Comment importer des données de fichier CSV dans une table PostgreSQL?
Comment puis-je écrire une procédure stockée qui importe des données à partir d'un fichier CSV et remplit la table?
13 réponses
Regardez ce short article .
Solution paraphrasée ici:
créez votre table:
CREATE TABLE zip_codes
(ZIP char(5), LATITUDE double precision, LONGITUDE double precision,
CITY varchar, STATE char(2), COUNTY varchar, ZIP_CLASS varchar);
Copiez les données de votre fichier CSV à la table:
COPY zip_codes FROM '/path/to/csv/ZIP_CODES.txt' WITH (FORMAT csv);
si vous n'avez pas la permission d'utiliser COPY (qui fonctionne sur le serveur db), vous pouvez utiliser \copy à la place (qui fonctionne dans le client db). En utilisant le même exemple que Bozhidar Batsov:
créez votre table:
CREATE TABLE zip_codes
(ZIP char(5), LATITUDE double precision, LONGITUDE double precision,
CITY varchar, STATE char(2), COUNTY varchar, ZIP_CLASS varchar);
Copiez les données de votre fichier CSV à la table:
\copy zip_codes FROM '/path/to/csv/ZIP_CODES.txt' DELIMITER ',' CSV
vous pouvez également spécifier les colonnes à lire:
\copy zip_codes(ZIP,CITY,STATE) FROM '/path/to/csv/ZIP_CODES.txt' DELIMITER ',' CSV
une façon rapide de faire cela est avec la bibliothèque pandas de Python (la version 0.15 ou supérieure fonctionne le mieux). Cela gérera la création des colonnes pour vous - bien qu'évidemment les choix qu'il fait pour les types de données pourraient ne pas être ce que vous voulez. Si elle ne fait pas tout à fait ce que vous voulez, vous pouvez toujours utiliser le code 'create table' généré comme modèle.
voici un exemple simple:
import pandas as pd
df = pd.read_csv('mypath.csv')
df.columns = [c.lower() for c in df.columns] #postgres doesn't like capitals or spaces
from sqlalchemy import create_engine
engine = create_engine('postgresql://username:password@localhost:5432/dbname')
df.to_sql("my_table_name", engine)
et voici un peu de code qui vous montre comment définir divers options:
#Set is so the raw sql output is logged
import logging
logging.basicConfig()
logging.getLogger('sqlalchemy.engine').setLevel(logging.INFO)
df.to_sql("my_table_name2",
engine,
if_exists="append", #options are ‘fail’, ‘replace’, ‘append’, default ‘fail’
index=False, #Do not output the index of the dataframe
dtype={'col1': sqlalchemy.types.NUMERIC,
'col2': sqlalchemy.types.String}) #Datatypes should be [sqlalchemy types][1]
vous pouvez également utiliser pgAdmin, qui offre une interface graphique pour faire l'importation. C'est montré dans ce ainsi fil . L'avantage d'utiliser pgAdmin est qu'il fonctionne aussi pour les bases de données distantes.
comme les solutions précédentes, vous auriez besoin d'avoir votre table sur la base de données déjà. Chaque personne a sa propre solution, mais ce que je fais habituellement est d'ouvrir le CSV dans Excel, copier les en-têtes, coller spécial avec transposition sur une feuille de travail différente, placez le type de données correspondant sur la colonne suivante puis juste copier et coller cela à un éditeur de texte avec la requête de création de table SQL appropriée comme so:
CREATE TABLE my_table (
/*paste data from Excel here for example ... */
col_1 bigint,
col_2 bigint,
/* ... */
col_n bigint
)
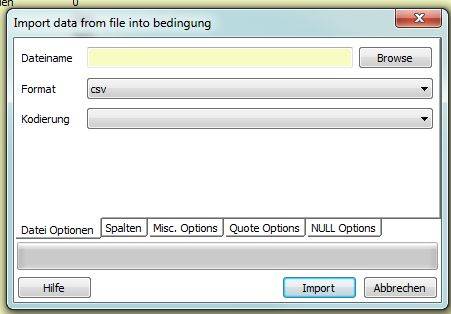
comme Paul l'a mentionné, importer des œuvres dans pgAdmin:
clic droit sur la table - > importer
sélectionner fichier local, format et codage
voici une capture d'écran allemande de pgAdmin GUI:
chose similaire que vous pouvez faire avec DbVisualizer (j'ai une licence, pas sûr de la version libre)
clic droit sur une table -> Importer Des Données De La Table...
la plupart des autres solutions ici exigent que vous créiez la table à l'avance/manuellement. Cela peut ne pas être pratique dans certains cas (par exemple, si vous avez beaucoup de colonnes dans la table de destination). Ainsi, l'approche ci-dessous peut être pratique.
