Comment trier un dataframe par plusieurs colonne(s)?
je veux trier une donnée.cadre par colonnes multiples. Par exemple, avec les données.image ci-dessous je voudrais trier par colonne z (décroissant) puis par colonne b (ascendant):
dd <- data.frame(b = factor(c("Hi", "Med", "Hi", "Low"),
levels = c("Low", "Med", "Hi"), ordered = TRUE),
x = c("A", "D", "A", "C"), y = c(8, 3, 9, 9),
z = c(1, 1, 1, 2))
dd
b x y z
1 Hi A 8 1
2 Med D 3 1
3 Hi A 9 1
4 Low C 9 2
16 réponses
vous pouvez utiliser la fonction order() directement sans avoir recours à des outils supplémentaires -- voir cette réponse plus simple qui utilise une astuce à droite du haut du code example(order) :
R> dd[with(dd, order(-z, b)), ]
b x y z
4 Low C 9 2
2 Med D 3 1
1 Hi A 8 1
3 Hi A 9 1
éditer quelques 2+ ans plus tard: il a juste été demandé comment faire par l'index de colonne. La réponse est de passer simplement la ou les colonnes de tri désirées à la fonction order() :
R> dd[order(-dd[,4], dd[,1]), ]
b x y z
4 Low C 9 2
2 Med D 3 1
1 Hi A 8 1
3 Hi A 9 1
R>
plutôt que d'utiliser le nom de la colonne (et with() pour un accès plus facile/plus direct).
vos choix
-
orderdebase -
arrangededplyr -
setorderetsetordervdedata.table -
arrangedeplyr -
sortdetaRifx -
orderBydedoBy -
sortDatadeDeducer
la plupart du temps, vous devez utiliser les solutions dplyr ou data.table , à moins qu'il ne soit important d'avoir des dépendances, auquel cas utilisez base::order .
j'ai récemment ajouté sort.données.cadre d'un paquet CRAN, ce qui le rend compatible avec la classe comme discuté ici: meilleure façon de créer une cohérence Générique/méthode pour le tri.données.cadre?
Par conséquent, compte tenu des données.frame dd, vous pouvez trier comme suit:
dd <- data.frame(b = factor(c("Hi", "Med", "Hi", "Low"),
levels = c("Low", "Med", "Hi"), ordered = TRUE),
x = c("A", "D", "A", "C"), y = c(8, 3, 9, 9),
z = c(1, 1, 1, 2))
library(taRifx)
sort(dd, f= ~ -z + b )
Si vous êtes l'un des auteurs de cette fonction, veuillez me contacter. Débat public domaininess est ici: http://chat.stackoverflow.com/transcript/message/1094290#1094290
vous pouvez également utiliser la fonction arrange() de plyr comme Hadley a souligné dans le fil ci-dessus:
library(plyr)
arrange(dd,desc(z),b)
Benchmarks: notez que j'ai chargé chaque paquet dans une nouvelle session R car il y avait beaucoup de conflits. En particulier, le chargement du paquet doBy provoque sort à retourner" les objets suivants sont masqués de 'x(position 17)': b, x, y, z", et le chargement du paquet Deducer est remplacé par sort.data.frame de Kevin Wright ou du paquet taRifx.
#Load each time
dd <- data.frame(b = factor(c("Hi", "Med", "Hi", "Low"),
levels = c("Low", "Med", "Hi"), ordered = TRUE),
x = c("A", "D", "A", "C"), y = c(8, 3, 9, 9),
z = c(1, 1, 1, 2))
library(microbenchmark)
# Reload R between benchmarks
microbenchmark(dd[with(dd, order(-z, b)), ] ,
dd[order(-dd$z, dd$b),],
times=1000
)
temps médian:
dd[with(dd, order(-z, b)), ] 778
dd[order(-dd$z, dd$b),] 788
library(taRifx)
microbenchmark(sort(dd, f= ~-z+b ),times=1000)
temps médian: 1,567
library(plyr)
microbenchmark(arrange(dd,desc(z),b),times=1000)
temps médian: 862
library(doBy)
microbenchmark(orderBy(~-z+b, data=dd),times=1000)
temps médian: 1,694
notez que doBy prend beaucoup de temps pour charger le paquet.
