Comment lire la sortie de git diff?
la page de manuel pour git-diff est assez longue, et explique de nombreux cas qui ne semblent pas nécessaires pour un débutant. Par exemple:
git diff origin/master
7 réponses
permet de jeter un oeil à l'exemple de diff avancé de l'histoire git (dans commit 1088261f dans Git.dépôt git ):
diff --git a/builtin-http-fetch.c b/http-fetch.c
similarity index 95%
rename from builtin-http-fetch.c
rename to http-fetch.c
index f3e63d7..e8f44ba 100644
--- a/builtin-http-fetch.c
+++ b/http-fetch.c
@@ -1,8 +1,9 @@
#include "cache.h"
#include "walker.h"
-int cmd_http_fetch(int argc, const char **argv, const char *prefix)
+int main(int argc, const char **argv)
{
+ const char *prefix;
struct walker *walker;
int commits_on_stdin = 0;
int commits;
@@ -18,6 +19,8 @@ int cmd_http_fetch(int argc, const char **argv, const char *prefix)
int get_verbosely = 0;
int get_recover = 0;
+ prefix = setup_git_directory();
+
git_config(git_default_config, NULL);
while (arg < argc && argv[arg][0] == '-') {
permet d'analyser ce patch ligne par ligne.
-
la première ligne
diff --git a/builtin-http-fetch.c b/http-fetch.c
est un en-tête "git diff" sous la formediff --git a/file1 b/file2. Les noms de fichiersa/etb/sont les mêmes, sauf s'il s'agit de renommer/copier (comme dans notre cas). Le--gitsignifie que diff est dans le format" git " diff. -
une ou plusieurs lignes d'en-tête étendues suivent. Les trois premiers
similarity index 95% rename from builtin-http-fetch.c rename to http-fetch.c
nous disent que le fichier a été renommé debuiltin-http-fetch.càhttp-fetch.cet que ces deux fichiers sont identiques à 95% (qui a été utilisé pour détecter ce renommage).
la dernière ligne dans l'en-tête étendu diff, qui estindex f3e63d7..e8f44ba 100644
nous dire sur le mode de donnée fichier (100644signifie qu'il s'agit d'un fichier ordinaire et non par exemple symlink, et qu'il n'a pas de bit de permission exécutable), et sur le hachage raccourci de preimage (la version du fichier avant une modification donnée) et postimage (la version du fichier après une modification). Cette ligne est utilisée pargit am --3waypour essayer de faire une fusion à trois si le patch ne peut pas être appliqué lui-même.
-
suivant est deux lignes d'en-tête unifié diff
--- a/builtin-http-fetch.c +++ b/http-fetch.c
comparé àdiff -Urésultat il n'a pas de nom de fichier from-file-modification-time ni to-file-modification-time after source (preimage) et destination (postimage). Si le fichier a été créé, la source est/dev/null; si le fichier a été supprimé, la cible est/dev/null.
si vous définissezdiff.mnemonicPrefixvariable de configuration à true, à la place dea/etb/préfixes dans cet en-tête à deux lignes vous pouvez avoir à la placec/,i/,w/eto/comme des préfixes, respectivement à ce que vous les comparer; voir git-config(1) -
viennent ensuite un ou plusieurs morceaux de différences; Chaque morceau montre une zone où les fichiers diffèrent. Le format unifié hunks commence avec la ligne comme
@@ -1,8 +1,9 @@
ou@@ -18,6 +19,8 @@ int cmd_http_fetch(int argc, const char **argv, ...
il est dans le format@@ from-file-range to-file-range @@ [header]. La gamme from-file est sous la forme-<start line>,<number of lines>, et la gamme to-file est+<start line>,<number of lines>. Les deux la ligne de départ et le nombre de lignes se rapportent à la position et à la longueur du hunk en préimage et en postimage, respectivement. Si le nombre de lignes pas indiqué, cela signifie qu'il est de 0.l'en-tête optionnel affiche la fonction C où chaque changement se produit, s'il s'agit d'un fichier C (comme l'option
-pdans GNU diff), ou l'équivalent, le cas échéant, pour d'autres types de fichiers. -
vient ensuite la description des endroits où les fichiers diffèrent. Les lignes communes aux deux fichiers commencer par un caractère espace. Les lignes qui diffèrent réellement entre les deux fichiers ont l'un des caractères indicateurs suivants dans la colonne d'impression de gauche:
- '+' -- une ligne a été ajoutée ici au premier fichier.