en fournissant le chemin et le nombre de colonnes de votre fichier csv, vous pouvez utiliser la fonction suivante pour charger votre table à une table temp qui sera nommée comme target_table :
la rangée du haut est supposée avoir la colonne nom.
create or replace function data.load_csv_file
(
target_table text,
csv_path text,
col_count integer
)
returns void as $$
declare
iter integer; -- dummy integer to iterate columns with
col text; -- variable to keep the column name at each iteration
col_first text; -- first column name, e.g., top left corner on a csv file or spreadsheet
begin
set schema 'your-schema';
create table temp_table ();
-- add just enough number of columns
for iter in 1..col_count
loop
execute format('alter table temp_table add column col_%s text;', iter);
end loop;
-- copy the data from csv file
execute format('copy temp_table from %L with delimiter '','' quote ''"'' csv ', csv_path);
iter := 1;
col_first := (select col_1 from temp_table limit 1);
-- update the column names based on the first row which has the column names
for col in execute format('select unnest(string_to_array(trim(temp_table::text, ''()''), '','')) from temp_table where col_1 = %L', col_first)
loop
execute format('alter table temp_table rename column col_%s to %s', iter, col);
iter := iter + 1;
end loop;
-- delete the columns row
execute format('delete from temp_table where %s = %L', col_first, col_first);
-- change the temp table name to the name given as parameter, if not blank
if length(target_table) > 0 then
execute format('alter table temp_table rename to %I', target_table);
end if;
end;
$$ language plpgsql;
COPY table_name FROM 'path/to/data.csv' DELIMITER ',' CSV HEADER;
expérience Personnelle avec PostgreSQL, toujours en attente d'un moyen plus rapide.
1. Créer le squelette de la table d'abord si le fichier est stocké localement:
drop table if exists ur_table;
CREATE TABLE ur_table
(
id serial NOT NULL,
log_id numeric,
proc_code numeric,
date timestamp,
qty int,
name varchar,
price money
);
COPY
ur_table(id, log_id, proc_code, date, qty, name, price)
FROM '\path\xxx.csv' DELIMITER ',' CSV HEADER;
2. Lorsque le \ path\xxx.csv est sur le serveur, postgreSQL n'a pas le l'autorisation d'accès au serveur, vous devez importer le .fichier csv à travers la fonctionnalité pgAdmin intégrée.
clic droit sur le nom de la table choisir importer.
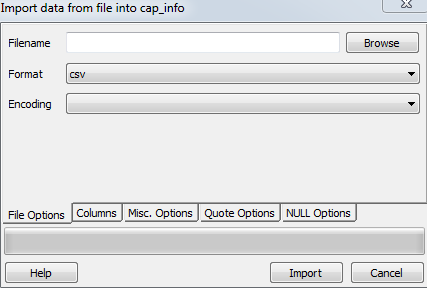
si vous avez encore un problème, reportez-vous à ce tutoriel. http://www.postgresqltutorial.com/import-csv-file-into-posgresql-table /
utilisez ce code SQL
copy table_name(atribute1,attribute2,attribute3...)
from 'E:\test.csv' delimiter ',' csv header
le mot-clé header permet au SGBD de savoir que le fichier csv a un en-tête avec des attributs
pour plus de visite http://www.postgresqltutorial.com/import-csv-file-into-posgresql-table /
IMHO, la manière la plus commode est de suivre " importer des données CSV dans postgresql, la manière confortable ;-) ", en utilisant csvsql de csvkit , qui est un paquet python installable via pip.
-
créez une première table
-
ensuite, utilisez la commande Copier pour copier les détails de la table:
copy table_name (C1,C2,C3....)
de 'chemin d'accès à votre fichier csv' délimiteur ',' csv en-tête;
Merci
créer la table et avoir les colonnes nécessaires qui sont utilisées pour créer la table dans le fichier csv.
-
ouvrir la table postgres et clic droit sur la table cible que vous voulez charger et sélectionner Importer et mettre à jour les étapes suivantes dans file options section
-
maintenant, parcourez votre fichier en nom de fichier
-
sélectionner csv dans le format
-
Encodage ISO_8859_5
Maintenant goto Divers. options et cochez en-tête et cliquez sur Importer.
si vous avez besoin d'un mécanisme simple pour importer du texte / parse multiligne CSV vous pouvez utiliser:
CREATE TABLE t -- OR INSERT INTO tab(col_names)
AS
SELECT
t.f[1] AS col1
,t.f[2]::int AS col2
,t.f[3]::date AS col3
,t.f[4] AS col4
FROM (
SELECT regexp_split_to_array(l, ',') AS f
FROM regexp_split_to_table(
$$a,1,2016-01-01,bbb
c,2,2018-01-01,ddd
e,3,2019-01-01,eee$$, '\n') AS l) t;