'utiliser stop_grad - mais je n'ai jamais trouvé un moyen de faire ce travail. Peut-être qu'il y a un moyen, mais ce qui a fonctionné pour moi était d'ajuster mon optimizer pour optimiser sur une liste de variables. Donc au lieu de:
opt = tf.train.GradientDescentOptimizer(learning_rate=eta)
train_op = opt.minimize(loss)
j'ai utilisé:
opt = tf.train.GradientDescentOptimizer(learning_rate=eta)
train_op = opt.minimize(loss, var_list=[variables to optimize over])
Ce qui a empêché opt mise à jour des variables qui ne sont pas dans var_list. Espérons-le cela fonctionne pour vous aussi!
2 réponses
tf.stop_gradient fournit un moyen de ne pas calculer le gradient par rapport à certaines variables lors de la rétro-propagation.
par exemple, dans le code ci-dessous, nous avons trois variables, w1, w2, w3 et input X. La perte est carrée ((x1.dot (w1) - X. dot (w2 * w3)). Nous voulons minimiser cette perte wrt à w1 mais voulons garder W2 et w3 fixes. Pour ce faire, nous pouvons simplement mettre tf.stop_gradient (tf.matmul (x, w2*w3)).
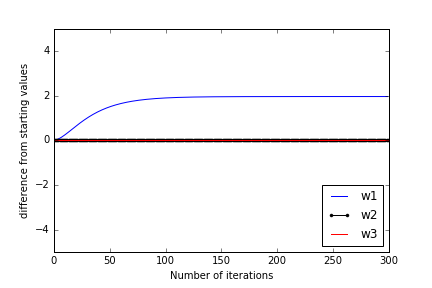
dans la figure ci-dessous, j'ai tracé comment w1, w2, et w3 de leur valeurs initiales en fonction des itérations de formation. On voit que w2 et w3 restent fixes tandis que w1 change jusqu'à ce qu'il devienne égal à w2 * w3.
Une image montrant que w1 seulement apprend, mais pas w2 et w3:
import tensorflow as tf
import numpy as np
w1 = tf.get_variable("w1", shape=[5, 1], initializer=tf.truncated_normal_initializer())
w2 = tf.get_variable("w2", shape=[5, 1], initializer=tf.truncated_normal_initializer())
w3 = tf.get_variable("w3", shape=[5, 1], initializer=tf.truncated_normal_initializer())
x = tf.placeholder(tf.float32, shape=[None, 5], name="x")
a1 = tf.matmul(x, w1)
a2 = tf.matmul(x, w2*w3)
a2 = tf.stop_gradient(a2)
loss = tf.reduce_mean(tf.square(a1 - a2))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1)
gradients = optimizer.compute_gradients(loss)
train_op = optimizer.apply_gradients(gradients)
tf.gradients(loss, embed) calcule la dérivée partielle du tenseur loss en ce qui concerne le tenseur embed. TensorFlow calcule cette dérivée partielle par rétropropagation, de sorte qu'on s'attend à un comportement qui évalue le résultat de tf.gradients(...) effectue la rétropropagation. Cependant, évaluer que tensor n'effectue pas de mises à jour variables, parce que l'expression ne comprend pas de des opérations d'affectation.
tf.stop_gradient() est une opération cela agit comme la fonction d'identité dans la direction avant, mais empêche le gradient accumulé de circuler à travers cet opérateur dans la direction arrière. Il n'empêche pas la rétropropagation tout à fait, mais empêche plutôt un tenseur individuel de contribuer aux gradients qui sont calculés pour une expression. documentation pour l'opération plus de détails sur l'opération, et quand l'utiliser.