Comment gérer la prévision de séries chronologiques en plusieurs étapes dans le LSTM multivarié de keras
je suis en train de faire du multi-étape de prévision des séries chronologiques à l'aide de multivariée LSTM dans Keras. Plus précisément, j'ai deux variables (var1 et var2) pour chaque pas de temps à l'origine. Ayant suivi le tutoriel en ligne ici , j'ai décidé d'utiliser les données au temps (t-2) et (t-1) pour prédire la valeur de var2 au temps étape T. Comme le montre le tableau de données d'échantillon, j'utilise les 4 premières colonnes comme entrées, Y comme sorties. Le code que j'ai développé peut être vu ici , mais J'ai trois questions.
var1(t-2) var2(t-2) var1(t-1) var2(t-1) var2(t)
2 1.5 -0.8 0.9 -0.5 -0.2
3 0.9 -0.5 -0.1 -0.2 0.2
4 -0.1 -0.2 -0.3 0.2 0.4
5 -0.3 0.2 -0.7 0.4 0.6
6 -0.7 0.4 0.2 0.6 0.7
- Q1: j'ai formé un modèle LSTM avec les données ci-dessus. Ce modèle ne bien dans la prédiction de la valeur de var2 à l'étape t de temps. Cependant, ce si je veux prédire var2 au temps étape t+1. Je sens que c'est dur parce que le modèle ne peut pas me dire la valeur de var1 à l'étape t du temps. Si je veux le faire, Comment dois-je modifier le code pour construire le modèle?
- Q2: j'ai vu cette question poser beaucoup, mais je suis encore confus. Dans mon exemple, Quel devrait être le pas de temps correct dans [samples, time les étapes, les caractéristiques] 1 ou 2?
- Q3: je viens de commencer à étudier les LSTMs. J'ai lire ici que l'un des plus grands avantages de LSTM est qu'il apprend la dépendance temporelle/la taille de la fenêtre coulissante par elle-même, puis pourquoi faut-il toujours Cacher les données des séries chronologiques format comme le le tableau ci-dessus?
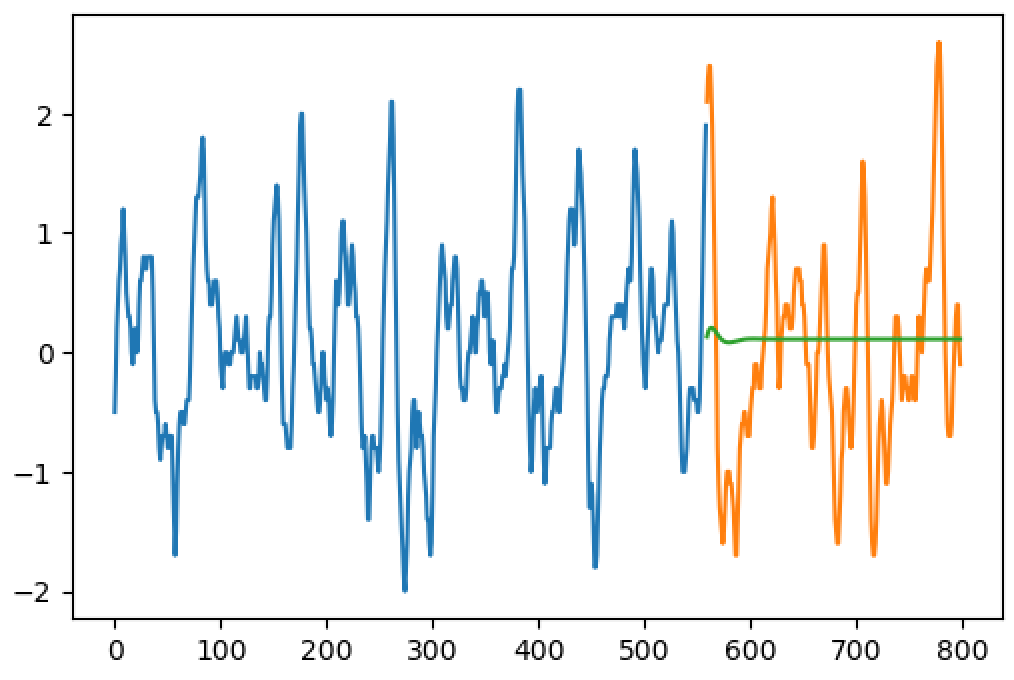
mise à Jour: LSTM résultat (ligne bleue est la formation seq, la ligne orange est la vérité du terrain, le vert est la prédiction)
2 réponses
Question 1:
de votre table, je vois que vous avez une fenêtre coulissante au-dessus d'une seule séquence, faisant de nombreuses séquences plus petites avec 2 étapes.
