Comment faire une fonction d'activation personnalisée avec seulement Python dans Tensorflow?
Supposons que vous ayez besoin de créer une fonction d'activation qui n'est pas possible en utilisant uniquement des blocs de construction TensorFlow prédéfinis, que pouvez-vous faire?
Donc, dans Tensorflow il est possible de créer votre propre fonction d'activation. Mais c'est assez compliqué, vous devez l'écrire en C++ et recompiler l'ensemble de tensorflow [1] [2].
Est-il un moyen plus simple?
2 réponses
Oui!
Crédit: Il était difficile de trouver l'information et de la faire fonctionner, mais voici un exemple de copie des principes et du code trouvés ici et ici.
Exigences: Avant de commencer, il y a deux exigences pour que cela puisse réussir. Vous devez d'abord être capable d'écrire votre activation en fonction sur les tableaux numpy. Deuxièmement vous devez être capable d'écrire la dérivée de cette fonction non plus en tant que fonction dans Tensorflow (plus facile) ou dans le pire des cas en tant que fonction sur les tableaux numpy.
Fonction D'Activation D'écriture:
Prenons donc par exemple cette fonction dont on voudrait utiliser une fonction d'activation:
def spiky(x):
r = x % 1
if r <= 0.5:
return r
else:
return 0
Qui se présentent comme suit:
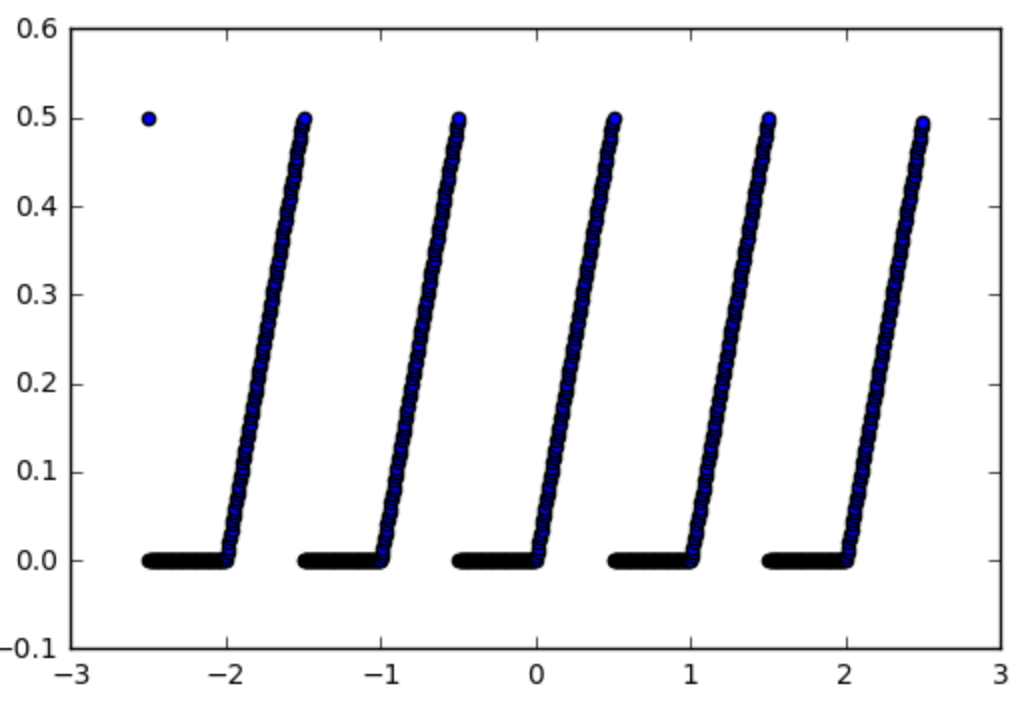
La première étape consiste à en faire une fonction numpy, c'est facile:
import numpy as np
np_spiky = np.vectorize(spiky)
Maintenant, nous devrions écrire sa dérivée.
Gradient de Activation: Dans notre cas, c'est facile, il est 1 si x mod 1
def d_spiky(x):
r = x % 1
if r <= 0.5:
return 1
else:
return 0
np_d_spiky = np.vectorize(d_spiky)
Maintenant, pour la partie difficile de faire une fonction TensorFlow hors de celui-ci.