library(Deducer)
microbenchmark(sortData(dd,c("z","b"),increasing= c(FALSE,TRUE)),times=1000)
ne pouvait pas faire la charge du Déducteur. Il a besoin d'une console JGR.
esort <- function(x, sortvar, ...) {
attach(x)
x <- x[with(x,order(sortvar,...)),]
return(x)
detach(x)
}
microbenchmark(esort(dd, -z, b),times=1000)
ne semble pas compatible avec microbenchmark en raison de l'attache/détachement.
m <- microbenchmark(
arrange(dd,desc(z),b),
sort(dd, f= ~-z+b ),
dd[with(dd, order(-z, b)), ] ,
dd[order(-dd$z, dd$b),],
times=1000
)
uq <- function(x) { fivenum(x)[4]}
lq <- function(x) { fivenum(x)[2]}
y_min <- 0 # min(by(m$time,m$expr,lq))
y_max <- max(by(m$time,m$expr,uq)) * 1.05
p <- ggplot(m,aes(x=expr,y=time)) + coord_cartesian(ylim = c( y_min , y_max ))
p + stat_summary(fun.y=median,fun.ymin = lq, fun.ymax = uq, aes(fill=expr))
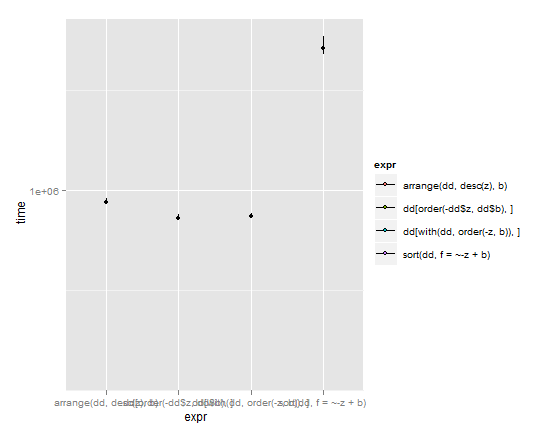
(les lignes s'étendent du quartile inférieur au quartile supérieur, point est la médiane)
vu ces résultats et la pesée simplicité vs. Vitesse, il faudrait que je donne le nod à arrange dans le plyr paquet . Il a une syntaxe simple et pourtant est presque aussi rapide que les commandes de base R avec leurs machinations alambiquées. Typiquement brillant travail Hadley Wickham. Mon seul regret avec elle est qu'elle casse la nomenclature standard R où le tri des objets est appelé par sort(object) , mais je comprends pourquoi Hadley l'a fait de cette façon en raison de questions discutées dans la question liée ci-dessus.
la réponse de Dirk est grande. Il souligne également une différence clé dans la syntaxe utilisée pour indexer data.frame s et data.table s:
## The data.frame way
dd[with(dd, order(-z, b)), ]
## The data.table way: (7 fewer characters, but that's not the important bit)
dd[order(-z, b)]
la différence entre les deux appels est faible, mais elle peut avoir des conséquences importantes. Surtout si vous écrivez le code de production et/ou êtes préoccupé par l'exactitude dans votre recherche, il est préférable d'éviter la répétition inutile de noms de variables. data.table
vous aide à le faire.