- ' - ' -- une ligne a été retirée du premier fichier.
ainsi, par exemple, premier morceau#include "cache.h" #include "walker.h" -int cmd_http_fetch(int argc, const char **argv, const char *prefix) +int main(int argc, const char **argv) { + const char *prefix; struct walker *walker; int commits_on_stdin = 0; int commits;signifie que La ligne
cmd_http_fetcha été remplacée par la lignemainet la ligneconst char *prefix;a été ajoutée.En d'autres termes, avant le changement, le fragment approprié de " builtin-http-fetch.c 'file ressemblait à ceci:
#include "cache.h" #include "walker.h" int cmd_http_fetch(int argc, const char **argv, const char *prefix) { struct walker *walker; int commits_on_stdin = 0; int commits;après le changement ce fragment de Maintenant 'http-fetch.c 'file ressemble à ceci à la place:
#include "cache.h" #include "walker.h" int main(int argc, const char **argv) { const char *prefix; struct walker *walker; int commits_on_stdin = 0; int commits; -
il pourrait y avoir
\ No newline at end of file
ligne présente (il n'est pas dans exemple de diff).
Comme Donal aviez dit il est préférable de pratiquer la lecture diff sur les exemples de la vie réelle, où vous savez ce que vous avez changé.
, les Références:
- git-diff(1) page de manuel , section "Génération d'patchs avec -p"
- (diff.info) détail unifié noeud, "Description détaillée du Format Unifié".
@@ -1,2 +3,4 @@ partie du diff
cette partie m'a pris un certain temps à comprendre, donc j'ai créé un exemple minimal.
le format est fondamentalement le même que le diff -u diff unifié.
par exemple:
diff -u <(seq 16) <(seq 16 | grep -Ev '^(2|3|14|15)$')
ici nous avons enlevé les lignes 2, 3, 14 et 15. Sortie:
@@ -1,6 +1,4 @@
1
-2
-3
4
5
6
@@ -11,6 +9,4 @@
11
12
13
-14
-15
16
@@ -1,6 +1,4 @@ signifie:
-
-1,6: cette pièce correspond à la ligne 1 à 6 du premier fichier:1 2 3 4 5 6-signifie "vieux", comme nous l'appelons habituellement commediff -u old new. -
+1,4dit que cette pièce correspond à la ligne 1 à 4 du second fichier.+signifie "nouveau".nous avons seulement 4 lignes au lieu de 6 parce que 2 lignes ont été supprimées! Le nouveau hunk est juste:
1 4 5 6
@@ -11,6 +9,4 @@ pour le second morceau est analogue:
-
sur l'ancien fichier, nous avons 6 lignes, commençant à la ligne 11 de l'ancien fichier:
11 12 13 14 15 16 -
sur le nouveau fichier, nous avons 4 lignes, commençant à la ligne 9 du nouveau fichier:
11 12 13 16noter que la ligne
11est la 9ème ligne du nouveau fichier parce que nous avons déjà supprimé 2 lignes sur le hunk précédent: 2 et 3.
Hunk en-tête
selon votre version et votre configuration, vous pouvez également obtenir une ligne de code à côté de la ligne @@ , par exemple le func1() { dans:
@@ -4,7 +4,6 @@ func1() {
cela peut également être obtenu avec le -p drapeau de plaine diff .
exemple: ancien fichier:
func1() {
1;
2;
3;
4;
5;
6;
7;
8;
9;
}
si nous supprimons la ligne 6 , la diff indique:
@@ -4,7 +4,6 @@ func1() {
3;
4;
5;
- 6;
7;
8;
9;
notez que ce n'est pas la ligne correcte pour func1 : elle a sauté les lignes 1 et 2 .
ce trait impressionnant indique souvent exactement à quelle fonction ou classe chaque morceau appartient, ce qui est très utile pour interpréter la diff.
Comment l'algorithme de choisir l'en-tête fonctionne exactement thème est abordé: d'Où vient l'extrait dans le git diff hunk en-tête de venir?
voici un exemple simple.
diff --git a/file b/file
index 10ff2df..84d4fa2 100644
--- a/file
+++ b/file
@@ -1,5 +1,5 @@
line1
line2
-this line will be deleted
line4
line5
+this line is added
Voici une explication (voir détails ici ).
