Comment détecter une boucle dans une liste chaînée?
dites que vous avez une structure de liste liée en Java. Il est composé de noeuds:
class Node {
Node next;
// some user data
}
et chaque noeud pointe vers le noeud suivant, à l'exception du dernier noeud, qui a nul pour next. Supposons qu'il y ait une possibilité que la liste puisse contenir une boucle - c'est-à-dire que le noeud final, au lieu d'avoir un nul, a une référence à l'un des noeuds de la liste qui est venu avant lui.
Quelle est la meilleure façon d'écrire
boolean hasLoop(Node first)
qui retournerait true si le noeud donné est le premier D'une liste avec une boucle, et false sinon? Comment pourriez-vous écrire afin qu'il prenne une quantité constante de l'espace et un temps raisonnable?
Voici une image de ce à quoi ressemble une liste avec une boucle:
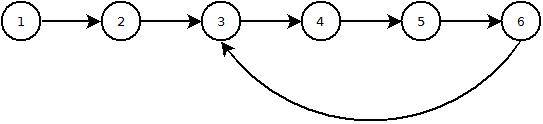
23 réponses
vous pouvez utiliser algorithme de recherche de cycle de Floyd , également connu sous le nom algorithme de tortue et de lièvre .
L'idée est d'avoir deux références à la liste et de les déplacer à plusieurs vitesses . Déplacer l'un vers l'avant par 1 nœud et l'autre par 2 nœuds.
- si la liste liée contient une boucle ils va certainement de répondre.
- autre
les deux références(ou leur
next) deviendranull.
Java fonction de la mise en œuvre de l'algorithme:
boolean hasLoop(Node first) {
if(first == null) // list does not exist..so no loop either
return false;
Node slow, fast; // create two references.
slow = fast = first; // make both refer to the start of the list
while(true) {
slow = slow.next; // 1 hop
if(fast.next != null)
fast = fast.next.next; // 2 hops
else
return false; // next node null => no loop
if(slow == null || fast == null) // if either hits null..no loop
return false;
if(slow == fast) // if the two ever meet...we must have a loop
return true;
}
}
voici un affinement de la solution Fast/Slow, qui gère correctement les listes de longueurs impaires et améliore la clarté.
boolean hasLoop(Node first) {
Node slow = first;
Node fast = first;
while(fast != null && fast.next != null) {
slow = slow.next; // 1 hop
fast = fast.next.next; // 2 hops
if(slow == fast) // fast caught up to slow, so there is a loop
return true;
}
return false; // fast reached null, so the list terminates
}
une solution alternative à la tortue et au lapin, pas aussi sympa, car je change temporairement la liste:
L'idée est de parcourir la liste, et à l'inverse comme vous allez. Ensuite, lorsque vous atteignez un noeud qui a déjà été visité, son prochain pointeur pointera "en arrière", provoquant l'itération de procéder vers first à nouveau, où il se termine.
Node prev = null;
Node cur = first;
while (cur != null) {
Node next = cur.next;
cur.next = prev;
prev = cur;
cur = next;
}
boolean hasCycle = prev == first && first != null && first.next != null;
// reconstruct the list
cur = prev;
prev = null;
while (cur != null) {
Node next = cur.next;
cur.next = prev;
prev = cur;
cur = next;
}
return hasCycle;
code D'essai:
static void assertSameOrder(Node[] nodes) {
for (int i = 0; i < nodes.length - 1; i++) {
assert nodes[i].next == nodes[i + 1];
}
}
public static void main(String[] args) {
Node[] nodes = new Node[100];
for (int i = 0; i < nodes.length; i++) {
nodes[i] = new Node();
}
for (int i = 0; i < nodes.length - 1; i++) {
nodes[i].next = nodes[i + 1];
}
Node first = nodes[0];
Node max = nodes[nodes.length - 1];
max.next = null;
assert !hasCycle(first);
assertSameOrder(nodes);
max.next = first;
assert hasCycle(first);
assertSameOrder(nodes);
max.next = max;
assert hasCycle(first);
assertSameOrder(nodes);
max.next = nodes[50];
assert hasCycle(first);
assertSameOrder(nodes);
}
meilleur que L'algorithme de Floyd
Richard Brent a décrit un algorithme alternatif de détection de cycle , qui est à peu près comme le lièvre et la tortue [cycle de Floyd] sauf que, le noeud lent ici ne bouge pas, mais est plus tard" téléporté " à la position du noeud rapide à intervalles fixes.
