Recherche par partie de mot avec ElasticSearch
j'ai récemment commencé à utiliser ElasticSearch et je ne peux pas le faire rechercher une partie d'un mot.
exemple: j'ai trois documents de ma couchdb indexés dans ElasticSearch:
{
"_id" : "1",
"name" : "John Doeman",
"function" : "Janitor"
}
{
"_id" : "2",
"name" : "Jane Doewoman",
"function" : "Teacher"
}
{
"_id" : "3",
"name" : "Jimmy Jackal",
"function" : "Student"
}
donc maintenant, je veux rechercher tous les documents contenant " Doe "
curl http://localhost:9200/my_idx/my_type/_search?q=Doe
qui ne renvoie aucun résultat. Mais si je cherche
curl http://localhost:9200/my_idx/my_type/_search?q=Doeman
Il ne retour d'un document (Jean Doeman).
j'ai essayé de définir différents analyseurs et différents filtres comme propriétés de mon Indice. J'ai aussi essayé d'utiliser une requête complète (par exemple:
{
"query": {
"term": {
"name": "Doe"
}
}
}
) Mais rien ne semble fonctionner.
Comment puis-je faire ElasticSearch trouver à la fois John Doeman et Jane Doewoman quand je cherche "Doe" ?
mise à JOUR
j'ai essayé d'utiliser le tokenizer nGram et filtre, comme Igor proposé, comme ceci:
{
"index": {
"index": "my_idx",
"type": "my_type",
"bulk_size": "100",
"bulk_timeout": "10ms",
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "my_ngram_tokenizer",
"filter": [
"my_ngram_filter"
]
}
},
"filter": {
"my_ngram_filter": {
"type": "nGram",
"min_gram": 1,
"max_gram": 1
}
},
"tokenizer": {
"my_ngram_tokenizer": {
"type": "nGram",
"min_gram": 1,
"max_gram": 1
}
}
}
}
}
le problème que j'ai maintenant est que chaque requête renvoie tous les documents. Les pointeurs? La documentation d'ElasticSearch sur l'utilisation de nGram n'est pas excellente...
9 réponses
j'utilise nGram, aussi. J'utilise tokenizer standard et nGram juste comme un filtre. Voici ma configuration:
{
"index": {
"index": "my_idx",
"type": "my_type",
"analysis": {
"index_analyzer": {
"my_index_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"mynGram"
]
}
},
"search_analyzer": {
"my_search_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"standard",
"lowercase",
"mynGram"
]
}
},
"filter": {
"mynGram": {
"type": "nGram",
"min_gram": 2,
"max_gram": 50
}
}
}
}
}
trouvons des parties de mots jusqu'à 50 lettres. Réglez le max_gram en fonction de vos besoins. En allemand peut devenir vraiment grand, donc je l'ai mis à une grande valeur.
la recherche avec des caractères génériques de début et de fin va être extrêmement lente sur un grand index. Si vous voulez pouvoir effectuer une recherche par préfixe de mot, supprimez le Joker menant. Si vous avez vraiment besoin de trouver un substrat au milieu d'un mot, vous seriez mieux d'utiliser Ngram tokenizer.
je pense qu'il n'y a pas besoin de changer la cartographie. Essayez d'utiliser query_string , c'est parfait. Tous les scénarios fonctionneront avec l'analyseur standard par défaut:
nous avons des données:
{"_id" : "1","name" : "John Doeman","function" : "Janitor"}
{"_id" : "2","name" : "Jane Doewoman","function" : "Teacher"}
scénario 1:
{"query": {
"query_string" : {"default_field" : "name", "query" : "*Doe*"}
} }
réponse:
{"_id" : "1","name" : "John Doeman","function" : "Janitor"}
{"_id" : "2","name" : "Jane Doewoman","function" : "Teacher"}
scénario 2:
{"query": {
"query_string" : {"default_field" : "name", "query" : "*Jan*"}
} }
réponse:
{"_id" : "1","name" : "John Doeman","function" : "Janitor"}
scénario 3:
{"query": {
"query_string" : {"default_field" : "name", "query" : "*oh* *oe*"}
} }
réponse:
{"_id" : "1","name" : "John Doeman","function" : "Janitor"}
{"_id" : "2","name" : "Jane Doewoman","function" : "Teacher"}
EDIT - Même implémentation avec spring data elastic search https://stackoverflow.com/a/43579948/2357869
une explication de plus comment query_string est meilleur que d'autres https://stackoverflow.com/a/43321606/2357869
sans changer vos correspondances d'index vous pouvez faire une simple requête de préfixe qui fera des recherches partielles comme vous espérez pour
ie.