-
--gitn'est pas une commande, cela signifie que c'est une version git de diff (pas unix) -
a/ b/sont des répertoires, ils ne sont pas réels. c'est juste une commodité quand nous traitons avec le même fichier (dans mon cas a/ est dans l'index et b/ est dans le répertoire de travail) -
10ff2df..84d4fa2sont Id d'objet blob de ces 2 fichiers -
100644est le "mode bits," indiquant qu'il s'agit d'un fichier régulier (non exécutable et pas un lien symbolique) -
--- a/file +++ b/fileles signes moins indiquent des lignes dans la version a/ mais manquantes dans la version b/; et les signes plus indiquent des lignes manquantes dans a/ mais présentes dans b/ (dans mon cas --- signifie des lignes supprimées et + + signifie des lignes ajoutées dans b / et ceci le fichier dans le répertoire de travail) -
@@ -1,5 +1,5 @@pour comprendre cela, il est préférable de travailler avec un grand fichier; si vous avez deux modifications à des endroits différents, vous obtiendrez deux entrées comme@@ -1,5 +1,5 @@; supposons que vous avez la ligne de fichier 1 ... ligne 100 et supprimer la ligne 10 et ajouter une nouvelle ligne 100-vous obtiendrez:
@@ -7,7 +7,6 @@ line6 line7 line8 line9 -this line10 to be deleted line11 line12 line13 @@ -98,3 +97,4 @@ line97 line98 line99 line100 +this is new line100
le format de sortie par défaut (qui vient à l'origine d'un programme appelé diff si vous voulez chercher plus d'information) est connu comme un"diff unifié". Il contient essentiellement 4 types différents de lignes:
- lignes de contexte, qui commencent par un espace unique,
- lignes d'insertion qui montrent une ligne insérée, qui commencent par un
+, - lignes de suppression, qui commencent par un
-, et - lignes de métadonnées qui décrivent des choses de niveau supérieur comme le fichier dont il est question, les options qui ont été utilisées pour générer la diff, si le fichier a changé ses permissions, etc.
je vous conseille de vous exercer à lire des diffs entre deux versions d'un fichier où vous savez exactement ce que vous avez changé. Comme ça, vous allez reconnaître ce qui se passe quand vous le voyez.
sur mon mac:
info diff sélectionnez ensuite: Output formats -> Context -> Unified format -> Detailed Unified :
Ou en ligne homme diff sur gnu suivant le même chemin que pour le même article:
fichier: diff.info, noeud: détaillé Unifiée, Suivant: Exemple Unifiée, Jusqu': Format Unifié
Description détaillée du Format unifié ......................................
le format de sortie unifié commence avec un en-tête de deux lignes, qui semble comme ceci:
--- FROM-FILE FROM-FILE-MODIFICATION-TIME +++ TO-FILE TO-FILE-MODIFICATION-TIMEL'horodatage ressemble `2002-02-21 23: 30: 39.942229878 -0800 " pour indiquer la date, l'heure avec fractionnaire secondes, et le temps de la zone.
vous pouvez modifier le contenu de l'en-tête avec l'option' --label=LABEL'; voir * Noter Les Noms Alternatifs::.
vient ensuite un ou plusieurs morceaux de les différences; chaque morceau montre une zone où les fichiers diffèrent. Unifier format un beau ressembler à ceci:
@@ FROM-FILE-RANGE TO-FILE-RANGE @@ LINE-FROM-EITHER-FILE LINE-FROM-EITHER-FILE...Les lignes communes aux deux fichiers commencer par un caractère espace. Le les lignes qui diffèrent réellement entre les deux fichiers ont l'une des opérations suivantes caractères indicateurs dans l'impression de gauche colonne:
'+' Une ligne a été ajoutée ici au premier fichier.
" -" Une ligne a été retirée ici du premier fichier.
il n'est pas clair de votre question quelle partie des diff vous trouvez déroutante: la différence réelle, ou l'information d'en-tête supplémentaire git imprime. Juste au cas où, voici un rapide aperçu de l'en-tête.
la première ligne est quelque chose comme diff --git a/path/to/file b/path/to/file - évidemment, il est juste vous dire ce fichier cette section de la diff est pour. Si vous définissez la variable de configuration booléenne diff.mnemonic prefix , les a et b seront remplacés par des lettres plus descriptives comme c et w (commit et le travail de l'arbre).
ensuite, il y a des" lignes de mode " - des lignes qui vous donnent une description de tout changement qui n'implique pas de changer le contenu du fichier. Cela inclut les fichiers nouveaux / supprimés, les fichiers renommés/copiés et les modifications de permissions.