la description est disponible ici : http://www.siafoo.net/algorithm/11 Brent prétend que son algorithme est 24 à 36% plus rapide que L'algorithme de cycle de Floyd. O(n) complexité temporelle, O (1) complexité spatiale.
public static boolean hasLoop(Node root){
if(root == null) return false;
Node slow = root, fast = root;
int taken = 0, limit = 2;
while (fast.next != null) {
fast = fast.next;
taken++;
if(slow == fast) return true;
if(taken == limit){
taken = 0;
limit <<= 1; // equivalent to limit *= 2;
slow = fast; // teleporting the turtle (to the hare's position)
}
}
return false;
}
regardez algorithme Rho de Pollard . Ce n'est pas tout à fait le même problème, mais peut-être que vous comprendrez la logique de celui-ci, et l'appliquerez pour les listes liées.
(si vous êtes paresseux, vous pouvez simplement vérifier cycle detection -- vérifier la partie sur la tortue et le lièvre.)
cela ne nécessite que du temps linéaire, et 2 extra pointeur.
En Java:
boolean hasLoop( Node first ) {
if ( first == null ) return false;
Node turtle = first;
Node hare = first;
while ( hare.next != null && hare.next.next != null ) {
turtle = turtle.next;
hare = hare.next.next;
if ( turtle == hare ) return true;
}
return false;
}
(la plus grande partie de la solution ne vérifie pas les valeurs nulles de next et next.next . De plus, comme la tortue est toujours en retard, vous n'avez pas à vérifier si elle est nulle -- le lièvre l'a déjà fait.)
L'utilisateur unicornaddict a une belle algorithme ci-dessus, mais malheureusement, il contient un bug pour les non-loopy listes de longueur impaire >= 3. Le problème est que fast peut être "coincé", juste avant la fin de la liste, slow rattrape, et une boucle est (à tort) détecté.
Voici l'algorithme corrigé.
static boolean hasLoop(Node first) {
if(first == null) // list does not exist..so no loop either.
return false;
Node slow, fast; // create two references.
slow = fast = first; // make both refer to the start of the list.
while(true) {
slow = slow.next; // 1 hop.
if(fast.next == null)
fast = null;
else
fast = fast.next.next; // 2 hops.
if(fast == null) // if fast hits null..no loop.
return false;
if(slow == fast) // if the two ever meet...we must have a loop.
return true;
}
}
peuvent ne pas être la meilleure méthode, c'est de O(n^2). Cependant, il doit servir à faire le travail (éventuellement).
count_of_elements_so_far = 0;
for (each element in linked list)
{
search for current element in first <count_of_elements_so_far>
if found, then you have a loop
else,count_of_elements_so_far++;
}
algorithme
public static boolean hasCycle (LinkedList<Node> list)
{
HashSet<Node> visited = new HashSet<Node>();
for (Node n : list)
{
visited.add(n);
if (visited.contains(n.next))
{
return true;
}
}
return false;
}
complexité
Time ~ O(n)
Space ~ O(n)
public boolean hasLoop(Node start){
TreeSet<Node> set = new TreeSet<Node>();
Node lookingAt = start;
while (lookingAt.peek() != null){
lookingAt = lookingAt.next;
if (set.contains(lookingAt){
return false;
} else {
set.put(lookingAt);
}
return true;
}
// Inside our Node class:
public Node peek(){
return this.next;
}
Pardonnez-moi mon ignorance (je suis encore assez nouveau en Java et en programmation), mais pourquoi cela ne marcherait-il pas?
je suppose que cela ne résout pas le problème de l'espace constant... mais elle permet au moins d'y arriver dans un délai raisonnable, correct? Il ne fera que prendre de l'espace de la liste, en plus de l'espace d'un ensemble à n éléments (où n est le nombre d'éléments dans la liste liée, ou le nombre d'éléments jusqu'à ce qu'il atteigne une boucle). Et pour le temps, dans le pire des cas l'analyse, je pense, suggérerait O(nlog (n)). Les recherches SortedSet pour contains () sont log (n) (vérifiez le javadoc, mais je suis à peu près sûr que la structure sous-jacente de TreeSet est TreeMap, qui à son tour est un arbre rouge-noir), et dans le pire des cas (pas de boucles, ou boucle à la toute fin), il devra faire n recherches.
