Comment configurer Intellij 14 feuille de travail Scala pour lancer Spark
j'essaie de créer un SparkContext dans une feuille de travail Intellij 14 Scala.
voici mon dépendances
name := "LearnSpark"
version := "1.0"
scalaVersion := "2.11.7"
// for working with Spark API
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.4.0"
voici le code que j'exécute dans la feuille de travail
import org.apache.spark.{SparkContext, SparkConf}
val conf = new SparkConf().setMaster("local").setAppName("spark-play")
val sc = new SparkContext(conf)
erreur
15/08/24 14:01:59 ERROR SparkContext: Error initializing SparkContext.
java.lang.ClassNotFoundException: rg.apache.spark.rpc.akka.AkkaRpcEnvFactory
at java.net.URLClassLoader.run(URLClassLoader.java:372)
at java.net.URLClassLoader.run(URLClassLoader.java:361)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:360)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
quand je lance Spark comme application autonome ça marche très bien. Par exemple,
import org.apache.spark.{SparkContext, SparkConf}
// stops verbose logs
import org.apache.log4j.{Level, Logger}
object TestMain {
Logger.getLogger("org").setLevel(Level.OFF)
def main(args: Array[String]): Unit = {
//Create SparkContext
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("mySparkApp")
.set("spark.executor.memory", "1g")
.set("spark.rdd.compress", "true")
.set("spark.storage.memoryFraction", "1")
val sc = new SparkContext(conf)
val data = sc.parallelize(1 to 10000000).collect().filter(_ < 1000)
data.foreach(println)
}
}
Quelqu'un peut-il m'indiquer où je devrais chercher pour résoudre cette exception?
Merci.
6 réponses