enfin, il y a une ligne comme index 789bd4..0afb621 100644 . Vous ne vous en soucierez probablement jamais, mais ces nombres hexadécimaux à 6 chiffres sont les hachures sha1 abrégées des anciennes et des nouvelles taches pour ce fichier (un blob est un objet git stockant des données brutes comme le contenu d'un fichier). Et bien sûr, le 100644 est le mode du fichier - les trois derniers chiffres sont évidemment des permissions; les trois premiers donnent des informations supplémentaires sur les métadonnées du fichier ( donc post décrivant que ).
après cela, vous êtes sur la sortie standard de diff unifiée (tout comme le classique diff -U ). Il est divisé en hunks - un hunk est une section du fichier contenant les changements et leur cadre. Chaque morceau est précédé d'une paire de lignes --- et +++ indiquant le fichier en question, alors la différence réelle est (par défaut) trois lignes de contexte de chaque côté des lignes - et + montrant les lignes supprimées/ajoutées.
dans le contrôle de version, les différences entre deux versions sont présentées dans ce qu'on appelle une "diff" (ou, synonymiquement, un "patch"). Examinons en détail une telle différence - et apprenons à la lire.
regardez la sortie d'une diff. Sur la base de cette sortie, nous comprendrons la sortie git diff.
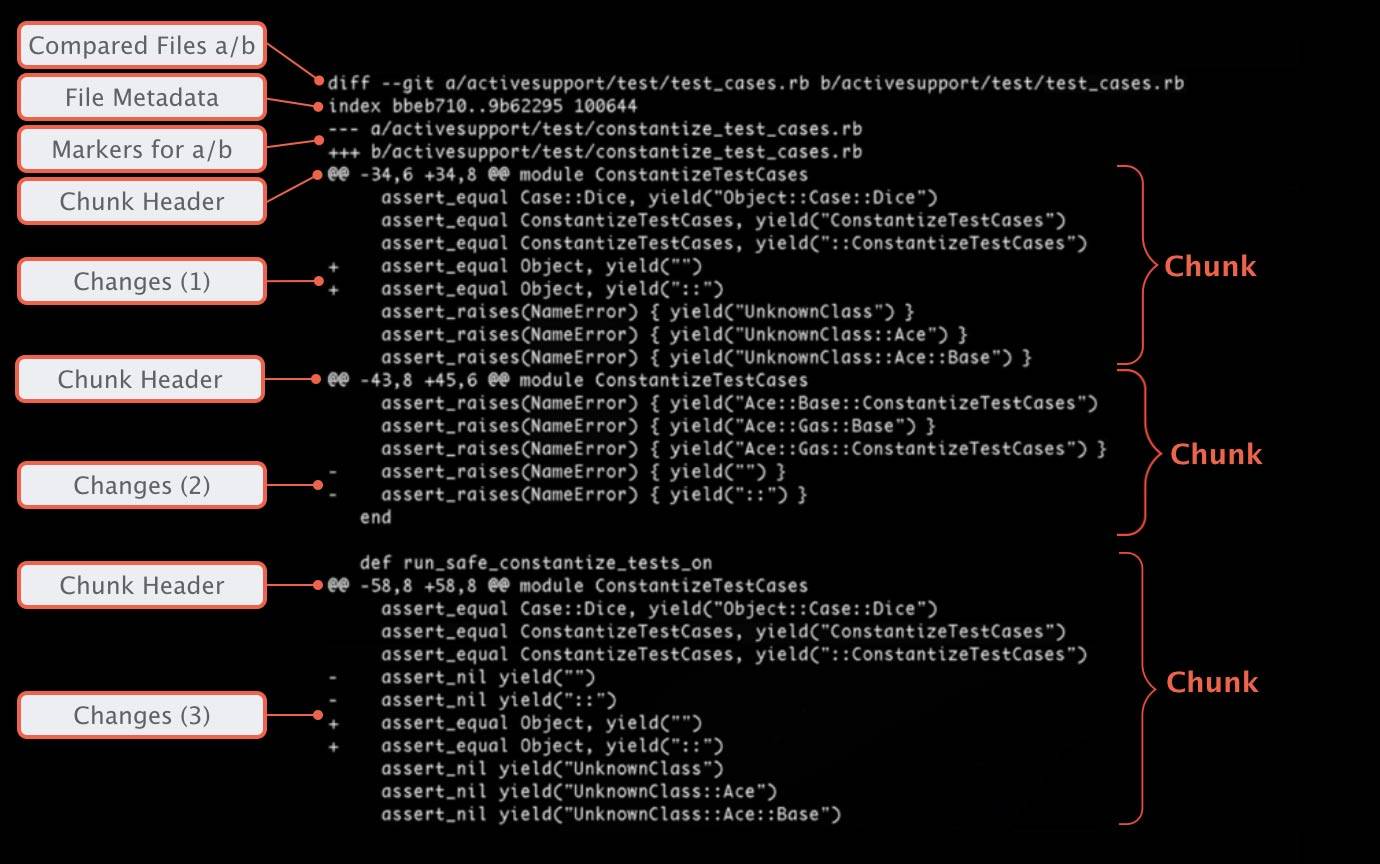
Fichiers par Rapport a/b
notre diff compare deux articles l'un avec l'autre: l'article A et L'article B. Dans la plupart des cas, A et B seront le même fichier, mais dans des versions différentes. Bien qu'ils ne soient pas utilisés très souvent, un diff pourrait aussi comparer deux fichiers complètement indépendants les uns des autres pour montrer comment ils diffèrent. Pour clarifier ce qui est réellement comparé, une sortie diff commence toujours par déclarer quels fichiers sont représentés par "A" et "B".
