Comment charger IPython shell avec PySpark
je veux charger IPython shell (pas IPython notebook) dans lequel je peux utiliser PySpark en ligne de commande. Est-ce possible? J'ai installé Spark-1.4.1.
7 réponses
Si vous utilisez Étincelle < 1.2, vous pouvez simplement exécuter bin/pyspark avec une variable environnementale IPYTHON=1.
IPYTHON=1 /path/to/bin/pyspark
ou
export IPYTHON=1
/path/to/bin/pyspark
alors que ci-dessus va encore travailler sur L'étincelle 1.2 et la façon recommandée ci-dessus pour configurer L'environnement Python pour ces versions est PYSPARK_DRIVER_PYTHON
PYSPARK_DRIVER_PYTHON=ipython /path/to/bin/pyspark
ou
export PYSPARK_DRIVER_PYTHON=ipython
/path/to/bin/pyspark
Vous pouvez remplacer ipython avec un chemin vers l'interprète de votre choix.
j'utilise ptpython (1), qui non seulement fournit ipython fonctionnalité ainsi que votre choix soit vi (1) ou emacs (1)-reliures; il fournit aussi de la dynamique de code pop-up sens ou l'intelligence, ce qui est extrêmement utile lorsque vous effectuez Ad-Hoc ÉTINCELLE de travail sur la CLI.
Voici ce que ma viactivé ptpython la session ressemble, en prenant note du VI (INSERT) mode en bas du screehshot, aussi bien que le ipython style invite à indiquer que ces ptpython les capacités ont été sélectionnées (plus sur la façon de les sélectionner en un instant):
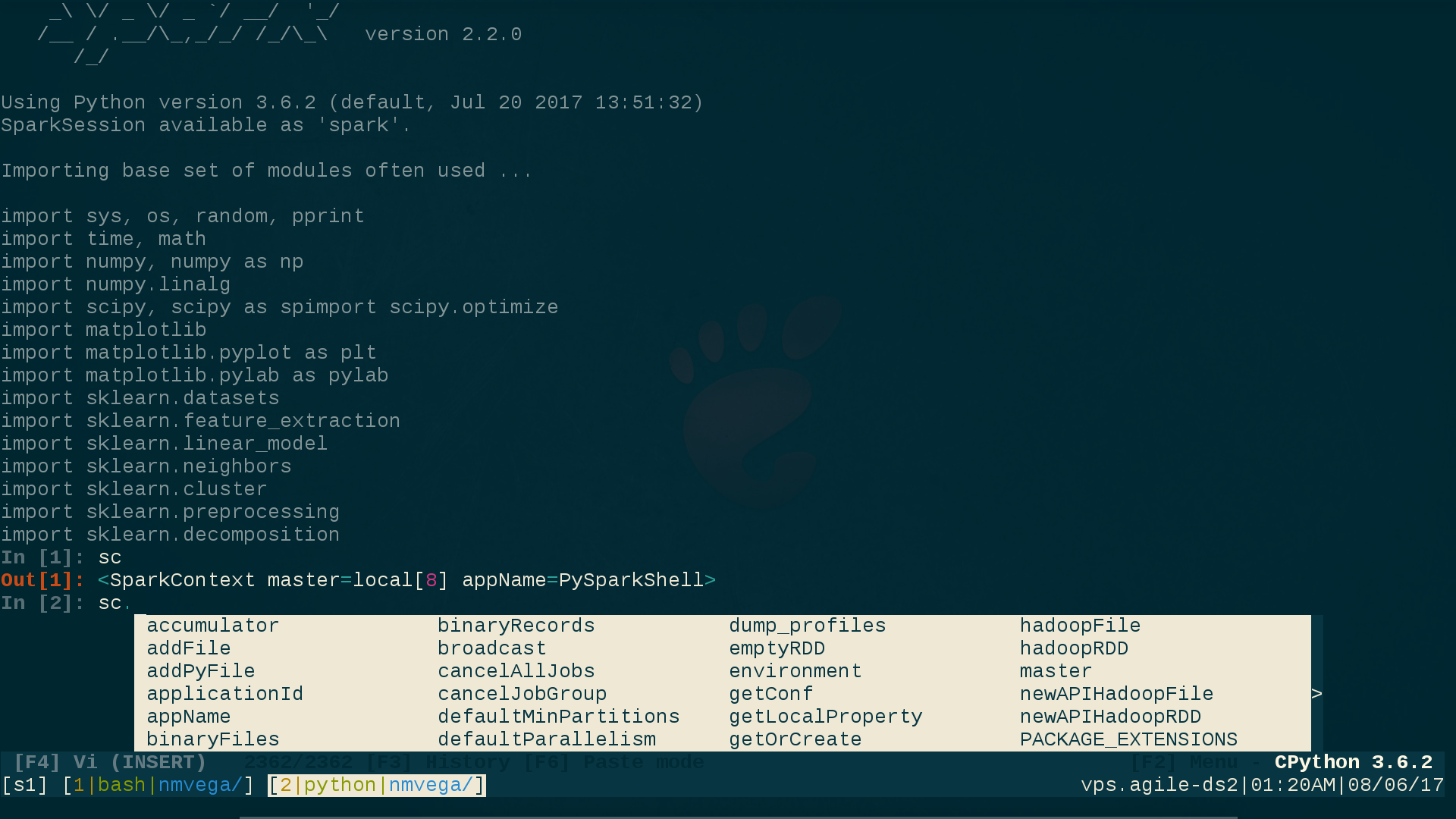
Pour obtenir tout cela, effectuez les étapes suivantes:
user@linux$ pip3 install ptpython # Everything here assumes Python3
user@linux$ vi ${SPARK_HOME}/conf/spark-env.sh
# Comment-out/disable the following two lines. This is necessary because
# they take precedence over any UNIX environment settings for them:
# PYSPARK_PYTHON=/path/to/python
# PYSPARK_DRIVER_PYTHON=/path/to/python
user@linux$ vi ${HOME}/.profile # Or whatever your login RC-file is.
