Comment itérer sur des lignes dans une DataFrame dans Pandas?
import pandas as pd
inp = [{'c1':10, 'c2':100}, {'c1':11,'c2':110}, {'c1':12,'c2':120}]
df = pd.DataFrame(inp)
print df
sortie:
c1 c2
0 10 100
1 11 110
2 12 120
maintenant je veux itérer au-dessus des lignes de ce cadre. Pour chaque ligne je veux pouvoir accéder à ses éléments (valeurs dans les cellules) par le nom des colonnes. Par exemple:
for row in df.rows:
print row['c1'], row['c2']
est-il possible de faire cela dans les pandas?
j'ai trouvé ce question similaire . Mais il ne me donne pas la réponse dont j'ai besoin. Par exemple, il est suggéré d'utiliser:
for date, row in df.T.iteritems():
ou
for row in df.iterrows():
mais je ne comprends pas ce qu'est l'objet row et comment je peux travailler avec lui.
14 réponses
iterrows est un générateur qui donnent à la fois l'indice et de la ligne
for index, row in df.iterrows():
print row['c1'], row['c2']
Output:
10 100
11 110
12 120
pour itérer à travers la ligne de DataFrame dans pandas on peut utiliser:
-
for index, row in df.iterrows(): print row["c1"], row["c2"] -
for row in df.itertuples(index=True, name='Pandas'): print getattr(row, "c1"), getattr(row, "c2")
itertuples() est censé être plus rapide que iterrows()
mais attention, selon les docs (pandas 0.21.1 à l'heure actuelle):
-
iterrows:
dtypepeut ne pas correspondre à la ligne à la ligneparce que iterrows retourne une série pour chaque ligne, il ne conserve pas les dtypes à travers les lignes (les dtypes sont conservés à travers les colonnes pour les images de données).
-
iterrows: Ne pas modifier les lignes
vous devriez ne jamais modifier quelque chose que vous êtes à parcourir. Ce n'est pas garanti dans tous les cas. Selon les types de données, l'itérateur renvoie une copie et non un point de vue, et l'écriture elle n'aura aucun effet.
Utiliser DataFrame.appliquer() au lieu de:
new_df = df.apply(lambda x: x * 2) -
itertuples:
les noms des colonnes seront renommés en les noms de position s'il s'agit d'identificateurs Python invalides, répétés ou commençant par un underscore. Avec un grand nombre de colonnes (>255), les tuples sont retournés.
alors que iterrows() est une bonne option, parfois itertuples() peut être beaucoup plus rapide:
df = pd.DataFrame({'a': randn(1000), 'b': randn(1000),'N': randint(100, 1000, (1000)), 'x': 'x'})
%timeit [row.a * 2 for idx, row in df.iterrows()]
# => 10 loops, best of 3: 50.3 ms per loop
%timeit [row[1] * 2 for row in df.itertuples()]
# => 1000 loops, best of 3: 541 µs per loop
vous pouvez également utiliser df.apply() pour itérer sur les lignes et accéder à plusieurs colonnes pour une fonction.
def valuation_formula(x, y):
return x * y * 0.5
df['price'] = df.apply(lambda row: valuation_formula(row['x'], row['y']), axis=1)
vous pouvez utiliser le df.fonction iloc comme suit:
for i in range(0, len(df)):
print df.iloc[i]['c1'], df.iloc[i]['c2']
je cherchais comment itérer sur les lignes et les colonnes et a fini ici ainsi:
for i, row in df.iterrows():
for j, column in row.iteritems():
print(column)
Utiliser itertuples() . Il est plus rapide que iterrows () :
for row in df.itertuples():
print "c1 :",row.c1,"c2 :",row.c2
pour boucler toutes les lignes dans un dataframe vous pouvez utiliser:
for x in range(len(date_example.index)):
print date_example['Date'].iloc[x]
vous pouvez écrire votre propre itérateur qui implémente namedtuple
from collections import namedtuple
def myiter(d, cols=None):
if cols is None:
v = d.values.tolist()
cols = d.columns.values.tolist()
else:
j = [d.columns.get_loc(c) for c in cols]
v = d.values[:, j].tolist()
n = namedtuple('MyTuple', cols)
for line in iter(v):
yield n(*line)
directement comparable à pd.DataFrame.itertuples . Je vise à accomplir la même tâche avec plus d'efficacité.