Les Métadonnées D'Un Fichier
Le fichier de métadonnées est très technique, les informations que vous aurez probablement jamais besoin dans la pratique. Les deux premiers chiffres représentent les hachages (ou, simplement mis: "IDs") de nos deux fichiers: Git sauve chaque version non seulement du projet mais aussi de chaque fichier en tant qu'objet. Ce hachage identifie un fichier objet à une révision spécifique. Le dernier numéro est un identifiant de mode de fichier interne (100644 est juste un "fichier normal", tandis que 100755 spécifie un fichier exécutable et 120000 représente un symbole lien.)
marqueurs pour a /b
plus bas dans la sortie, les changements réels seront marqués comme provenant de A ou B. Afin de les distinguer, A et B reçoivent chacun un symbole: pour la version a, c'est un signe moins ( " - ") et pour la version B, Un signe plus ( " + " ) est utilisé.
Chunk
une diff n'affiche pas le fichier complet du début à la fin: vous Je ne voudrais pas voir tout dans un fichier de 10 000 lignes, alors que seulement 2 lignes ont changé. Au lieu de cela, il montre seulement les parties qui ont été modifiées. Une telle partie est appelée un "chunk" (ou "morceau"). En plus des lignes modifiées, un morceau contient aussi un peu de "contexte": quelques lignes (inchangées) avant et après la modification pour que vous puissiez mieux comprendre dans quel contexte ce changement s'est produit.
Bloc D'En-Tête
Chacun de ces morceaux est précédé d'un en-tête. Enfermés dans deux "@" signes chacun, Git vous indique quelles lignes ont été touchés. Dans notre cas, les lignes suivantes sont représentées dans le premier morceau:
-
du fichier A (représenté par un" -"), 6 lignes sont extraites, à partir de la ligne no. 34
-
du fichier B (représenté par un"+"), 8 lignes sont affichées, aussi à partir de la ligne no. 34
le texte après la paire finale de "@ @ " vise à clarifier le contexte, encore une fois: Git tente d'afficher un nom de méthode ou d'autres informations contextuelles d'où ce morceau a été pris dans le fichier. Cependant, cela dépend beaucoup du langage de programmation et ne fonctionne pas dans tous les scénarios.
Modifications
chaque ligne modifiée est précédée d'un " + "ou d'un" - " symbole. Comme expliqué, ces symboles vous aident à comprendre l'apparence exacte des versions A et B: une ligne qui est précédée d'un signe " - "vient de A, tandis qu'une ligne avec un signe" + " vient de B. Dans la plupart des cas, Git choisit A et B de telle manière que vous pouvez penser à A/- comme "ancien" contenu et B/+ comme "nouveau" contenu.
regardons notre exemple:
-
la modification #1 contient deux lignes précédées d'un"+". Depuis pas de contrepartie dans Une existaient pour ces lignes (pas de lignes avec" -"), cela signifie que ces lignes ont été ajoutées.
-
le changement #2 est exactement le contraire: en A, nous avons deux lignes marquées avec des signes" -". Cependant, B n'a pas d'équivalent (pas de lignes"+"), ce qui signifie qu'elles ont été supprimées.
-
dans la modification #3, finalement, certaines lignes ont été modifiées: les deux lignes "-" ont été changées pour ressembler aux deux lignes "+" ci-dessous.