Comment stocker de 7,3 milliards de lignes de données de marché (optimisé pour être lu)?
j'ai un ensemble de données de 1 minute de données de 1000 stocks depuis 1998, qui totalisent environ (2012-1998)*(365*24*60)*1000 = 7.3 Billion rangées.
la plupart du temps (99,9%), Je n'exécuterai que des requêtes read .
Quelle est la meilleure façon de stocker ces données dans une db?
- 1 grande table avec 7,3 rangées B?
- 1000 tableaux (un pour chaque symbole de stock) avec 7,3 m de lignes chacun?
- tout recommandation du moteur de base de données? (J'ai l'intention d'utiliser Amazon RDS pour MySQL)
Je n'ai pas l'habitude de traiter avec des ensembles de données aussi grands, donc c'est une excellente occasion pour moi d'apprendre. J'apprécie beaucoup votre aide et des conseils.
Edit:
il s'agit d'une rangée d'échantillons:
'XX', 20041208, 938, 43.7444, 43.7541, 43.735, 43.7444, 35116.7, 1, 0, 0
la colonne 1 est le symbole boursier, la colonne 2 est la date, la colonne 3 est la minute, le reste est ouvert-haut-bas-fermer les prix, le volume, et 3 colonnes entières.
la plupart des requêtes seront comme "Donnez-moi les prix de AAPL entre le 12 avril 2012 12: 15 et le 13 avril 2012 12: 52"
A propos du matériel: je prévois D'utiliser Amazon RDS donc je suis flexible sur ce
13 réponses
Parlez-nous des requêtes et de votre environnement matériel.
je serais très tenté d'aller NoSQL , en utilisant Hadoop ou quelque chose de similaire, tant que vous pouvez profiter du parallélisme.
mise à Jour
OK, pourquoi?
tout d'Abord, notez que j'ai demandé sur les requêtes. Vous ne pouvez pas -- et nous ne pouvons certainement pas -- répondez à ces questions sans savoir à quoi ressemble la charge de travail. (Je vais d'ailleurs avoir un article à ce sujet qui paraîtra bientôt, mais je ne peux pas le lier aujourd'hui.) Mais l'échelle du problème me fait penser à m'éloigner d'une vieille base de données parce que
-
" mon expérience avec des systèmes similaires suggère que l'accès sera soit grand séquentiel (calcul d'une sorte d'analyse de séries chronologiques) ou très très flexible données exploration de données (OLAP). Les données séquentielles peuvent être traitées de manière plus efficace et plus rapide séquentiellement; OLAP signifie calculer des lots et des lots d'indices, ce qui prendra beaucoup de temps ou beaucoup d'espace.
-
si vous faites ce qui est effectivement de grandes courses contre de nombreuses données dans un monde OLAP, cependant, une approche axée sur la colonne pourrait être la meilleure.
-
si vous voulez faire des requêtes aléatoires, en particulier en faisant des comparaisons croisées, un Système Hadoop pourrait être efficace. Pourquoi? Parce que
- vous pouvez mieux exploiter le parallélisme sur un matériel de base relativement petit.
- vous pouvez également mieux mettre en œuvre une haute fiabilité et la redondance
- beaucoup de ces problèmes se prêtent naturellement au paradigme MapReduce.
mais le fait est, jusqu'à ce que nous savons à propos de votre charge de travail, il est impossible pour dire quelque chose de définitif.
ainsi les bases de données sont pour des situations où vous avez un grand schéma compliqué qui change constamment. Vous n'avez qu'un "tableau" avec une poignée de simples champs numériques. Je le ferais de cette façon:
Préparer un C/C++ struct pour tenir le format d'enregistrement:
struct StockPrice
{
char ticker_code[2];
double stock_price;
timespec when;
etc
};
calculer ensuite la taille de (prix des actions[N]) Où N est le nombre d'enregistrements. (Sur un système 64-bit) Il ne devrait être que quelques centaines de gig, et s'adapter sur un HDD $50.
puis tronquer un fichier à cette taille et mmap (sur linux, ou utiliser CreateFileMapping sur windows) il en mémoire:
//pseduo-code
file = open("my.data", WRITE_ONLY);
truncate(file, sizeof(StockPrice[N]));
void* p = mmap(file, WRITE_ONLY);
lancer le pointeur mmaped à StockPrice*, et faire un passage de vos données remplissant le tableau. Fermez le mmap, et maintenant vous aurez vos données dans un grand tableau binaire dans un fichier qui peut être enregistré à nouveau plus tard.