Faire un fct numpy à un fct tensorflow:
Nous allons commencer par faire de np_d_spiky une fonction tensorflow. Il y a une fonction dans tensorflow tf.py_func(func, inp, Tout, stateful=stateful, name=name) [doc] {[40] } qui transforme n'importe quelle fonction numpy en une fonction tensorflow, donc nous pouvons l'utiliser:
import tensorflow as tf
from tensorflow.python.framework import ops
np_d_spiky_32 = lambda x: np_d_spiky(x).astype(np.float32)
def tf_d_spiky(x,name=None):
with tf.name_scope(name, "d_spiky", [x]) as name:
y = tf.py_func(np_d_spiky_32,
[x],
[tf.float32],
name=name,
stateful=False)
return y[0]
tf.py_func agit sur des listes de tenseurs (et renvoie une liste des tenseurs), c'est pourquoi nous avons [x] (et retour y[0]). L'option stateful est de dire à tensorflow si la fonction donne toujours la même sortie pour la même entrée (stateful = False) auquel cas tensorflow peut simplement le graphique tensorflow, c'est notre cas et sera probablement le cas dans la plupart des situations. Une chose à faire attention à ce stade est que numpy utilisé float64 mais tensorflow utilise float32 donc vous devez convertir votre fonction à utiliser float32 avant de pouvoir convertir il à une fonction tensorflow sinon tensorflow se plaindra. C'est pourquoi nous devons faire np_d_spiky_32 d'abord.
Et les dégradés? le problème avec seulement faire ce qui précède est que même si nous avons maintenant tf_d_spiky qui est la version tensorflow de np_d_spiky, nous ne pouvions pas l'utiliser comme fonction d'activation si nous le voulions parce que tensorflow ne sait pas comment calculer les gradients de cette fonction.
Hack pour obtenir des Dégradés:, Comme expliqué dans les sources mentionné ci-dessus, il y a un hack pour définir les dégradés d'une fonction à l'aide de tf.RegisterGradient [doc] et tf.Graph.gradient_override_map [doc]. En copiant le code de harpone on peut modifier la fonction tf.py_func pour lui faire définir le dégradé en même temps:
def py_func(func, inp, Tout, stateful=True, name=None, grad=None):
# Need to generate a unique name to avoid duplicates:
rnd_name = 'PyFuncGrad' + str(np.random.randint(0, 1E+8))
tf.RegisterGradient(rnd_name)(grad) # see _MySquareGrad for grad example
g = tf.get_default_graph()
with g.gradient_override_map({"PyFunc": rnd_name}):
return tf.py_func(func, inp, Tout, stateful=stateful, name=name)
Maintenant, nous avons presque terminé, la seule chose est que la fonction grad que nous devons passer à la fonction py_func ci-dessus doit prendre une forme spéciale. Il doit prendre dans une opération, et les anciens dégradés avant l'opération et propager les gradients vers l'arrière après l'opération.
Fonction Gradient: donc, pour notre fonction d'activation spiky, c'est comme ça que nous le ferions:
def spikygrad(op, grad):
x = op.inputs[0]
n_gr = tf_d_spiky(x)
return grad * n_gr
La fonction d'activation a une seule entrée, c'est pourquoi x = op.inputs[0]. Si l'opération avait plusieurs entrées, nous aurions besoin de retourner un tuple, un gradient pour chaque entrée. Par exemple, si l'opération était a-ble gradient par rapport à a est +1 et par rapport à b est -1 donc nous aurions return +1*grad,-1*grad. Notez que nous devons retourner les fonctions tensorflow de l'entrée, c'est pourquoi besoin tf_d_spiky, np_d_spiky n'aurait pas fonctionné car il ne peut pas agir sur les tenseurs tensorflow. Alternativement, nous aurions pu écrire la dérivée en utilisant les fonctions tensorflow:
def spikygrad2(op, grad):
x = op.inputs[0]
r = tf.mod(x,1)
n_gr = tf.to_float(tf.less_equal(r, 0.5))
return grad * n_gr
En Combinant tous ensemble: Maintenant que nous avons toutes les pièces, on peut combiner tous ensemble:
np_spiky_32 = lambda x: np_spiky(x).astype(np.float32)
def tf_spiky(x, name=None):
with tf.name_scope(name, "spiky", [x]) as name:
y = py_func(np_spiky_32,
[x],
[tf.float32],
name=name,
grad=spikygrad) # <-- here's the call to the gradient
return y[0]
Et maintenant nous avons fini. Et nous pouvons le tester.
Essai:
with tf.Session() as sess:
x = tf.constant([0.2,0.7,1.2,1.7])
y = tf_spiky(x)
tf.initialize_all_variables().run()
print(x.eval(), y.eval(), tf.gradients(y, [x])[0].eval())
[ 0.2 0.69999999 1.20000005 1.70000005] [ 0.2 0. 0.20000005 0.] [ 1. 0. 1. 0.]
Succès!
Pourquoi ne pas simplement utiliser les fonctions déjà disponibles dans tensorflow pour créer votre nouvelle fonction?
Pour la fonction spiky dans Votre réponse , cela pourrait ressembler à ceci
def spiky(x):
r = tf.floormod(x, tf.constant(1))
cond = tf.less_equal(r, tf.constant(0.5))
return tf.where(cond, r, tf.constant(0))
Je considérerais cela beaucoup plus facile (même pas besoin de calculer des gradients) et à moins que vous ne vouliez faire des choses vraiment exotiques, je peux à peine imaginer que tensorflow ne fournit pas les blocs de construction pour construire des fonctions d'activation très complexes.