Comment améliorer l'emplacement de l'étiquette pour matplotlib scatter chart (code,algorithme,tips)?
j'utilise matplotlib pour tracer un diagramme de dispersion:
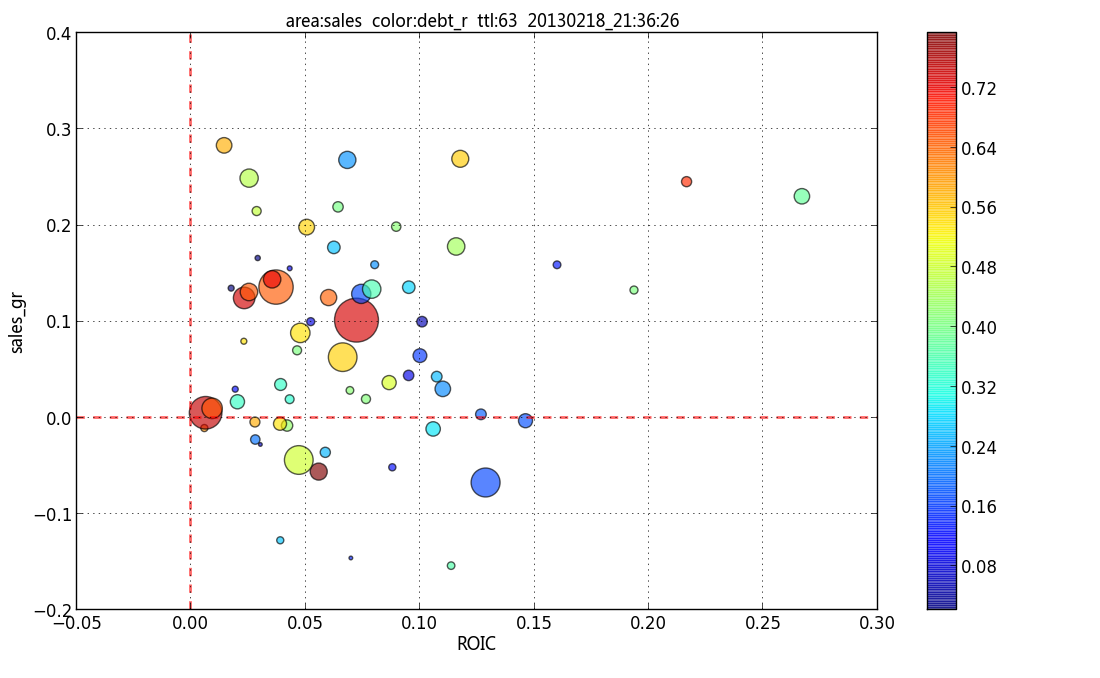
et étiqueter la bulle à l'aide d'une boîte transparente selon la pointe à matplotlib: comment Annoter le point sur une flèche scatter placée automatiquement?
voici le code:
if show_annote:
for i in range(len(x)):
annote_text = annotes[i][0][0] # STK_ID
ax.annotate(annote_text, xy=(x[i], y[i]), xytext=(-10,3),
textcoords='offset points', ha='center', va='bottom',
bbox=dict(boxstyle='round,pad=0.2', fc='yellow', alpha=0.2),
fontproperties=ANNOTE_FONT)
et la parcelle qui en résulte:
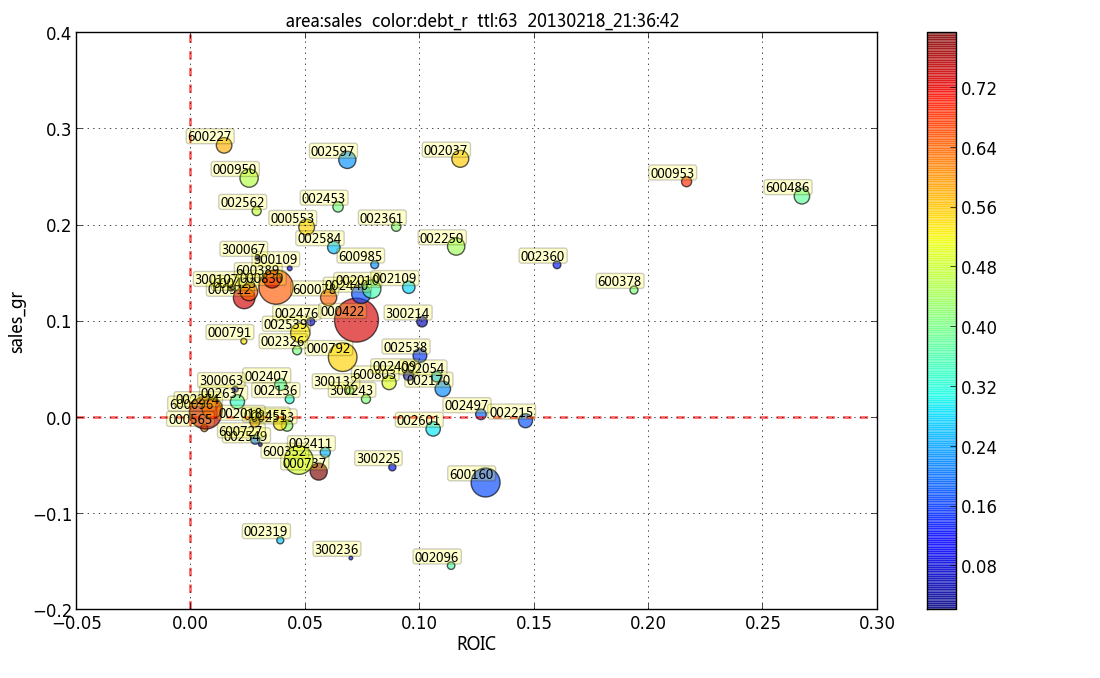
mais il y a encore de la place pour une amélioration visant à réduire le chevauchement (par exemple, le décalage de la boîte étiquette est fixé à (-10,3)). Y a-t-il des algorithmes qui peuvent:
- modifier dynamiquement l'offset de la boîte d'étiquette en fonction de l'encombrement de son voisinage
- placer dynamiquement la boîte d'étiquette à distance et ajouter une ligne de flèche entre la bulle et la boîte d'étiquette
- modifier quelque peu l'orientation de l'étiquette
- est mieux que label_box chevauchement label_box?
je veux juste rendre la carte facile à comprendre pour les yeux humains, donc un certain chevauchement est OK, pas une contrainte aussi rigide que http://en.wikipedia.org/wiki/Automatic_label_placement suggère. Et la quantité de bulles dans la carte est moins de 150 la plupart du temps.
je trouve le soi-disant Force-based label placement http://bl.ocks.org/MoritzStefaner/1377729 est assez intéressant. Je ne sais pas s'il y a un code/paquet python disponible pour implémenter l'algorithme.