StockPrice* stocks = (StockPrice*) p;
for (size_t i = 0; i < N; i++)
{
stocks[i] = ParseNextStock(stock_indata_file);
}
close(file);
vous pouvez maintenant mmap il à nouveau en lecture seule de n'importe quel programme et vos données seront facilement disponible:
file = open("my.data", READ_ONLY);
StockPrice* stocks = (StockPrice*) mmap(file, READ_ONLY);
// do stuff with stocks;
Alors maintenant, vous pouvez le traiter comme une mémoire tableau de structures. Vous pouvez créer différents types de structures de données d'index en fonction de ce que vos "requêtes" sont. Le noyau traitera de manière transparente l'échange des données vers/depuis le disque pour qu'il soit incroyablement rapide.
si vous vous attendez à avoir un certain motif d'accès (par exemple une date contiguë), il est préférable de trier le tableau dans cet ordre pour qu'il frappe le disque de façon séquentielle.
j'ai un ensemble de données de 1 minute de données de 1000 stocks [...] la plupart du temps (99,9%), Je n'exécuterai que des requêtes read .
stocker une fois et lire plusieurs fois des données numériques basées sur le temps est un cas d'utilisation appelé "série temporelle". Les autres séries chronologiques courantes sont les données de capteurs dans L'Internet des objets, les statistiques de surveillance du serveur, les événements d'application, etc.
cette question a été posée en 2012, et depuis, plusieurs moteurs de base de données ont développé des fonctionnalités spécifiques pour gérer les séries chronologiques. J'ai eu de bons résultats avec le InfluxDB , qui est open sourced, écrit en Go, et MIT-licensed.
InfluxDB a été spécialement optimisé pour stocker et interroger des données chronologiques. beaucoup plus que Cassandra , qui est souvent présenté comme grand pour stocker des séries chronologiques:
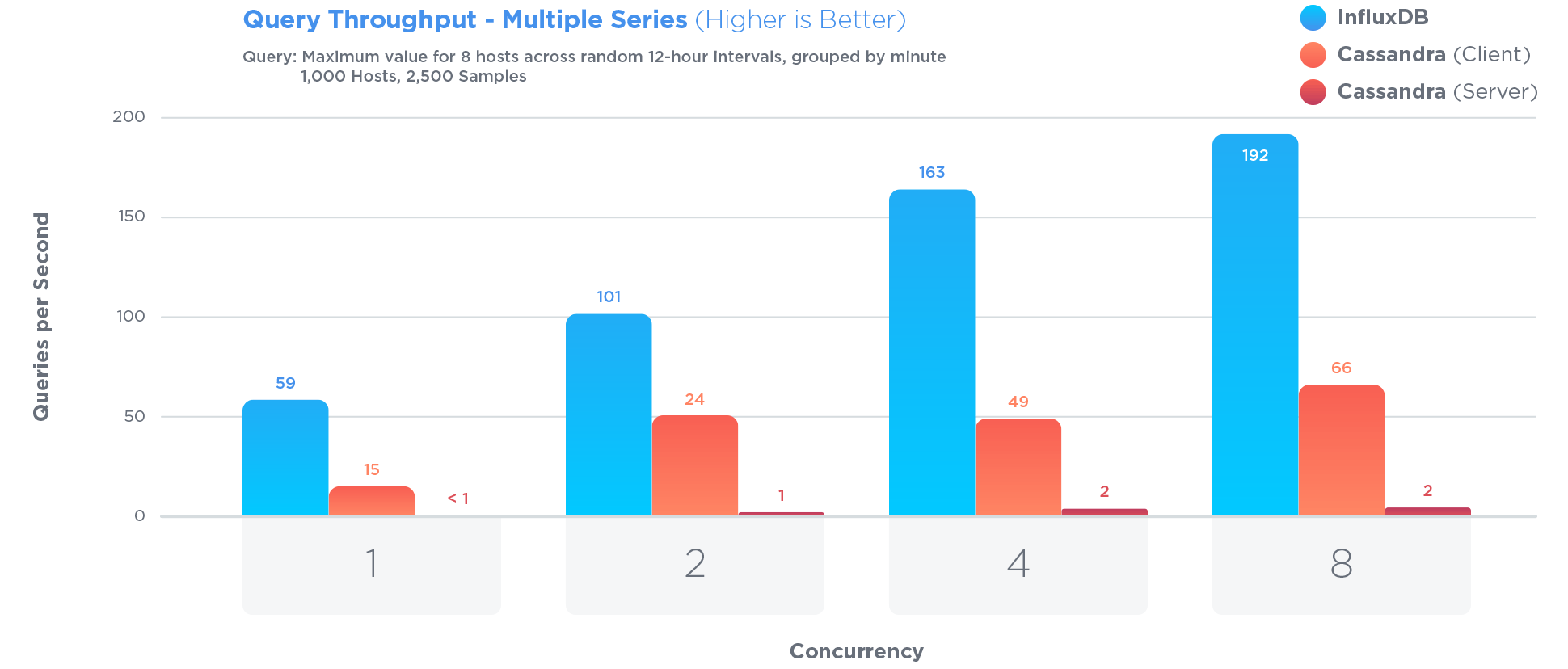
L'Optimisation pour les séries chronologiques impliquait certains compromis. Par exemple:
les mises à jour de données existantes sont rares et les mises à jour litigieuses ne se produisent jamais. Les données chronologiques sont surtout des données nouvelles qui ne sont jamais mises à jour.