Puisqu'il y a encore quelques doutes s'il est possible d'exécuter IntelliJ idée Scala feuille de travail avec Spark et cette question Est la plus directe, je voulais partager ma capture d'écran et une recette de style Livre de cuisine pour obtenir le code Spark évalué dans la feuille de travail.
J'utilise Spark 2.1.0 avec la feuille de travail Scala dans IntelliJ IDEA (CE 2016.3.4).
La première étape consiste à construire.fichier sbt lors de l'importation de dépendances dans IntelliJ. J'ai utilisé le même simple.sbt à partir de Étincelle De Démarrage Rapide:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.7"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
la deuxième étape consiste à décocher 'Run worksheet in the compiler process' checbox in Settings -> Languages and Frameworks -> Scala -> Worksheet. J'ai également testé les autres paramètres de la feuille de travail et ils n'ont eu aucun effet sur l'avertissement concernant la création d'un contexte Double Spark.
Voici la version du code de SimpleApp.exemple scala dans le même guide modifié pour fonctionner dans la feuille de travail. master et appName les paramètres doivent être définis dans la Feuille de calcul:
import org.apache.spark.{SparkConf, SparkContext}
val conf = new SparkConf()
conf.setMaster("local[*]")
conf.setAppName("Simple Application")
val sc = new SparkContext(conf)
val logFile = "/opt/spark-latest/README.md"
val logData = sc.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println(s"Lines with a: $numAs, Lines with b: $numBs")
voici une capture d'écran de la feuille de travail fonctionnement Scala avec Spark:
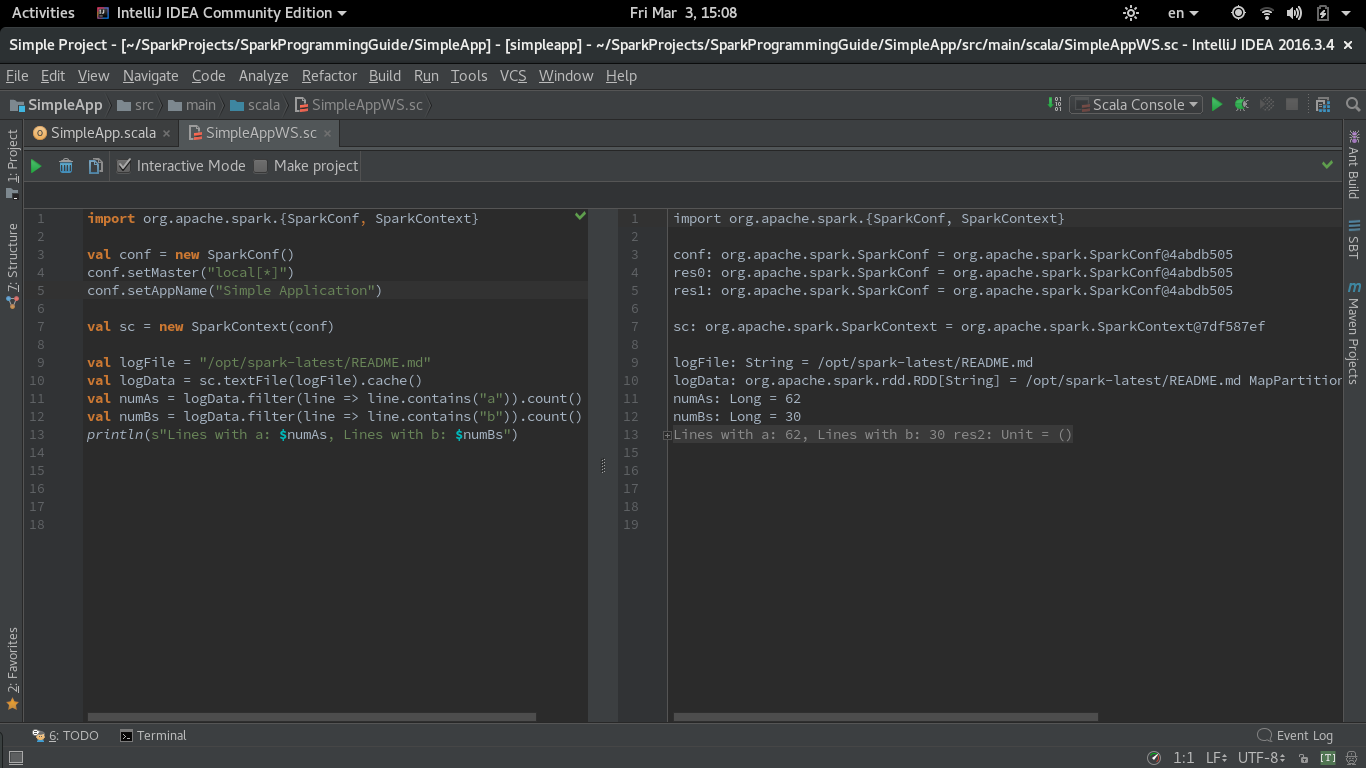
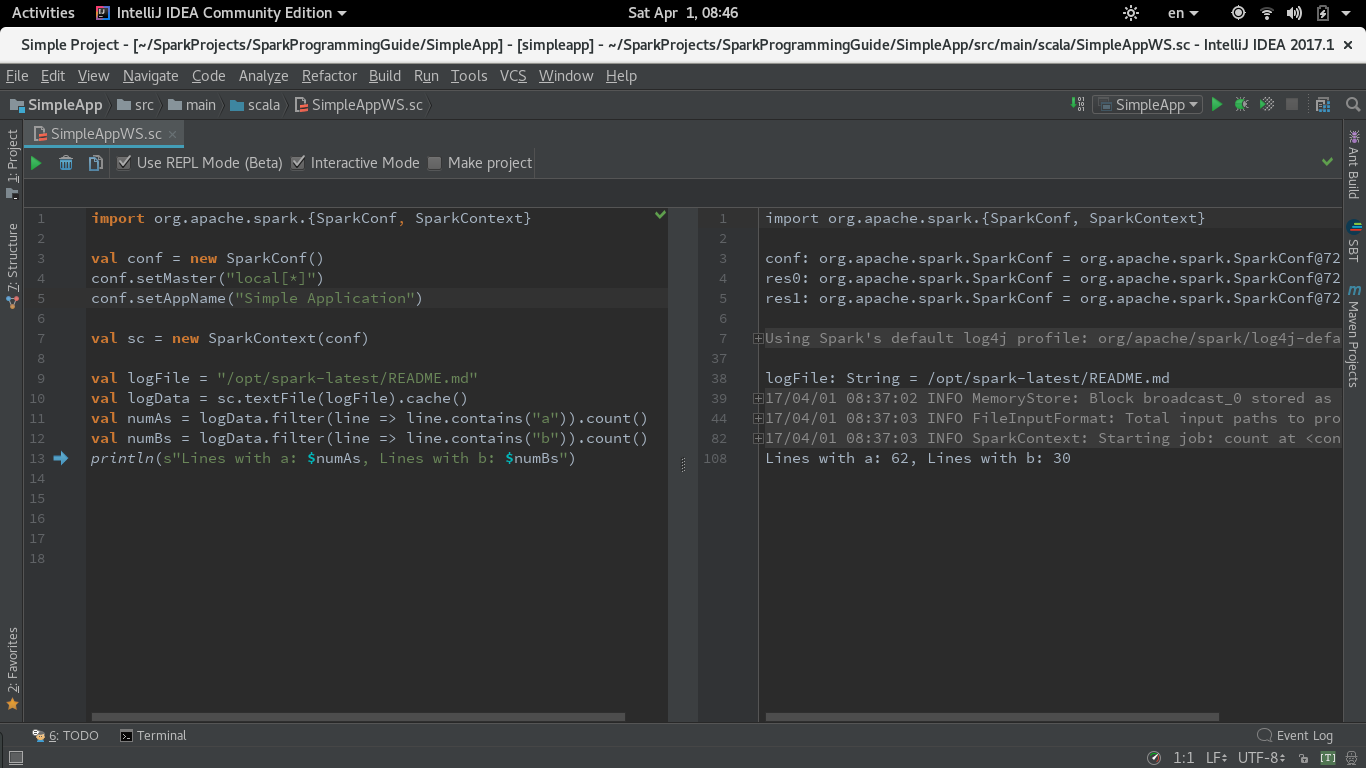
UPDATE for Intellijce 2017.1 (Worksheet in REPL mode)