{
"query": {
"prefix" : { "name" : "Doe" }
}
}
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-prefix-query.html
Essayez la solution est décrite ici: Exact de la sous-Chaîne de Recherches dans ElasticSearch
{
"mappings": {
"my_type": {
"index_analyzer":"index_ngram",
"search_analyzer":"search_ngram"
}
},
"settings": {
"analysis": {
"filter": {
"ngram_filter": {
"type": "ngram",
"min_gram": 3,
"max_gram": 8
}
},
"analyzer": {
"index_ngram": {
"type": "custom",
"tokenizer": "keyword",
"filter": [ "ngram_filter", "lowercase" ]
},
"search_ngram": {
"type": "custom",
"tokenizer": "keyword",
"filter": "lowercase"
}
}
}
}
}
pour résoudre le problème d'utilisation du disque et le trop long terme de recherche problème court de 8 caractères long ngrams sont utilisés (configuré avec: " max_gram": 8 ). Pour rechercher des termes avec plus de 8 caractères, Transformez votre recherche en un booléen et une requête à la recherche de chaque 8 caractères distincts sous-chaîne dans une chaîne. Par exemple, si un utilisateur recherchait large yard (une chaîne de 10 caractères), la recherche serait:
"arge ya ET arge yar ET rge yard .
si vous voulez mettre en œuvre la fonctionnalité autocomplete, alors suggestion D'achèvement est la solution la plus soignée. Le prochain blog post contient une description très claire comment cela fonctionne.
en deux mots, c'est une structure de données en mémoire appelée FST qui contient des suggestions valables et est optimisée pour une récupération rapide et une utilisation de la mémoire. Essentiellement, il s'agit juste d'un graphe. Par exemple, et FST contenant les mots hotel , marriot , mercure , munchen et munich ressemblerait à ceci:
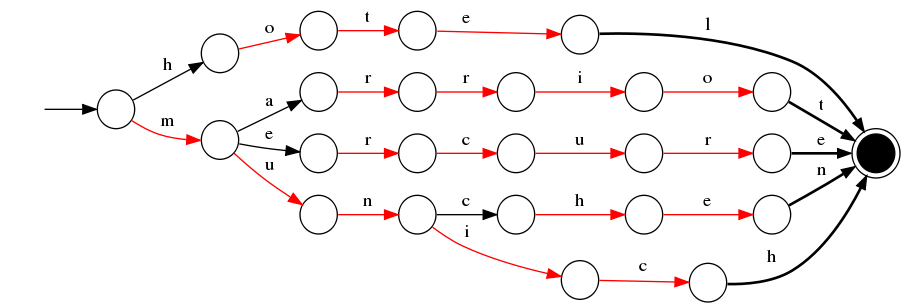
Elasticsearch possède un caractère d'interrogation qui peut être utilisé dans ce cas et qui est le plus facile. Il retournera les deux docs correspondants
vous pouvez utiliser regexp.
{ "_id" : "1", "name" : "John Doeman" , "function" : "Janitor"}
{ "_id" : "2", "name" : "Jane Doewoman","function" : "Teacher" }
{ "_id" : "3", "name" : "Jimmy Jackal" ,"function" : "Student" }
si vous utilisez cette requête :
{
"query": {
"regexp": {
"name": "J.*"
}
}
}
, vous obtiendrez toutes les données que leur nom commence par "J".Considérez que vous voulez recevoir seulement les deux premiers enregistrement que leur nom se termine par "man" de sorte que vous pouvez utiliser cette requête:
{
"query": {
"regexp": {
"name": ".*man"
}
}
}
et si vous souhaitez recevoir tous les enregistrement de leur nom, "m" , vous pouvez utiliser cette requête :
{
"query": {
"regexp": {
"name": ".*m.*"
}
}
}
This fonctionne pour moi .Et j'espère que ma réponse conviendra pour résoudre votre problème.
peu importe.
j'ai dû regarder la documentation de Lucene. On dirait que je peux utiliser des jokers! :- )
curl http://localhost:9200/my_idx/my_type/_search?q=*Doe*
fait l'affaire!