Pro: restreindre l'accès aux mises à jour permet d'augmenter les performances de requête et d'écriture
Con: Mise À Jour la fonctionnalité est considérablement restreinte
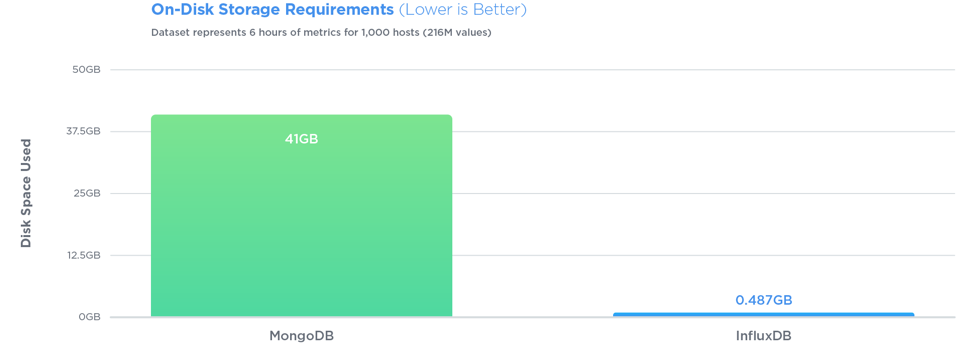
InfluxDB a surpassé MongoDB dans les trois tests avec un débit d'écriture 27 fois plus élevé, tout en utilisant 84 fois moins d'espace disque, et en fournissant des performances relativement égales quand il est venu à la vitesse de requête.
Les requêtes sont également très simples. Si vos lignes ressemblent à <symbol, timestamp, open, high, low, close, volume> , avec InfluxDB vous pouvez stocker cela, puis interroger facilement. Disons, pour les 10 dernières minutes de données:
SELECT open, close FROM market_data WHERE symbol = 'AAPL' AND time > '2012-04-12 12:15' AND time < '2012-04-13 12:52'
il n'y a pas D'ID, pas de clés, et pas de jointures à faire. Vous pouvez faire beaucoup de agrégations intéressantes . Vous n'avez pas à cloisonner verticalement la table comme avec PostgreSQL , ou contorsionner votre schéma dans des tableaux de secondes comme avec MongoDB . En outre, InfluxDB compresse très bien, tandis que PostgreSQL ne sera pas en mesure d'effectuer une compression sur le type de données que vous avez .
D'accord, donc c'est un peu loin des autres réponses, mais... il me semble que si vous avez les données dans un système de fichiers (un stock par fichier, peut-être) avec une taille d'enregistrement fixe, vous pouvez obtenir à la données vraiment facilement: étant donné une requête pour un stock particulier et la plage de temps, vous pouvez chercher à la bonne place, fetch toutes les données dont vous avez besoin (vous saurez exactement combien d'octets), transformer les données dans le format dont vous avez besoin (qui pourrait être très rapide en fonction de votre format de stockage) et vous êtes absent.