Voici un exemple de la façon dont la répétition de noms de variables pourrait vous mettre en difficulté:
changeons le contexte de la réponse de Dirk, et disons que cela fait partie d'un plus grand projet où il y a beaucoup de noms d'objets et ils sont longs et significatifs; au lieu de dd il est appelé quarterlyreport . Il devient:
quarterlyreport[with(quarterlyreport,order(-z,b)),]
Ok, très bien. Rien de mal à cela. Ensuite, votre patron vous demande d'inclure du trimestre précédent rapport dans le rapport. Vous allez à travers votre code, Ajouter un objet lastquarterlyreport dans différents endroits et d'une manière ou d'une autre (Comment sur terre?) vous vous retrouvez avec ceci:
quarterlyreport[with(lastquarterlyreport,order(-z,b)),]
ce n'est pas ce que vous vouliez dire mais vous ne l'avez pas vu parce que vous l'avez fait rapidement et il est niché sur une page de code similaire. Le code ne tombe pas (pas d'avertissement et pas d'erreur) parce que R pense que c'est ce que vous vouliez dire. Vous espérez que celui qui lit votre rapport le remarque, mais peut-être pas. Si vous travaillez beaucoup avec les langages de programmation alors ceci la situation peut être tous familiers. C'était une" typo", vous direz. Je vais réparer la typographie que tu diras à ton patron.
dans data.table nous sommes préoccupés par de petits détails comme celui-ci. Donc nous avons fait quelque chose de simple pour éviter de taper des noms de variables deux fois. Quelque chose de très simple. i est évalué dans le cadre de dd déjà, automatiquement. Vous n'avez pas besoin de with() .
au lieu de
dd[with(dd, order(-z, b)), ]
c'est juste
dd[order(-z, b)]
et au lieu de
quarterlyreport[with(lastquarterlyreport,order(-z,b)),]
c'est juste
quarterlyreport[order(-z,b)]
c'est une très petite différence, mais ça pourrait sauver votre peau un jour. En soupesant les différentes réponses à cette question, considérez compter les répétitions de noms de variables comme l'un de vos critères pour décider. Certaines réponses ont fait quelques répétitions, d'autres n'en ont pas.
Il ya beaucoup d'excellentes réponses ici, mais dplyr donne la seule syntaxe que je peux rapidement et facilement se souvenir (et donc maintenant utiliser très souvent):
library(dplyr)
# sort mtcars by mpg, ascending... use desc(mpg) for descending
arrange(mtcars, mpg)
# sort mtcars first by mpg, then by cyl, then by wt)
arrange(mtcars , mpg, cyl, wt)
pour le problème de L'OP:
arrange(dd, desc(z), b)
b x y z
1 Low C 9 2
2 Med D 3 1
3 Hi A 8 1
4 Hi A 9 1
Le package R data.table fournit à la fois rapide et la mémoire de l'efficacité de la commande de "1519350920 des données".tables avec une syntaxe simple (une partie de laquelle Matt a mis en évidence assez bien dans sa réponse ). Il y a eu beaucoup d'améliorations, et aussi une nouvelle fonction setorder() depuis. De v1.9.5+ , setorder() fonctionne également avec données.cadres .
tout d'abord, nous allons créer un ensemble de données assez grand et comparer les différentes méthodes mentionnées à partir d'autres réponses, puis énumérer les caractéristiques de données.tableau .
Data:
require(plyr)
require(doBy)
require(data.table)
require(dplyr)
require(taRifx)
set.seed(45L)
dat = data.frame(b = as.factor(sample(c("Hi", "Med", "Low"), 1e8, TRUE)),
x = sample(c("A", "D", "C"), 1e8, TRUE),
y = sample(100, 1e8, TRUE),
z = sample(5, 1e8, TRUE),
stringsAsFactors = FALSE)
Repères:
les minuteries rapportées proviennent de l'exécution system.time(...) sur ces fonctions indiquées ci-dessous. Les horaires sont présentés ci-dessous (dans l'ordre de la plus lente à la plus rapide).
