Comment activer les exceptions d'alignement pour mon processus sur x64?
Je suis curieux de voir si mon application 64 bits souffre de défauts d'alignement.
Depuis alignement des données Windows sur IPF, x86 et x64 :
Sous Windows, un programme d'application qui génère une erreur d'alignement déclenche une exception,
EXCEPTION_DATATYPE_MISALIGNMENT.
- sur l'architecture x64 , les exceptions d'alignement sont désactivées par défaut et les correctifs sont effectués par le matériel. l'application peut activer les exceptions d'alignement en définissant quelques bits de registre, dans ce cas, les exceptions seront déclenchées à moins que le système d'exploitation ne masque les exceptions avec
SEM_NOALIGNMENTFAULTEXCEPT. (Pour plus de détails, voir le manuel du AMD Architecture Programmer's Manual Volume 2: System Programming.)[Ed. j'insiste]
Sur l'architecture x86, le système d'exploitation ne prend pas en faire l'alignement de défaut visible à l'application. Sur ces deux plates-formes, vous subirez également une dégradation des performances sur le défaut d'alignement, mais il sera nettement moins grave que sur L'Itanium, car le matériel fera les multiples accès de mémoire pour récupérer les données non alignées.
Sur Itanium , par défaut, le système d'exploitation (OS) rendra cette exception visible pour l'application, et un gestionnaire de terminaison peut être utile dans ces cas. Si vous ne configurez pas de gestionnaire, votre programme se bloque ou se bloque. Dans la liste 3, Nous fournissons un exemple qui montre comment attraper L'exception EXCEPTION_DATATYPE_MISALIGNMENT.
Ignorant la direction de consulter le AMD architecture Programmer's Manual , je vais plutôt consulter le Intel 64 et IA-32 Architectures Software Developer's Manual
5.10.5 Vérification De L'Alignement
Lorsque le CPL est 3, l'alignement des références de mémoire peut être vérifié en Drapeau AM dans le CR0 enregistrer et le drapeau AC dans le registre EFLAGS. Non alignés de la mémoire les références génèrent des exceptions d'alignement (#AC). Le processeur ne génère pas exceptions d'alignement lorsque vous travaillez au niveau de privilège 0, 1 ou 2. Voir tableau 6-7 pour a description des exigences d'alignement lorsque la vérification de l'alignement est activée.
Excellente. Je ne sais pas ce que cela signifie, Mais excellent.
Ensuite, il y a aussi:
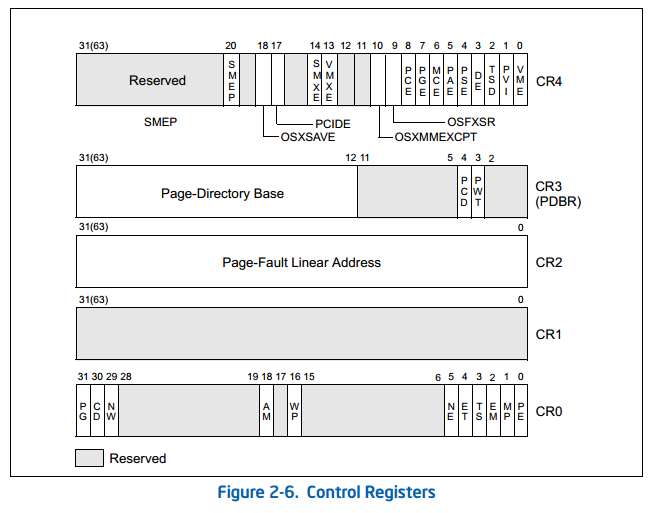
2.5 REGISTRES DE CONTRÔLE
Contrôle les registres (CR0, CR1, CR2, CR3 et CR4; voir Figure 2-6) déterminent le fonctionnement mode du processeur et les caractéristiques de la tâche en cours d'exécution. Ces registres sont 32 bits dans tous les modes 32 bits et le mode de compatibilité.
En mode 64 bits, les registres de contrôle sont étendus à 64 bits. Les instructions MOV CRn sont utilisés pour manipuler les bits de registre. Préfixes de taille d'opérande pour ces instructions sont ignorés.
Les registres de contrôle sont résumés ci-dessous, et chaque contrôle défini architecturalement champ dans ces registres de contrôle sont décrits individuellement. Dans la Figure 2-6, la largeur de le registre en mode 64 bits est indiqué entre parenthèses (sauf pour CR0). - CR0 - contient des indicateurs de contrôle du système qui contrôlent le mode de fonctionnement et les états de le processeur
SUIS
l'Alignement de Masque (18 bits de CR0) - Permet l'alignement automatique de la vérification lorsque défini; désactive vérification de l'alignement lorsqu'il est clair. La vérification de l'alignement est effectué uniquement lorsque L'indicateur AM est défini, l'indicateur AC dans le registre EFLAGS est ensemble, CPL est 3, et le processeur fonctionne dans protégé ou virtuel- Mode 8086.