Je ne sais rien sur le stockage Amazon, mais si vous n'avez pas quelque chose comme l'accès direct aux fichiers, vous pourriez essentiellement avoir des blobs - vous auriez besoin d'équilibrer de grands blobs (moins d'enregistrements, mais probablement lire plus de données que vous avez besoin à chaque fois) avec de petits blobs (plus d'enregistrements donnant plus de frais généraux et probablement plus de demandes pour les obtenir, mais moins de données inutiles retournés à chaque fois).
ensuite, vous ajoutez cache - je suggérerais donner à différents serveurs différents stocks à gérer par exemple - et vous pouvez à peu près juste servir de la mémoire. Si vous avez assez de mémoire sur assez de serveurs, contournez la partie "charge à la demande" et chargez tous les fichiers au démarrage. Cela simplifierait les choses, au prix d'un démarrage plus lent (ce qui affecte évidemment le basculement, sauf si vous pouvez vous permettre d'avoir toujours deux serveurs pour tout stock particulier, ce qui serait utile).
noter que vous n'avez pas besoin de stocker le symbole stock, la date ou la minute pour chaque enregistrement - parce qu'ils sont implicites dans le fichier que vous chargez et la position dans le fichier. Vous devriez également considérer quelle précision vous avez besoin pour chaque valeur, et comment le stocker efficacement - vous avez donné 6SF dans votre question, que vous pourriez stocker en 20 bits. Potentiellement stocker trois entiers de 20 bits dans 64 bits de stockage: lisez-le comme un long (ou quelle que soit votre valeur entière de 64 bits sera) et utilisez masquage / déplacement pour le ramener à trois entiers. Vous aurez besoin de savoir quelle échelle utiliser, bien sûr - que vous pourriez probablement encoder dans les 4 bits de rechange, si vous ne pouvez pas le rendre constant.
vous n'avez pas dit ce que les trois autres colonnes entières sont comme, mais si vous pouviez vous en tirer avec 64 bits pour ces trois aussi bien, vous pourriez stocker un disque entier en 16 octets. C'est seulement ~ 110 GO pour l'ensemble de la base de données, ce qui n'est pas vraiment beaucoup...
EDIT: L'autre chose à considérer est que probablement le stock ne change pas au cours du week - end-ou en fait du jour au lendemain. Si le marché boursier est seulement ouvert 8 heures par jour, 5 jours par semaine, alors vous n'avez besoin de 40 valeurs par semaine au lieu de 168. À ce moment-là, vous pourriez finir avec seulement environ 28 Go de données dans vos fichiers... ce qui semble beaucoup plus petit que ce que vous pensiez probablement à l'origine. Avoir autant de données en mémoire est très raisonnable.
EDIT: I pensez que j'ai manqué l'explication de pourquoi cette approche est une bonne adaptation ici: vous avez un aspect très prévisible pour une grande partie de vos données - le palmarès des actions, la date et l'heure. En exprimant le code une fois (comme le nom du fichier) et en laissant la date/heure entièrement implicite dans la position des données, vous supprimez un tas de travail. C'est un peu comme la différence entre un String[] et un Map<Integer, String> - sachant que votre index de tableau commence toujours à 0 et augmente par incréments de 1 jusqu'à la longueur de la matrice permet un accès rapide et un stockage plus efficace.
il est entendu que HDF5 a été conçu spécifiquement avec le stockage de séries chronologiques de données de stock comme une application potentielle. D'autres chercheurs ont démontré que HDF5 est bon pour de grandes quantités de données: chromosomes , physique .
Voici une tentative de créer un serveur de données du marché en haut de la base de données Microsoft SQL Server 2012 qui devrait être bon pour L'analyse OLAP, un projet open source gratuit:
tout d'abord, il n'y a pas 365 jours de trading dans l'année, avec des vacances 52 week-ends (104) = dire 250 x les heures réelles du marché de jour est ouvert comme quelqu'un a dit, et d'utiliser le symbole comme la clé primaire n'est pas une bonne idée depuis les symboles changent , utilisez un k_equity_id (numérique) avec un symbole (char) depuis les symboles peuvent être comme ceci A , ou GAC-DB-B. TO, puis dans vos tableaux de données de l'information sur les prix, vous avez, donc votre estimation de 7,3 milliards est largement sur-calculée puisqu'il ne s'agit que d'environ 1,7 millions de rangs par symbole pendant 14 ans.
k_equity_id k_date k_minute
et pour la table de nem (qui sera vue 1000x sur les autres données)
k_equity_id k_date
Deuxièmement , ne stockez pas vos données OHLC by minute dans la même table DB as et table EOD (fin de journée), puisque quiconque veut regarder un pnf, ou graphique de ligne , sur une période d'un an, n'a aucun intérêt dans l'information by the minute.