orderBy( ~ -z + b, data = dat) ## doBy
plyr::arrange(dat, desc(z), b) ## plyr
arrange(dat, desc(z), b) ## dplyr
sort(dat, f = ~ -z + b) ## taRifx
dat[with(dat, order(-z, b)), ] ## base R
# convert to data.table, by reference
setDT(dat)
dat[order(-z, b)] ## data.table, base R like syntax
setorder(dat, -z, b) ## data.table, using setorder()
## setorder() now also works with data.frames
# R-session memory usage (BEFORE) = ~2GB (size of 'dat')
# ------------------------------------------------------------
# Package function Time (s) Peak memory Memory used
# ------------------------------------------------------------
# doBy orderBy 409.7 6.7 GB 4.7 GB
# taRifx sort 400.8 6.7 GB 4.7 GB
# plyr arrange 318.8 5.6 GB 3.6 GB
# base R order 299.0 5.6 GB 3.6 GB
# dplyr arrange 62.7 4.2 GB 2.2 GB
# ------------------------------------------------------------
# data.table order 6.2 4.2 GB 2.2 GB
# data.table setorder 4.5 2.4 GB 0.4 GB
# ------------------------------------------------------------
-
data.table'sDT[order(...)]syntaxe était ~10x plus rapide que le plus rapide des autres méthodes (dplyr), tout en consommant la même quantité de mémoire quedplyr. -
data.table'ssetorder()était ~14x plus rapide que le plus rapide des autres méthodes (dplyr), tout en prenant juste 0,4 Go mémoire supplémentaire .datest maintenant dans l'ordre nous avons besoin (comme il est mis à jour par référence).
vitesse:
-
les données.la commande de la table est extrêmement rapide parce qu'elle met en œuvre commande radix .
-
la syntaxe
DT[order(...)]est optimisé en interne pour l'utilisation des données .le tableau 's commande rapide aussi bien. Vous pouvez continuer à utiliser la syntaxe familière de base R mais accélérer le processus (et utiliser moins de mémoire).
mémoire:
-
la plupart du temps, nous n'avons pas besoin des données originales .cadre ou "1519350920 des données".tableau après nouvel appel d'offres. C'est, nous assignez habituellement le résultat de nouveau au même objet, par exemple:
DF <- DF[order(...)]Le problème est que cela nécessite au moins deux fois (2x) la mémoire de l'objet d'origine. Pour être la mémoire de l'efficacité , "1519350920 des données".le tableau fournit donc aussi une fonction
setorder().setorder()réarrange données.tableauxby reference( en place ), sans faire toute copie supplémentaire. Il utilise seulement la mémoire supplémentaire égale à la taille d'une colonne.
autres caractéristiques:
-
il soutient
integer,logical,numeric,characteret mêmebit64::integer64types.noter que
factor,Date,POSIXctetc.. les classes sont toutesinteger/numerictypes ci-dessous avec des attributs supplémentaires et sont donc pris en charge aussi bien. -
en base R, Nous ne pouvons pas utiliser
-sur un vecteur de caractères pour trier par cette colonne dans l'ordre décroissant. Au lieu de cela, nous devons utiliser-xtfrm(.).Cependant, dans "1519350920 des données".tableau , nous pouvons le faire, par exemple,
dat[order(-x)]ousetorder(dat, -x).
avec cette fonction (très utile) de Kevin Wright , posté dans la section Conseils du wiki R, ceci est facilement atteint.
sort(dd,by = ~ -z + b)
# b x y z
# 4 Low C 9 2
# 2 Med D 3 1
# 1 Hi A 8 1
# 3 Hi A 9 1
ou vous pouvez utiliser le paquet doBy
library(doBy)
dd <- orderBy(~-z+b, data=dd)
supposons que vous ayez un data.frame A et vous voulez le trier en utilisant la colonne appelée x ordre descendant. Appelez le trié data.frame newdata
newdata <- A[order(-A$x),]
si vous voulez monter l'ordre puis remplacer "-" par rien. Vous pouvez avoir quelque chose comme
newdata <- A[order(-A$x, A$y, -A$z),]
où x et z sont quelques colonnes dans data.frame A . Cela signifie trier data.frame A par x descendant, y ascendant et z descendant.
alternativement, en utilisant le package Deader
library(Deducer)
dd<- sortData(dd,c("z","b"),increasing= c(FALSE,TRUE))
si SQL vient naturellement à vous, sqldf gère L'ordre par comme Codd prévu.