- pour prédire t, vous prenez la première ligne de votre table comme entrée
- pour prédire t+1, vous prenez la deuxième ligne comme entrée.
si vous n'utilisez pas la table: voir question 3
Question 2:
en supposant que vous utilisez cette table comme entrée, où il s'agit clairement d'une fenêtre coulissante prenant deux pas de temps comme entrée, votre timeSteps est 2.
vous devriez probablement travailler comme si var1 et var2 étaient des caractéristiques dans la même séquence:
-
input_shape = (2,2)- deux pas dans le temps et deux caractéristiques/var.
Question 3:
Nous n'avons pas besoin de faites des tables comme ça ou construisez une vitrine coulissante. C'est une approche possible.
votre modèle est en fait capable d'apprendre des choses et de décider de la taille de cette fenêtre elle-même.
Si d'un côté de votre modèle est capable d'apprendre, dépendances de temps, vous permettant de ne pas utiliser windows, d'autre part, il peut apprendre à identifier les différents comportements au début et au milieu d'une séquence. Dans ce cas, si vous voulez prévoir en utilisant des séquences qui partent du milieu (sans compter le début), votre modèle peut fonctionner comme s'il était le début et prédire un comportement différent. Utiliser windows élimine cette très longue influence. Ce qui est mieux dépend des tests, je suppose.
n'utilisant pas windows:
si vos données ont 800 pas, alimenter tous les 800 pas à la fois pour la formation.
ici, nous aurons besoin de séparer deux modèles, l'un pour la formation, l'autre pour la prédiction. En formation, nous allons profiter du paramètre return_sequences=True . Cela signifie que pour chaque étape d'entrée, nous obtiendrons une étape de sortie.
pour prévoir plus tard, nous ne voulons qu'une sortie, alors nous utiliserons return_sequences= False . Et dans le cas où nous allons utiliser les sorties prédites comme entrées pour les étapes suivantes, nous allons utiliser une couche stateful=True .
formation:
Avoir vos données d'entrée en forme de (1, 799, 2) , 1 séquence, en prenant les étapes de 1 à 799. Les deux Var dans la même séquence (2 Caractéristiques).
ont vos données cibles (Y) en forme aussi comme (1, 799, 2) , en prenant les mêmes étapes décalées, de 2 à 800.
construisez un modèle avec return_sequences=True . Vous pouvez utiliser timeSteps=799 , mais vous pouvez aussi utiliser None (permettant un nombre variable d'étapes).
model.add(LSTM(units, input_shape=(None,2), return_sequences=True))
model.add(LSTM(2, return_sequences=True)) #it could be a Dense 2 too....
....
model.fit(X, Y, ....)
prévision:
pour prédire, créer un modèle similaire, maintenant avec return_sequences=False .
copier les poids:
newModel.set_weights(model.get_weights())
vous pouvez faire une entrée avec la longueur 800, par exemple (forme: (1,800,2) ) et prédire juste l'étape suivante:
step801 = newModel.predict(X)
si vous voulez prédire plus, nous allons utiliser les couches stateful=True . Utilisez le même modèle à nouveau, maintenant avec return_sequences=False (seulement dans le dernier LSTM, les autres restent vrai) et stateful=True (tous). Remplacer le input_shape par batch_input_shape=(1,None,2) .
#with stateful=True, your model will never think that the sequence ended
#each new batch will be seen as new steps instead of new sequences
#because of this, we need to call this when we want a sequence starting from zero:
statefulModel.reset_states()
#predicting
X = steps1to800 #input
step801 = statefulModel.predict(X).reshape(1,1,2)
step802 = statefulModel.predict(step801).reshape(1,1,2)
step803 = statefulModel.predict(step802).reshape(1,1,2)
#the reshape is because return_sequences=True eliminates the step dimension
en fait, vous pourriez tout faire avec un seul stateful=True et return_sequences=True modèle, en prenant soin de deux choses:
- lors de la formation,
reset_states()pour chaque époque. (Train avec boucle manuelle etepochs=1) - en prédisant à partir de plus que d'une étape, prendre seulement la dernière étape de la sortie comme le résultat désiré.
en fait, vous ne pouvez pas simplement alimenter dans les données brutes des séries chronologiques, car le réseau ne s'y adapte pas naturellement. L'état actuel de RNNs encore vous oblige à entrées multiples "caractéristiques" (manuellement ou automatiquement) pour correctement apprendre quelque chose d'utile.
habituellement, les étapes préalables nécessaires sont:
- nuire
- Deseasonalize
- échelle (normaliser)
une grande source d'information est ce post d'un chercheur de Microsoft qui a remporté un concours de prévision de séries chronologiques par le biais d'un réseau LSTM.
Aussi ce post: CNTK - Prédiction de séries temporelles