en 2017.1 Intellij introduit le mode REPL pour feuille de travail. J'ai testé le même code avec l'option "Utiliser REPL" cochée. Pour que ce mode s'exécute, vous devez laisser la case "Exécuter la feuille de travail dans le processus de compilation" dans Paramètres de feuille de travail que j'ai décrit ci-dessus vérifié (il est par défaut).
le code fonctionne très bien en mode feuille de travail REPL.
Voici la Capture d'écran:
j'utilise Intellij CE 2016.3, Spark 2.0.2 et j'exécute la feuille de travail scala dans le Modèle compatible eclipse, jusqu'à présent, la plupart d'entre eux sont ok maintenant, il ne reste que des problèmes mineurs.
ouvrir les Préférences-> type scala -> dans les Langues Et dans des Cadres, choisissez Scala -> Choisir la Feuille de calcul -> sélectionner uniquement eclipse mode de compatibilité ou ne rien sélectionner.
auparavant, en sélectionnant "Exécuter feuille de travail dans le processus de compilation", j'ai éprouvé beaucoup de problèmes, pas seulement en utilisant Spark, aussi Elasticsearch. Je suppose que lors de la sélection "exécuter feuille de travail dans le processus de compilation", L'Intellij fera une optimisation délicate, ajoutant paresseux à la variable etc peut-être, ce qui dans certaines situations rend la feuille de travail plutôt filaire.
aussi je trouve que parfois quand la classe définie dans la feuille de travail ne fonctionne pas ou se comporte anormalement, mettre dans un fichier séparé et le compiler, puis l'exécuter dans la feuille de travail, résoudra beaucoup de problèmes.
Selon Spark 1.4.0 site vous devriez utiliser scala 2.10.x:
Spark fonctionne sur Java 6+, python 2.6+ et r 3.1+. Pour L'API Scala, Spark 1.4.0 utilise Scala 2.10. Vous devrez utiliser une version Scala compatible (2.10.x).