Je ne suis pas un gars académique et ne cherche pas une solution optimale, et mes codes python ont besoin d'étiqueter de nombreuses cartes, de sorte que la vitesse/mémoire est dans la portée de la considération.
je cherche une solution rapide et efficace. Y a-t-il de l'aide (code,algorithme,conseils,pensées) sur ce sujet? Grâce.
3 réponses
il est un peu rugueux autour des bords (Je ne peux pas tout à fait comprendre comment mettre à l'échelle les forces relatives du réseau de ressort par rapport à la force de répulsion, et la boîte de limite est un peu vissée), mais c'est un bon début:
import networkx as nx
N = 15
scatter_data = rand(3, N)
G=nx.Graph()
data_nodes = []
init_pos = {}
for j, b in enumerate(scatter_data.T):
x, y, _ = b
data_str = 'data_{0}'.format(j)
ano_str = 'ano_{0}'.format(j)
G.add_node(data_str)
G.add_node(ano_str)
G.add_edge(data_str, ano_str)
data_nodes.append(data_str)
init_pos[data_str] = (x, y)
init_pos[ano_str] = (x, y)
pos = nx.spring_layout(G, pos=init_pos, fixed=data_nodes)
ax = gca()
ax.scatter(scatter_data[0], scatter_data[1], c=scatter_data[2], s=scatter_data[2]*150)
for j in range(N):
data_str = 'data_{0}'.format(j)
ano_str = 'ano_{0}'.format(j)
ax.annotate(ano_str,
xy=pos[data_str], xycoords='data',
xytext=pos[ano_str], textcoords='data',
arrowprops=dict(arrowstyle="->",
connectionstyle="arc3"))
all_pos = np.vstack(pos.values())
mins = np.min(all_pos, 0)
maxs = np.max(all_pos, 0)
ax.set_xlim([mins[0], maxs[0]])
ax.set_ylim([mins[1], maxs[1]])
draw()
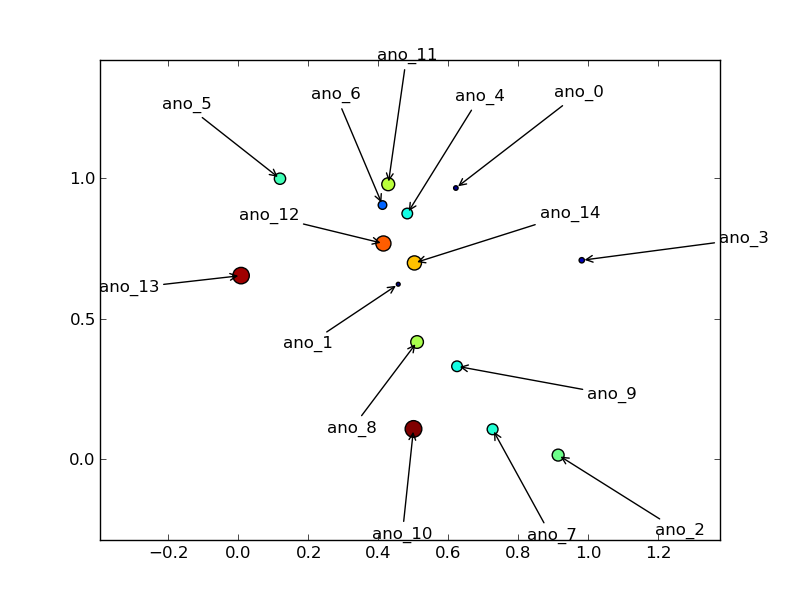
comment cela fonctionne dépend un peu de la façon dont vos données sont regroupées.