j'ai appris au sujet de order avec l'exemple suivant qui m'a ensuite embrouillé pendant une longue période:
set.seed(1234)
ID = 1:10
Age = round(rnorm(10, 50, 1))
diag = c("Depression", "Bipolar")
Diagnosis = sample(diag, 10, replace=TRUE)
data = data.frame(ID, Age, Diagnosis)
databyAge = data[order(Age),]
databyAge
la seule raison pour laquelle cet exemple fonctionne est que order est le tri par le vector Age , pas par la colonne nommée Age dans le data frame data .
pour voir cela créer une base de données identique en utilisant read.table avec des noms de colonne légèrement différents et sans utiliser l'un des vecteurs ci-dessus:
my.data <- read.table(text = '
id age diagnosis
1 49 Depression
2 50 Depression
3 51 Depression
4 48 Depression
5 50 Depression
6 51 Bipolar
7 49 Bipolar
8 49 Bipolar
9 49 Bipolar
10 49 Depression
', header = TRUE)
la structure ci-dessus pour order ne fonctionne plus car il n'y a pas de vecteur nommé age :
databyage = my.data[order(age),]
la ligne suivante fonctionne parce que order Trie sur la colonne age dans my.data .
databyage = my.data[order(my.data$age),]
j'ai pensé que cela valait la peine de poster compte tenu de la confusion que j'ai été par cet exemple pendant si longtemps. Si ce post n'est pas jugé approprié pour le thread je peux supprimer il.
EDITION: Mai 13, 2014
ci-dessous est une façon généralisée de trier une base de données par chaque colonne sans spécifier les noms de colonne. Le code ci-dessous montre comment trier de gauche à droite ou de droite à gauche. Cela fonctionne si chaque colonne est numérique. Je n'ai pas essayé avec un personnage colonne ajoutée.
j'ai trouvé le code do.call Il ya un mois ou deux dans un ancien poste sur un autre site, mais seulement après des recherches approfondies et difficiles. Je ne suis pas sûr de pouvoir déménager ce poste maintenant. Le présent thread est le premier hit pour commander un data.frame dans R . Donc, j'ai pensé que ma version étendue de ce code original do.call pourrait être utile.
set.seed(1234)
v1 <- c(0,0,0,0, 0,0,0,0, 1,1,1,1, 1,1,1,1)
v2 <- c(0,0,0,0, 1,1,1,1, 0,0,0,0, 1,1,1,1)
v3 <- c(0,0,1,1, 0,0,1,1, 0,0,1,1, 0,0,1,1)
v4 <- c(0,1,0,1, 0,1,0,1, 0,1,0,1, 0,1,0,1)
df.1 <- data.frame(v1, v2, v3, v4)
df.1
rdf.1 <- df.1[sample(nrow(df.1), nrow(df.1), replace = FALSE),]
rdf.1
order.rdf.1 <- rdf.1[do.call(order, as.list(rdf.1)),]
order.rdf.1
order.rdf.2 <- rdf.1[do.call(order, rev(as.list(rdf.1))),]
order.rdf.2
rdf.3 <- data.frame(rdf.1$v2, rdf.1$v4, rdf.1$v3, rdf.1$v1)
rdf.3
order.rdf.3 <- rdf.1[do.call(order, as.list(rdf.3)),]
order.rdf.3
la réponse de Dirk est bonne mais si vous avez besoin du sort pour persister, vous voudrez appliquer le sort sur le nom de cette base de données. En utilisant le code exemple:
dd <- dd[with(dd, order(-z, b)), ]
en réponse à un commentaire ajouté dans L'OP pour savoir comment Trier par programmation:
utilisant dplyr et data.table
library(dplyr)
library(data.table)
dplyr
il suffit d'utiliser arrange_ , qui est la version D'évaluation Standard pour arrange .
df1 <- tbl_df(iris)
#using strings or formula
arrange_(df1, c('Petal.Length', 'Petal.Width'))
arrange_(df1, ~Petal.Length, ~Petal.Width)
Source: local data frame [150 x 5]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
(dbl) (dbl) (dbl) (dbl) (fctr)
1 4.6 3.6 1.0 0.2 setosa
2 4.3 3.0 1.1 0.1 setosa
3 5.8 4.0 1.2 0.2 setosa
4 5.0 3.2 1.2 0.2 setosa
5 4.7 3.2 1.3 0.2 setosa
6 5.4 3.9 1.3 0.4 setosa
7 5.5 3.5 1.3 0.2 setosa
8 4.4 3.0 1.3 0.2 setosa
9 5.0 3.5 1.3 0.3 setosa
10 4.5 2.3 1.3 0.3 setosa
.. ... ... ... ... ...