J'ai essayé
La langue que j'utilise actuellement est Delphi, mais prétends que c'est un pseudocode agnostique de la langue:
void UnmaskAlignmentExceptions()
{
asm
mov rax, cr0; //copy CR0 flags into RAX
or rax, 0x20000; //set bit 18 (AM)
mov cr0, rax; //copy flags back
}
La première instruction
mov rax, cr0;
Échoue avec une exception D'Instruction privilégiée.
Comment activer exceptions d'alignement pour mon processus sur x64?
PUSHF
, j'ai découvert que le x86 a l'instruction:
-
PUSHF,POPF: Push / pop premiers 16 bits de EFLAGS sur / hors de la pile -
PUSHFD,POPFD: Push / pop tous les 32 bits de EFLAGS sur / hors de la pile
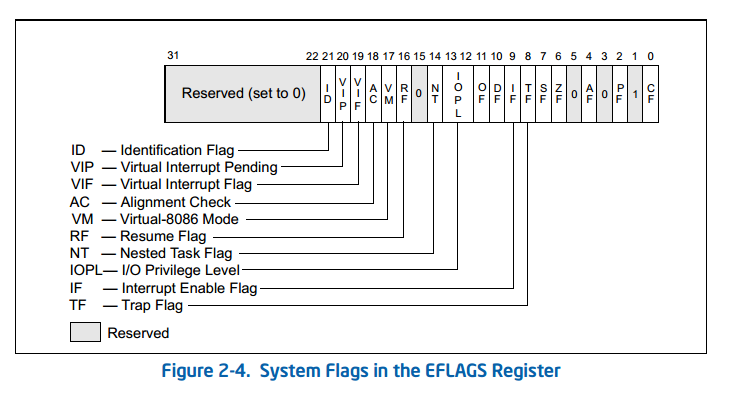
Cela m'a ensuite conduit à la version x64:
-
PUSHFQ,POPFQ: poussez / pop le quad RFLAGS sur / hors de la pile
(dans le monde 64 bits, les EFLAGS sont renommés RFLAGS).
J'ai Donc écrit:
void EnableAlignmentExceptions;
{
asm
PUSHFQ; //Push RFLAGS quadword onto the stack
POP RAX; //Pop them flags into RAX
OR RAX, $20000; //set bit 18 (AC=Alignment Check) of the flags
PUSH RAX; //Push the modified flags back onto the stack
POPFQ; //Pop the stack back into RFLAGS;
}
Et il n'a pas planté ou déclenché une exception de protection. Je n'ai aucune idée si elle fait ce que je veux.
Lecture Bonus
- comment attraper les défauts d'alignement de données sur x86 (AKA SIGBUS sur Sparc) (question sans rapport; x86 pas x64, Ubunutu pas Windows, gcc vs pas)
3 réponses
Les Applications exécutées sur x64 ont accès à un registre de drapeau (parfois appelé EFLAGS). Le Bit 18 de ce registre permet aux applications d'obtenir des exceptions lorsque des erreurs d'alignement se produisent. Donc, en théorie, tout un programme a faire pour activer les exceptions pour les erreurs d'alignement est de modifier le registre des drapeaux.
Cependant
Pour que cela fonctionne réellement, le noyau du système d'exploitation doit définir le bit 18 de cr0 pour l'autoriser. Et le système D'exploitation Windows ne fait pas que. Pourquoi pas? Qui sait?
Les Applications ne peuvent pas définir de valeurs dans le registre de contrôle. Seulement le noyau peut le faire. Les pilotes de périphériques s'exécutent à l'intérieur du noyau, afin qu'ils puissent définir cela aussi.
Il est possible d'essayer de faire fonctionner cela en créant un pilote de périphérique (voir http://blogs.msdn.com/b/oldnewthing/archive/2004/07/27/198410.aspx#199239 et les commentaires qui suivent). Notez que ce post a plus d'une décennie, donc certains des liens sont morts.
Vous pourrait également trouver ce commentaire (et certaines des autres réponses à cette question) pour être utile:
Larry Osterman - 07-28-2004 2:22 SUIS -
Nous avons en fait construit une version de NT avec des exceptions d'alignement activées pour x86 (Vous pouvez le faire comme Skywing l'a mentionné).