EDITED:
lorsque vous cliquez sur "Créer un nouveau projet" dans intelliJ après avoir sélectionné le projet sbt et cliquez sur "Suivant", ce menu apparaîtra où vous pouvez choisir le scala version:
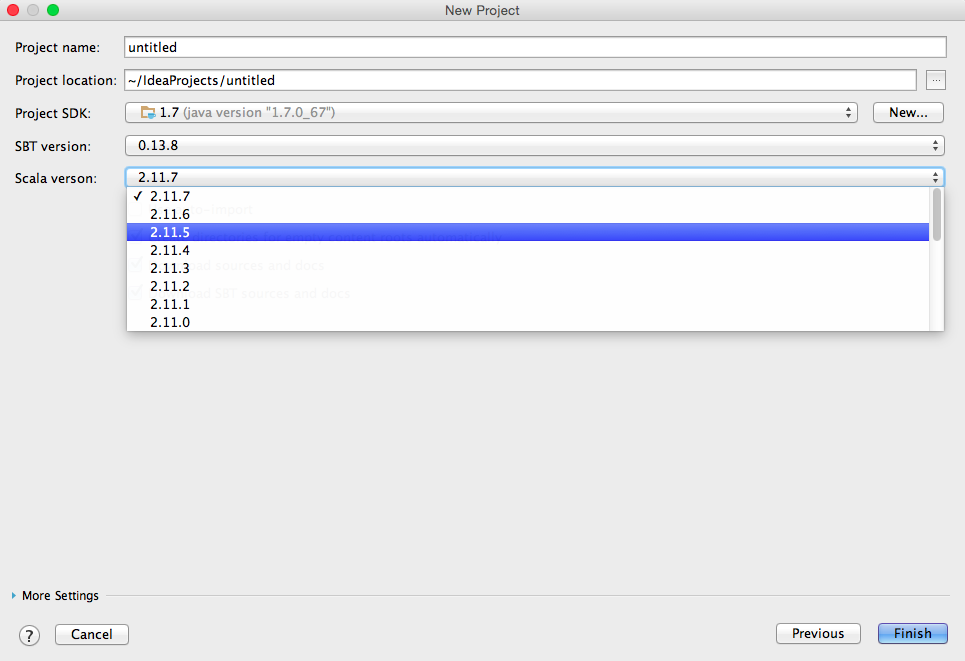
EDITED 2:
Vous pouvez également utiliser ce paquet spark core pour scala 2.11.x:
libraryDependencies += "org.apache.spark" %% "spark-core_2.11" % "1.4.0"
j'étais confronté au même problème, et je n'ai pas pu le résoudre, bien que j'ai essayé plusieurs fois. Au lieu de la feuille de travail, en ce moment j'utilise console scala, au moins mieux que rien pour l'utiliser.
J'ai moi aussi rencontré un problème similaire avec Intellij où les bibliothèques ne sont pas résolues par SBT après avoir ajouté les dépendances libraires dans build.sbt. IDEA ne télécharge pas les dépendances par défaut. Redémarré L'Intellij, il résout le problème. commencez à télécharger les dépendances.
Donc,
assurez-vous que les dépendances sont téléchargées dans votre projet local, sinon, redémarrez L'IDE ou activez L'IDE pour télécharger les dépendances requises
s'assurer que les dépôts sont résolus, dans le cas contraire, inclure l'emplacement du dépôt sous résolveur+=
ci-dessous est ma configuration Maven dependecies, elle fonctionne toujours et stable. J'écris habituellement spark pragram et le soumettre à fil-cluster pour l'exécution de cluster.
La clé de bocal est ${étincelle.accueil} / lib / spark-assembly-1.5.2 hadoop2.6.0.jar, il contient presque tous étincelle dépendances et inclus avec chaque étincelle de presse. (En fait spark-submit distribuera ce jar à cluster, alors ne vous inquiétez pas ClassNotFoundException plus :D)
je pense que vous pouvez modifier votre libraryDependencies + = " org.Apache.spark" % % "spark-core" % "1.4.0" au-dessus de configuration similaire(Maven utilisation systemPath à point de locaux pot de dépendance, je pense que SBT ont même configuration)
Note: les exclusions de logging jars sont facultatives, en raison de ses conflits avec mes autres jars.
<!--Apache Spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-assembly</artifactId>
<version>1.5.2</version>
<scope>system</scope>
<systemPath>${spark.home}/lib/spark-assembly-1.5.2-hadoop2.6.0.jar</systemPath>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.10.2</version>
</dependency>