laissez-moi vous recommander de jeter un oeil à apache solr , qui je pense serait idéal pour votre problème particulier. Fondamentalement, vous devez d'abord indexer vos données (chaque ligne étant un "document"). Solr est optimisé pour la recherche et prend en charge nativement les requêtes de portée sur les dates. Votre requête nominale,
"Give me the prices of AAPL between April 12 2012 12:15 and April 13 2012 12:52"
se traduirait par quelque chose comme:
?q=stock:AAPL AND date:[2012-04-12T12:15:00Z TO 2012-04-13T12:52:00Z]
supposant que "stock" est le nom du stock et" date "est un champ de données Créé à partir des colonnes" date "et" minute "de vos données d'entrée lors de l'indexation. Solr est incroyablement flexible et je ne peux vraiment pas dire assez de bonnes choses à ce sujet. Ainsi, par exemple, si vous aviez besoin de maintenir les champs dans les données originales, vous pouvez probablement trouver un moyen de créer dynamiquement le "champ de données" dans le cadre de la requête (ou du filtre).
vous devez comparer les solutions lentes avec un modèle simple optimisé en mémoire. Il s'adapte sur un serveur ram de 256 Go. Un snapshot s'adapte à 32 K et il suffit de l'indexer positionnellement sur datetime et stock. Ensuite, vous pouvez faire spécialisé instantanés, le plus ouvert de l'un est souvent synonyme de clôture de la précédente.
[edit] Pourquoi pensez-vous qu'il est judicieux d'utiliser une base de données (sgbd ou nosql)? Ces données ne changent pas, et elles s'inscrivent dans la mémoire. Ce n'est pas un cas d'utilisation où un sgbd peut ajouter de la valeur.
je pense que n'importe quel grand RDBMS s'en chargerait. Au niveau atomique, une table avec un partitionnement correct semble raisonnable (partition basée sur votre utilisation des données si elle est fixe - ce qui est susceptible d'être soit le symbole ou la date).
vous pouvez également regarder dans la construction de tableaux agrégés pour un accès plus rapide au-dessus du niveau atomique. Par exemple, si vos données sont au jour, mais que vous obtenez souvent des données au niveau de wekk ou même au niveau du mois, alors cela peut être pré-calculé dans un tableau agrégé. Dans certaines bases de données cela peut être fait à travers une vue en cache (différents noms pour différentes solutions DE DB - mais essentiellement son une vue sur les données atomiques, mais une fois exécuté la vue est mise en cache/durci dans une table de température fixe - qui est interrogé pour les requêtes de correspondance ultérieures. Cela peut être supprimé à l'intervalle pour libérer de la mémoire / espace disque).
je suppose que nous pourrions vous aider avec quelques idées quant à l'utilisation des données.
si vous avez le matériel, je vous recommande Cluster MySQL . Vous obtenez L'interface MySQL/RDBMS avec laquelle vous êtes familier, et vous obtenez des Écritures rapides et parallèles. Les lectures seront plus lentes que la MySQL régulière en raison de la latence du réseau, mais vous avez l'avantage d'être en mesure de paralléliser les requêtes et les lectures en raison de la façon dont MySQL Cluster et le moteur de stockage NDB fonctionne.
assurez-vous que vous avez assez de machines de Cluster MySQL et assez de mémoire/RAM pour chacun de ces Cluster though - MySQL est une architecture de base de données fortement axée sur la mémoire.
Ou Redis , si vous n'avez pas l'esprit d'une valeur-clé / NoSQL de l'interface de vos lectures/écritures. Assurez - vous que Redis a assez de mémoire-son super-rapide pour lire et écrire, vous pouvez faire des requêtes de base avec elle (non-RDBMS cependant) mais est également une base de données en mémoire.
Comme d'autres l'ont dit, d'en savoir plus sur les requêtes de vous aideront.
vous voulez les données stockées dans une table / base de données colonne . Les systèmes de bases de données comme Vertica et Greenplum sont des bases de données colonnaires, et je crois que SQL Server permet maintenant des tables colonnaires. Ceux-ci sont extrêmement efficaces pour SELECT ing à partir de très grands ensembles de données. Ils sont également efficaces pour importer de grands ensembles de données.
si votre cas d'utilisation est de simples lignes de lecture sans agrégation, vous pouvez utiliser Aerospike cluster. Il est dans la base de données de mémoire avec le soutien du système de fichiers pour la persistance. C'est aussi optimisé pour le SSD.
si votre cas d'utilisation nécessite des données agrégées, optez pour Mongo DB cluster avec un partage des plages de dates. Vous pouvez club year vise données dans les éclats.