s'appuie sur tcaswell la réponse de .
Les méthodes de mise en page Networkx telles que nx.spring_layout modifient les positions de manière à ce qu'elles s'inscrivent toutes dans un carré unitaire (par défaut). Même la position du fixe data_nodes est rééchelonnée. Ainsi, pour appliquer le pos à l'original scatter_data , il faut effectuer un détartrage et un dévissage.
Notez aussi que nx.spring_layout a un paramètre k qui contrôle la distance optimale entre les noeuds. k augmente, la distance des annotations dans les points de données.
import numpy as np
import matplotlib.pyplot as plt
import networkx as nx
np.random.seed(2016)
N = 20
scatter_data = np.random.rand(N, 3)*10
def repel_labels(ax, x, y, labels, k=0.01):
G = nx.DiGraph()
data_nodes = []
init_pos = {}
for xi, yi, label in zip(x, y, labels):
data_str = 'data_{0}'.format(label)
G.add_node(data_str)
G.add_node(label)
G.add_edge(label, data_str)
data_nodes.append(data_str)
init_pos[data_str] = (xi, yi)
init_pos[label] = (xi, yi)
pos = nx.spring_layout(G, pos=init_pos, fixed=data_nodes, k=k)
# undo spring_layout's rescaling
pos_after = np.vstack([pos[d] for d in data_nodes])
pos_before = np.vstack([init_pos[d] for d in data_nodes])
scale, shift_x = np.polyfit(pos_after[:,0], pos_before[:,0], 1)
scale, shift_y = np.polyfit(pos_after[:,1], pos_before[:,1], 1)
shift = np.array([shift_x, shift_y])
for key, val in pos.items():
pos[key] = (val*scale) + shift
for label, data_str in G.edges():
ax.annotate(label,
xy=pos[data_str], xycoords='data',
xytext=pos[label], textcoords='data',
arrowprops=dict(arrowstyle="->",
shrinkA=0, shrinkB=0,
connectionstyle="arc3",
color='red'), )