#Or using a variable
sortBy <- c('Petal.Length', 'Petal.Width')
arrange_(df1, .dots = sortBy)
Source: local data frame [150 x 5]
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
(dbl) (dbl) (dbl) (dbl) (fctr)
1 4.6 3.6 1.0 0.2 setosa
2 4.3 3.0 1.1 0.1 setosa
3 5.8 4.0 1.2 0.2 setosa
4 5.0 3.2 1.2 0.2 setosa
5 4.7 3.2 1.3 0.2 setosa
6 5.5 3.5 1.3 0.2 setosa
7 4.4 3.0 1.3 0.2 setosa
8 4.4 3.2 1.3 0.2 setosa
9 5.0 3.5 1.3 0.3 setosa
10 4.5 2.3 1.3 0.3 setosa
.. ... ... ... ... ...
#Doing the same operation except sorting Petal.Length in descending order
sortByDesc <- c('desc(Petal.Length)', 'Petal.Width')
arrange_(df1, .dots = sortByDesc)
plus d'informations ici: https://cran.r-project.org/web/packages/dplyr/vignettes/nse.html
il est mieux utiliser la formule qu'il capte aussi l'environnement pour évaluer une expression dans
"1519110920 des données".tableau 1519120920"dt1 <- data.table(iris) #not really required, as you can work directly on your data.frame
sortBy <- c('Petal.Length', 'Petal.Width')
sortType <- c(-1, 1)
setorderv(dt1, sortBy, sortType)
dt1
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1: 7.7 2.6 6.9 2.3 virginica
2: 7.7 2.8 6.7 2.0 virginica
3: 7.7 3.8 6.7 2.2 virginica
4: 7.6 3.0 6.6 2.1 virginica
5: 7.9 3.8 6.4 2.0 virginica
---
146: 5.4 3.9 1.3 0.4 setosa
147: 5.8 4.0 1.2 0.2 setosa
148: 5.0 3.2 1.2 0.2 setosa
149: 4.3 3.0 1.1 0.1 setosa
150: 4.6 3.6 1.0 0.2 setosa
par souci d'exhaustivité: vous pouvez également utiliser la fonction sortByCol() du paquet BBmisc :
library(BBmisc)
sortByCol(dd, c("z", "b"), asc = c(FALSE, TRUE))
b x y z
4 Low C 9 2
2 Med D 3 1
1 Hi A 8 1
3 Hi A 9 1
comparaison des Performances:
library(microbenchmark)
microbenchmark(sortByCol(dd, c("z", "b"), asc = c(FALSE, TRUE)), times = 100000)
median 202.878
library(plyr)
microbenchmark(arrange(dd,desc(z),b),times=100000)
median 148.758
microbenchmark(dd[with(dd, order(-z, b)), ], times = 100000)
median 115.872
tout comme les trieurs mécaniques de cartes d'autrefois, d'abord Trier par la touche la moins significative, puis la prochaine plus significative, etc. Aucune bibliothèque n'est nécessaire, Fonctionne avec n'importe quel nombre de clés et n'importe quelle combinaison de clés ascendantes et descendantes.
dd <- dd[order(dd$b, decreasing = FALSE),]
maintenant nous sommes prêts à faire la clé la plus significative. Le sort est stable, et tous les liens dans la clé la plus importante ont déjà été résolus.
dd <- dd[order(dd$z, decreasing = TRUE),]
ce n'est peut-être pas le plus rapide, mais il est certainement simple et fiable
une autre variante, utilisant le colis rgr :
> library(rgr)
> gx.sort.df(dd, ~ -z+b)
b x y z
4 Low C 9 2
2 Med D 3 1
1 Hi A 8 1
3 Hi A 9 1