pour le dataframe donné avec ma fonction:
list(myiter(df))
[MyTuple(c1=10, c2=100), MyTuple(c1=11, c2=110), MyTuple(c1=12, c2=120)]
ou avec pd.DataFrame.itertuples :
list(df.itertuples(index=False))
[Pandas(c1=10, c2=100), Pandas(c1=11, c2=110), Pandas(c1=12, c2=120)]
un test complet
On essai de faire toutes les colonnes disponibles et. les colonnes.
def iterfullA(d):
return list(myiter(d))
def iterfullB(d):
return list(d.itertuples(index=False))
def itersubA(d):
return list(myiter(d, ['col3', 'col4', 'col5', 'col6', 'col7']))
def itersubB(d):
return list(d[['col3', 'col4', 'col5', 'col6', 'col7']].itertuples(index=False))
res = pd.DataFrame(
index=[10, 30, 100, 300, 1000, 3000, 10000, 30000],
columns='iterfullA iterfullB itersubA itersubB'.split(),
dtype=float
)
for i in res.index:
d = pd.DataFrame(np.random.randint(10, size=(i, 10))).add_prefix('col')
for j in res.columns:
stmt = '{}(d)'.format(j)
setp = 'from __main__ import d, {}'.format(j)
res.at[i, j] = timeit(stmt, setp, number=100)
res.groupby(res.columns.str[4:-1], axis=1).plot(loglog=True);
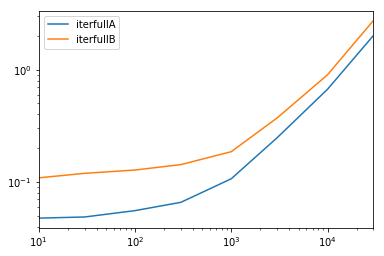
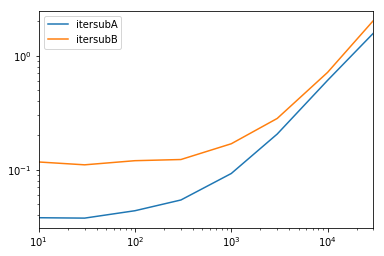
IMHO, la décision la plus simple
for ind in df.index:
print df['c1'][ind], df['c2'][ind]
pour boucler toutes les lignes dans un dataframe et utiliser les valeurs de chaque ligne commodément , namedtuples peuvent être converties en ndarray S. Par exemple:
df = pd.DataFrame({'col1': [1, 2], 'col2': [0.1, 0.2]}, index=['a', 'b'])
Itération sur les lignes:
for row in df.itertuples(index=False, name='Pandas'):
print np.asarray(row)
résultats dans:
[ 1. 0.1]
[ 2. 0.2]
veuillez noter que si index=True , l'indice est ajouté comme premier élément du tuple , qui peut être être indésirable pour certaines applications.
Ajouter aux réponses ci-dessus, parfois un modèle utile est:
# Borrowing @KutalmisB df example
df = pd.DataFrame({'col1': [1, 2], 'col2': [0.1, 0.2]}, index=['a', 'b'])
# The to_dict call results in a list of dicts
# where each row_dict is a dictionary with k:v pairs of columns:value for that row
for row_dict in df.to_dict(orient='records'):
print(row_dict)
qui se traduit par:
{'col1':1.0, 'col2':0.1}
{'col1':2.0, 'col2':0.2}
pourquoi compliquer les choses?
Simple.
import pandas as pd
import numpy as np
# Here is an example dataframe
df_existing = pd.DataFrame(np.random.randint(0,100,size=(100, 4)), columns=list('ABCD'))
for idx,row in df_existing.iterrows():
print row['A'],row['B'],row['C'],row['D']
vous pouvez également faire numpy indexation pour des vitesses encore plus grandes. Ce n'est pas vraiment itératif mais fonctionne beaucoup mieux que l'itération pour certaines applications.
subset = row['c1'][0:5]
all = row['c1'][:]
vous pouvez aussi vouloir le lancer à un tableau. Ces index / sélections sont censés agir déjà comme des tableaux vides, mais j'ai rencontré des problèmes et j'ai dû lancer
np.asarray(all)
imgs[:] = cv2.resize(imgs[:], (224,224) ) #resize every image in an hdf5 file