Nous l'avons rapidement éteint, en raison du nombre d'applications qui ont cassé:)
Cela fonctionne dans le processeur Intel 64 bits. Peut échouer dans certains AMD
pushfq
bts qword ptr [rsp], 12h ; reset AC bit of rflags
popfq
Cela ne fonctionnera pas tout de suite dans les processeurs 32 bits, ceux-ci nécessiteront d'abord un pilote de noyau pour changer le bit AM de CR0, puis
pushfd
bts dword ptr [esp], 12h
popfd
Comme alternative à AC pour trouver des ralentissements dus à des accès non alignés, vous pouvez utiliser les événements de compteur de performances matérielles sur les processeurs Intel pour mem_inst_retired.split_loads et mem_inst_retired.split_stores pour trouver des charges/magasins qui se divisent sur une limite de ligne de cache.
perf record -c 10 -e mem_inst_retired.split_stores,mem_inst_retired.split_loads ./a.out devrait être utile sur Linux. -c 10 enregistre un échantillon tous les 10 événements HW. Si votre programme fait un lot d'accès non alignés et que vous voulez seulement trouver les vrais hotspots, laissez-le à la valeur par défaut. Mais -c 10 peut devenir utile données même sur un petit binaire qui appelle printf une fois. D'autres options perf comme -g pour enregistrer les fonctions parentes sur chaque exemple fonctionnent comme d'habitude, et pourraient être utiles.
Sous Windows, utilisez l'outil que vous préférez pour regarder les compteurs perf. VTune est populaire.
Les processeurs Intel modernes (famille P6 et plus récents) n'ont pas de pénalité pour désalignement dans une ligne de cache . https://agner.org/optimize/. en fait, de telles charges/magasins sont même garanties d'être atomique (jusqu'à 8 octets), sur les Processeurs Intel. Donc, AC est plus strict que nécessaire, mais il aidera à trouver des accès potentiellement risqués qui pourraient être des divisions de page ou des divisions de ligne de cache avec des données alignées différemment.
Les processeurs AMD peuvent avoir des pénalités pour franchir une limite de 16 octets dans une ligne de cache de 64 octets . Je ne suis pas familier avec ce que les compteurs de matériel sont disponibles là-bas. Méfiez-vous que le profilage sur Intel HW ne trouvera pas nécessairement les ralentissements qui se produisent sur les processeurs AMD, si l'infraction access ne franchit jamais la limite d'une ligne de cache.
Voir Comment puis-je comparer avec précision la vitesse d'accès non alignée sur x86_64 pour plus de détails sur les pénalités, y compris mes tests sur la latence 4K-split et le débit sur Skylake.
L'exécution de binaires normaux avec AC set est pas toujours pratique . Le code généré par le compilateur peut choisir d'utiliser une charge ou un magasin non aligné de 8 octets pour copier plusieurs membres de la structure ou pour stocker des données littérales.
gcc -O3 -mtune=generic (c'est-à-dire la valeur par défaut avec optimisation activée) suppose que les splits de ligne de cache sont assez bon marché pour valoir le risque d'utiliser des accès non alignés au lieu de plusieurs accès étroits comme le fait la source. Page-splits est devenu beaucoup moins cher dans Skylake, passant de ~ 100 à 150 cycles dans Haswell à ~10 cycles dans Skylake (à peu près la même pénalité que cl splits), car apparemment Intel a trouvé qu'ils étaient moins rares qu'ils ne le pensaient auparavant.
De nombreuses fonctions de bibliothèque optimisées (comme memcpy) utilisent des accès entiers non alignés. par exemple, memcpy de la glibc, pour une copie de 6 octets, effectuerait 2 charges de 4 octets superposées à partir du début / de la fin du tampon, puis 2 magasins superposés. (Il n'a pas de cas particulier pour exactement 6 octets pour faire un mot dword +, juste en augmentant les pouvoirs de 2). ce commentaire dans la source explique ses stratégies.
Donc, même si votre système d'exploitation vous permet d'activer AC, vous pourriez avoir besoin d'une version spéciale des bibliothèques pour ne pas déclencher AC partout pour des choses comme small memcpy.
L'alignement lors de la boucle séquentielle sur un tableau compte vraiment pour AVX512, où un vecteur a la même largeur qu'une ligne de cache. Si vos pointeurs sont mal alignés, chaque accès est un partage de ligne de cache, pas seulement tous les autres avec AVX2. Aligné est toujours mieux, mais pour de nombreux algorithmes avec une quantité décente de calcul mélangée avec l'accès à la mémoire, cela ne fait qu'une différence significative avec AVX512.
Les accès mal alignés dispersés traversent une limite de ligne de cache ont essentiellement deux fois l'empreinte de cache de toucher les deux lignes, si les lignes ne sont pas autrement touchées.