# Add these two lines:
export PYSPARK_PYTHON=python3 # Fully-Qualify this if necessary. (python3)
export PYSPARK_DRIVER_PYTHON=ptpython3 # Fully-Qualify this if necessary. (ptpython3)
user@linux$ . ${HOME}/.profile # Source the RC file.
user@linux$ pyspark
# You are now running pyspark(1) within ptpython; a code pop-up/interactive
# shell; with your choice of vi(1) or emacs(1) key-bindings; and
# your choice of ipython functionality or not.
Pour sélectionner pypython préférences (et il y a un tas d'entre eux), appuyez simplement sur F2 à partir de dans un ptpython session et sélectionnez les options que vous voulez.
MOT DE LA FIN: si vous soumettez une application Python Spark (par opposition à interagir avec pyspark(1) via le CLI, comme indiqué ci-dessus), définissez simplement PYSPARK_PYTHON et PYSPARK_DRIVER_PYTHON par programmation en Python, comme suit:
os.environ['PYSPARK_PYTHON'] = 'python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'python3' # Not 'ptpython3' in this case.
j'espère que cette réponse et de configuration utiles.
Voici ce qui a fonctionné pour moi:
# if you run your ipython with 2.7 version with ipython2
# whatever you use for launching ipython shell should come after '=' sign
export PYSPARK_DRIVER_PYTHON=ipython2
et puis à partir du répertoire SPARK_HOME:
./bin/pyspark
selon le Github officiel, IPYTHON=1 N'est pas disponible en Spark 2.0+ Veuillez utiliser PYSPARK_PYTHON et PYSPARK_DRIVER_PYTHON à la place.
ce que j'ai trouvé utile est d'écrire des scripts bash qui chargent Spark d'une manière spécifique. Cela vous donnera un moyen facile de démarrer Spark dans différents environnements (par exemple ipython et un carnet jupyter).
pour ce faire, ouvrez un script vide (en utilisant l'éditeur de texte que vous préférez), par exemple un qui s'appelle ipython_spark.sh
Pour cet exemple, je vais donner le script que j'utilise pour ouvrir étincelle avec l'interpréteur ipython:
#!/bin/bash
export PYSPARK_DRIVER_PYTHON=ipython
${SPARK_HOME}/bin/pyspark \
--master local[4] \
--executor-memory 1G \
--driver-memory 1G \
--conf spark.sql.warehouse.dir="file:///tmp/spark-warehouse" \
--packages com.databricks:spark-csv_2.11:1.5.0 \
--packages com.amazonaws:aws-java-sdk-pom:1.10.34 \
--packages org.apache.hadoop:hadoop-aws:2.7.3
Notez que j'ai SPARK_HOME défini dans mon fichier bash_profile, mais vous pouvez simplement insérer le chemin complet à l'endroit où pyspark est situé sur votre ordinateur
j'aime mettre tous les scripts comme celui-ci en un seul endroit donc je mets ce fichier dans un dossier appelé "scripts"
Maintenant, pour cet exemple, vous devez aller à votre bash_profile et entrez les lignes suivantes:
export PATH=$PATH:/Users/<username>/scripts
alias ispark="bash /Users/<username>/scripts/ipython_spark.sh"
Ces chemins seront spécifiques à l'endroit où vous mettez ipython_spark.sh et vous pourriez avoir besoin de mettre à jour autorisations:
$ chmod 711 ipython_spark.sh
et la source de votre bash_profile:
$ source ~/.bash_profile
je suis sur un mac, mais cela devrait aussi fonctionner pour linux, bien que vous soyez en train de mettre à jour .bashrc au lieu de bash_profile très probablement.
ce que j'aime dans cette méthode, c'est que vous pouvez écrire plusieurs scripts, avec différentes configurations et ouvrir spark en conséquence. Selon que vous mettez en place un cluster, besoin de charger des paquets différents, ou changer le nombre de noyaux étincelle a il est à disposition, etc. vous pouvez soit mettre à jour ce script, soit en créer de nouveaux. Comme indiqué par @zero323 ci-dessus PYSPARK_DRIVER_PYTHON= est la syntaxe correcte pour Spark > 1.2 Je suis à l'aide de l'Étincelle 2.2
si la version de spark > = 2.0 et la configuration suivante peuvent être ajoutées .bashrc
export PYSPARK_PYTHON=/data/venv/your_env/bin/python
export PYSPARK_DRIVER_PYTHON=/data/venv/your_env/bin/ipython
aucune des réponses mentionnées n'a fonctionné pour moi. J'ai toujours eu l'erreur:
.../pyspark/bin/load-spark-env.sh: No such file or directory
Ce que j'ai fait a été le lancement d' ipython et la création de l'Étincelle session manuellement:
from pyspark.sql import SparkSession
spark = SparkSession\
.builder\
.appName("example-spark")\
.config("spark.sql.crossJoin.enabled","true")\
.getOrCreate()
pour éviter de faire cela à chaque fois, j'ai déplacé le code à ~/.ispark.py et créé l'alias (ajouter cette ~/.bashrc):
alias ipyspark="ipython -i ~/.ispark.py"
après cela, vous pouvez lancer PySpark avec iPython en tapant:
ipyspark