Comment gérer les connexions SQLAlchemy dans ProcessPool?
J'ai un réacteur qui récupère les messages d'un courtier RabbitMQ et déclenche des méthodes de travail pour traiter ces messages dans un pool de processus, quelque chose comme ceci:
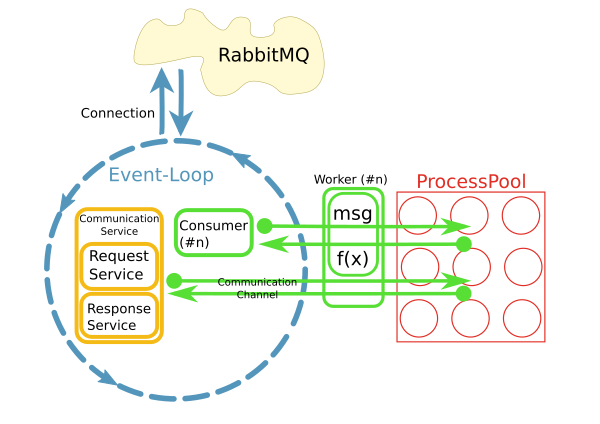
Ceci est implémenté en utilisant python asyncio, loop.run_in_executor() et concurrent.futures.ProcessPoolExecutor.
Maintenant, je veux accéder à la base de données dans les méthodes de travail en utilisant SQLAlchemy. La plupart du temps, le traitement sera des opérations CRUD très simples et rapides.
Le réacteur traitera 10-50 messages par seconde dans le en commençant, il n'est donc pas acceptable d'ouvrir une nouvelle connexion à la base de données pour chaque requête. Au contraire, je voudrais maintenir une connexion persistante par processus.
Mes questions sont: Comment puis-je faire cela? Puis-je stocker dans une variable globale? Le pool de connexion SQA va-t-il gérer cela pour moi? Comment nettoyer lorsque le réacteur s'arrête?
[mise à Jour]
- La base de données est MySQL avec InnoDB.
Pourquoi choisir ce modèle avec un processus piscine?
L'implémentation actuelle utilise un modèle différent où chaque consommateur s'exécute dans son propre thread. D'une certaine manière cela ne fonctionne pas très bien. Il y a déjà environ 200 consommateurs chacun fonctionnant dans leur propre fil, et le système se développe rapidement. Pour mieux évoluer, l'idée était de séparer les préoccupations et de consommer des messages dans une boucle d'E/S et de déléguer le traitement à un pool. Bien sûr, la performance de l'ensemble du système est principalement liée aux E/S. Cependant, CPU est un problème lorsque traitement de grands ensembles de résultats.
L'autre raison était " facilité d'utilisation."Alors que la gestion de la connexion et la consommation des messages sont implémentées de manière asynchrone, le code dans le worker peut être synchrone et simple.
Il est vite devenu évident que l'accès à des systèmes distants via des connexions réseau persistantes à partir du worker pose problème. C'est ce que les CommunicationChannels sont pour: à l'intérieur du travailleur, je peux accorder des demandes au bus de messages à travers ceux-ci canal.
Une de mes idées actuelles est de gérer L'accès à la base de données de la même manière: passer des instructions à travers une file d'attente à la boucle d'événement où elles sont envoyées à la base de données. Cependant, je n'ai aucune idée de comment faire cela avec SQLAlchemy.
Où serait le point d'entrée?
Les objets doivent être pickled lorsqu'ils sont passés dans une file d'attente. Comment puis-je obtenir un tel objet à partir d'une requête SQA?
La communication avec la base de données doit fonctionner de manière asynchrone afin de ne pas bloquer la boucle d'événement. Puis-je utiliser par exemple aiomysql comme pilote de base de données pour SQA?
3 réponses
Votre Exigence de une connexion de base de données par processus de pool de processus peut être facilement satisfaite si vous prenez soin de la façon dont vous instanciez le session, en supposant que vous travaillez avec l'orm, dans les processus de travail.
Une solution simple serait d'avoir une session globale {[14] } que vous réutilisez entre les requêtes:
# db.py
engine = create_engine("connection_uri", pool_size=1, max_overflow=0)
DBSession = scoped_session(sessionmaker(bind=engine))
Et sur la tâche de travail:
# task.py
from db import engine, DBSession
def task():
DBSession.begin() # each task will get its own transaction over the global connection
...
DBSession.query(...)
...
DBSession.close() # cleanup on task end
Arguments pool_size et max_overflow personnaliser la valeur par défaut QueuePool utilisé par create_engine.pool_size s'assurera que votre processus ne conserve que 1 connexion active par processus dans le pool de processus.
Si vous voulez qu'il se reconnecte, vous pouvez utiliser DBSession.remove() qui supprimera la session du registre et la reconnectera à la prochaine utilisation de DBSession. Vous pouvez également utiliser l'argument recycle dePool pour reconnecter la connexion après la durée spécifiée.
Pendant le développement / débogage, vous pouvez utiliser AssertionPool qui déclenchera un exception si plus d'une connexion est extraite du pool, consultez implémentations de pool de commutation sur la façon de le faire.
@ roman: beau défi que vous avez là.
J'ai déjà été dans un scénario similaire alors voici mes 2 cents: à moins que ce consommateur ne"lise" et"écrive" le message, sans en faire un traitement réel, vous pouvez re-concevoir ce consommateur en tant que consommateur/producteur qui va consommer le message, il traitera le message et, cette file d'attente (messages traités par exemple) pourrait être lue par 1..Et les processus asynchrones Non regroupés qui auraient ouvert la connexion DB dans son propre cycle de vie entier.
Je peux étendre ma réponse, mais je ne sais pas si cette approche correspond à vos besoins, si oui, je peux vous donner plus de détails sur la conception étendue.
Une approche qui m'a vraiment bien servi est d'utiliser un serveur web pour gérer et mettre à l'échelle le pool de processus. flask-sqlalchemy, même dans son état par défaut, conservera un pool de connexions et ne fermera pas chaque connexion à chaque cycle de réponse de requête.
L'exécuteur asyncio peut simplement appeler des points de terminaison d'url pour exécuter vos fonctions. L'avantage supplémentaire est que, parce que tous les processus effectuant le travail sont derrière une url, vous pouvez trivialement mettre à l'échelle votre pool de travailleurs sur plusieurs machines, en ajoutant plus processus via gunicorn ou l'une des nombreuses autres méthodes pour mettre à l'échelle un serveur WSGI simple. De plus, vous obtenez toute la bonté tolérante aux pannes.
L'inconvénient est que vous pourriez transmettre plus d'informations sur le réseau. Cependant, comme vous le dites, le problème est lié au processeur et vous passerez probablement beaucoup plus de données vers et depuis la base de données.