si nous sommes autorisés à intégrer la classe Node , Je résoudrai le problème comme je l'ai mis en œuvre ci-dessous. hasLoop() court en O(n) temps, et ne prend que l'espace de counter . Cela vous semble comme une solution appropriée? Ou y a-t-il un moyen de le faire sans inclure Node ? (Évidemment, dans une mise en œuvre réelle il y aurait plus de méthodes, comme RemoveNode(Node n) , etc.)
public class LinkedNodeList {
Node first;
Int count;
LinkedNodeList(){
first = null;
count = 0;
}
LinkedNodeList(Node n){
if (n.next != null){
throw new error("must start with single node!");
} else {
first = n;
count = 1;
}
}
public void addNode(Node n){
Node lookingAt = first;
while(lookingAt.next != null){
lookingAt = lookingAt.next;
}
lookingAt.next = n;
count++;
}
public boolean hasLoop(){
int counter = 0;
Node lookingAt = first;
while(lookingAt.next != null){
counter++;
if (count < counter){
return false;
} else {
lookingAt = lookingAt.next;
}
}
return true;
}
private class Node{
Node next;
....
}
}
vous pourriez même le faire en temps O(1) constant (bien que ce ne serait pas très rapide ou efficace): Il ya une quantité limitée de noeuds de la mémoire de votre ordinateur peut tenir, disons n dossiers. Si vous parcourir plus de N enregistrements, alors vous avez une boucle.
// To detect whether a circular loop exists in a linked list
public boolean findCircularLoop() {
Node slower, faster;
slower = head;
faster = head.next; // start faster one node ahead
while (true) {
// if the faster pointer encounters a NULL element
if (faster == null || faster.next == null)
return false;
// if faster pointer ever equals slower or faster's next
// pointer is ever equal to slower then it's a circular list
else if (slower == faster || slower == faster.next)
return true;
else {
// advance the pointers
slower = slower.next;
faster = faster.next.next;
}
}
}
Je ne vois aucune façon de faire cela prendre une quantité fixe de temps ou d'espace, les deux vont augmenter avec la taille de la liste.
j'utiliserais une IdentityHashMap (étant donné qu'il n'y a pas encore D'IdentityHashSet) et je stockerais chaque noeud dans la carte. Avant qu'un noeud soit stocké, vous appelleriez containsKey dessus. Si le noeud existe déjà, vous avez un cycle.
ItentityHashMap uses = = au lieu de .égal de sorte que vous vérifiez où le l'objet est en mémoire plutôt que si il a le même contenu.
je pourrais être terriblement en retard et nouveau pour gérer ce fil. Mais tout de même..
pourquoi ne pas stocker dans une table l'adresse du noeud et le point suivant du noeud
Si nous pouvions nous dépouiller de cette façon,
node present: (present node addr) (next node address)
node 1: addr1: 0x100 addr2: 0x200 ( no present node address till this point had 0x200)
node 2: addr2: 0x200 addr3: 0x300 ( no present node address till this point had 0x300)
node 3: addr3: 0x300 addr4: 0x400 ( no present node address till this point had 0x400)
node 4: addr4: 0x400 addr5: 0x500 ( no present node address till this point had 0x500)
node 5: addr5: 0x500 addr6: 0x600 ( no present node address till this point had 0x600)
node 6: addr6: 0x600 addr4: 0x400 ( ONE present node address till this point had 0x400)
il y a donc un cycle formé.
Voici mon code d'exécution.
ce que j'ai fait est de revenir sur la liste des liens en utilisant trois noeuds temporaires ("Space complexity O(1) ) qui gardent la trace des liens.
le fait intéressant de le faire est d'aider à détecter le cycle dans la liste liée parce que vous allez de l'avant, vous ne vous attendez pas à revenir au point de départ (noeud racine) et l'un des noeuds temporaires devrait aller à null sauf si vous avez un cycle ce qui signifie qu'il pointe vers le nœud racine.
la complexité temporelle de cet algorithme est O(n) et la complexité spatiale est O(1) .