# expand limits
all_pos = np.vstack(pos.values())
x_span, y_span = np.ptp(all_pos, axis=0)
mins = np.min(all_pos-x_span*0.15, 0)
maxs = np.max(all_pos+y_span*0.15, 0)
ax.set_xlim([mins[0], maxs[0]])
ax.set_ylim([mins[1], maxs[1]])
fig, ax = plt.subplots()
ax.scatter(scatter_data[:, 0], scatter_data[:, 1],
c=scatter_data[:, 2], s=scatter_data[:, 2] * 150)
labels = ['ano_{}'.format(i) for i in range(N)]
repel_labels(ax, scatter_data[:, 0], scatter_data[:, 1], labels, k=0.008)
plt.show()
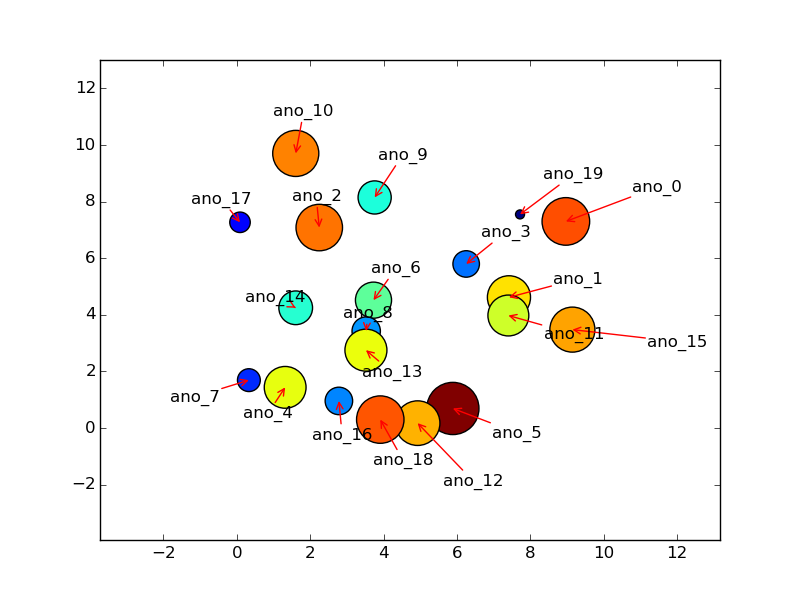
avec k=0.011 yields
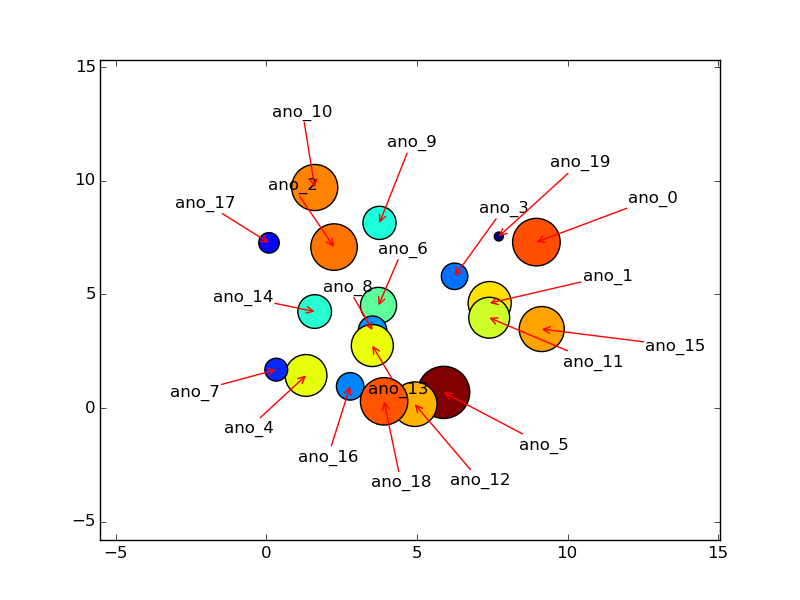 et avec
et avec k=0.008 rendements
une autre option utilisant Ma bibliothèque adjustText , écrite spécialement à cet effet ( https://github.com/Phlya/adjustText ).
from adjustText import adjust_text
np.random.seed(2016)
N = 50
scatter_data = np.random.rand(N, 3)
fig, ax = plt.subplots()
ax.scatter(scatter_data[:, 0], scatter_data[:, 1],
c=scatter_data[:, 2], s=scatter_data[:, 2] * 150)
labels = ['ano_{}'.format(i) for i in range(N)]
texts = []
for x, y, text in zip(scatter_data[:, 0], scatter_data[:, 1], labels):
texts.append(ax.text(x, y, text))
plt.show()

np.random.seed(2016)
N = 50
scatter_data = np.random.rand(N, 3)
fig, ax = plt.subplots()
ax.scatter(scatter_data[:, 0], scatter_data[:, 1],
c=scatter_data[:, 2], s=scatter_data[:, 2] * 150)
labels = ['ano_{}'.format(i) for i in range(N)]
texts = []
for x, y, text in zip(scatter_data[:, 0], scatter_data[:, 1], labels):
texts.append(ax.text(x, y, text))
adjust_text(texts, force_text=0.05, arrowprops=dict(arrowstyle="-|>",
color='r', alpha=0.5))
plt.show()

il ne repousse pas des bulles, seulement de leurs centres et d'autres textes.