voici le noeud de classe pour la liste liée:
public class LinkedNode{
public LinkedNode next;
}
voici le code principal avec un cas de test simple de trois noeuds que le dernier noeud pointant vers le second noeud:
public static boolean checkLoopInLinkedList(LinkedNode root){
if (root == null || root.next == null) return false;
LinkedNode current1 = root, current2 = root.next, current3 = root.next.next;
root.next = null;
current2.next = current1;
while(current3 != null){
if(current3 == root) return true;
current1 = current2;
current2 = current3;
current3 = current3.next;
current2.next = current1;
}
return false;
}
voici un cas de test simple de trois noeuds que le dernier noeud pointant vers le second node:
public class questions{
public static void main(String [] args){
LinkedNode n1 = new LinkedNode();
LinkedNode n2 = new LinkedNode();
LinkedNode n3 = new LinkedNode();
n1.next = n2;
n2.next = n3;
n3.next = n2;
System.out.print(checkLoopInLinkedList(n1));
}
}
ce code est optimisé et produira des résultats plus rapidement qu'avec celui choisi comme la meilleure réponse.Ce code sauve d'aller dans un très long processus de poursuite du pointeur de noeud avant et arrière qui se produira dans le cas suivant si nous suivons la méthode de la "meilleure réponse".Regardez à travers la répétition de ce qui suit et vous vous rendrez compte de ce que j'essaie de dire.Ensuite, regardez le problème à travers la méthode donnée ci-dessous et mesurez le non. des mesures prises pour trouver la réponse.
1->2->9->3 ^--------^
voici le code:
boolean loop(node *head)
{
node *back=head;
node *front=head;
while(front && front->next)
{
front=front->next->next;
if(back==front)
return true;
else
back=back->next;
}
return false
}
boolean hasCycle(Node head) {
boolean dec = false;
Node first = head;
Node sec = head;
while(first != null && sec != null)
{
first = first.next;
sec = sec.next.next;
if(first == sec )
{
dec = true;
break;
}
}
return dec;
}
utilisez la fonction ci-dessus pour détecter une boucle dans linkedlist en java.
la détection d'une boucle dans une liste liée peut être faite de l'une des façons les plus simples, qui résulte en O(N) complexité.
en parcourant la liste à partir de head, créez une liste d'adresses triée. Lorsque vous insérez une nouvelle adresse, vérifiez si l'adresse est déjà présente dans la liste triée, ce qui prend la complexité O(logN).
vous pouvez utiliser L'algorithme tortoise de Floyd comme suggéré dans les réponses ci-dessus aussi.
cet algorithme peut vérifier si une liste à un seul lien a un cycle fermé. Cela peut être réalisé en itérant une liste avec deux pointeurs qui se déplacent à une vitesse différente. De cette façon, s'il y a un cycle, les deux indicateurs se rencontreront à un moment donné dans le futur.
s'il vous Plaît n'hésitez pas à consulter mon blog post sur les listes de données structure, où j'ai également inclus un extrait de code avec une implémentation de l'algorithme mentionné ci-dessus en langage java.
Cordialement,
Andreas (@xnorcode)
Voici la solution pour détecter le cycle.
public boolean hasCycle(ListNode head) {
ListNode slow =head;
ListNode fast =head;
while(fast!=null && fast.next!=null){
slow = slow.next; // slow pointer only one hop
fast = fast.next.next; // fast pointer two hops
if(slow == fast) return true; // retrun true if fast meet slow pointer
}
return false; // return false if fast pointer stop at end
}
Cette approche a l'espace de la surcharge, une simplification de la mise en œuvre:
La bouclepeut être identifiée en stockant les noeuds dans une carte. Et avant de mettre le noeud; vérifiez si le noeud existe déjà. Si le noeud existe déjà dans la carte, alors cela signifie que la liste liée a une boucle.
public boolean loopDetector(Node<E> first) {
Node<E> t = first;
Map<Node<E>, Node<E>> map = new IdentityHashMap<Node<E>, Node<E>>();
while (t != null) {
if (map.containsKey(t)) {
System.out.println(" duplicate Node is --" + t
+ " having value :" + t.data);
return true;
} else {
map.put(t, t);
}
t = t.next;
}
return false;
}
voici ma solution en java
boolean detectLoop(Node head){
Node fastRunner = head;
Node slowRunner = head;
while(fastRunner != null && slowRunner !=null && fastRunner.next != null){
fastRunner = fastRunner.next.next;
slowRunner = slowRunner.next;
if(fastRunner == slowRunner){
return true;
}
}
return false;
}
public boolean isCircular() {
if (head == null)
return false;
Node temp1 = head;
Node temp2 = head;
try {
while (temp2.next != null) {
temp2 = temp2.next.next.next;
temp1 = temp1.next;
if (temp1 == temp2 || temp1 == temp2.next)
return true;
}
} catch (NullPointerException ex) {
return false;
}
return false;
}