Comment comparer des caractères Unicode qui "ressemblent"?
je tombe dans un numéro surprenant.
j'ai chargé un fichier texte dans mon application et j'ai une logique qui compare la valeur ayant µ.
Et j'ai réalisé que même si les textes sont même la valeur de comparaison est fausse.
Console.WriteLine("μ".Equals("µ")); // returns false
Console.WriteLine("µ".Equals("µ")); // return true
dans la ligne suivante, le caractère µ est collé.
cependant, ce ne sont peut-être pas les seuls caractères qui sont ainsi.
Est-il un façon en C# pour comparer les caractères qui se ressemblent mais qui sont en fait différents?
10 réponses
dans de nombreux cas, vous pouvez normaliser les deux caractères Unicode à une certaine forme de normalisation avant de les comparer, et ils devraient être en mesure de correspondre. Bien sûr, la forme de normalisation que vous devez utiliser dépend des caractères eux-mêmes; juste parce qu'ils ressemblent ne signifie pas nécessairement qu'ils représentent le même caractère. Vous devez également considérer si elle est appropriée pour votre cas d'utilisation - voir le commentaire de Jukka K. Korpela.
pour cette situation particulière, si vous vous référez aux liens dans la réponse de Tony , vous verrez que le tableau pour U+00B5 dit:
décomposition < compat> petite lettre grecque MU (U+03BC)
cela signifie U+00B5, le deuxième caractère de votre comparaison originale, peut être décomposé en U+03BC, le premier caractère.
normaliser les caractères en utilisant la décomposition de compatibilité complète, avec les formes de normalisation KC ou KD. Voici un exemple rapide que j'ai écrit pour démontrer:
using System;
using System.Text;
class Program
{
static void Main(string[] args)
{
char first = 'μ';
char second = 'µ';
// Technically you only need to normalize U+00B5 to obtain U+03BC, but
// if you're unsure which character is which, you can safely normalize both
string firstNormalized = first.ToString().Normalize(NormalizationForm.FormKD);
string secondNormalized = second.ToString().Normalize(NormalizationForm.FormKD);
Console.WriteLine(first.Equals(second)); // False
Console.WriteLine(firstNormalized.Equals(secondNormalized)); // True
}
}
pour plus de détails sur la normalisation Unicode et les différentes formes de normalisation, voir System.Text.NormalizationForm et the Unicode spec .
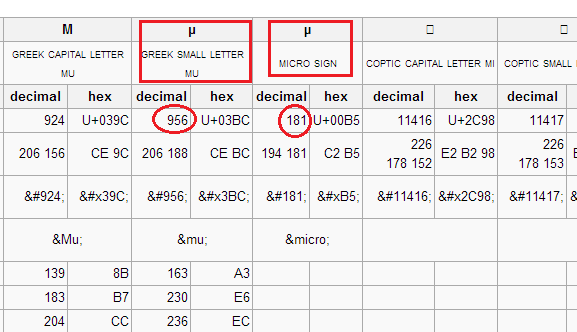
parce que ce sont vraiment des symboles différents même ils regardent la même, d'abord est la lettre réelle et a le char code = 956 (0x3BC) et le second est le micro signe et a 181 (0xB5) .
, les Références:
donc si vous voulez pour les comparer et vous avez besoin qu'ils soient égaux, vous devez le manipuler manuellement, ou remplacer un char par un autre avant la comparaison. Ou utilisez le code suivant:
public void Main()
{
var s1 = "μ";
var s2 = "µ";
Console.WriteLine(s1.Equals(s2)); // false
Console.WriteLine(RemoveDiacritics(s1).Equals(RemoveDiacritics(s2))); // true
}
static string RemoveDiacritics(string text)
{
var normalizedString = text.Normalize(NormalizationForm.FormKC);
var stringBuilder = new StringBuilder();
foreach (var c in normalizedString)
{
var unicodeCategory = CharUnicodeInfo.GetUnicodeCategory(c);
if (unicodeCategory != UnicodeCategory.NonSpacingMark)
{
stringBuilder.Append(c);
}
}
return stringBuilder.ToString().Normalize(NormalizationForm.FormC);
}
et la Démo
ils ont tous deux des codes de caractères différents: référez-vous à ceci pour plus de détails
Console.WriteLine((int)'μ'); //956
Console.WriteLine((int)'µ'); //181
où, le premier est:
Display Friendly Code Decimal Code Hex Code Description
====================================================================
μ μ μ μ Lowercase Mu
µ µ µ µ micro sign Mu
pour l'exemple spécifique de μ (mu) et µ (micro signe), ce dernier a une décomposition de compatibilité à la première, de sorte que vous pouvez normaliser la chaîne à FormKC ou FormKD pour convertir les micro signes en mus.
cependant, il y a beaucoup d'ensembles de caractères qui se ressemblent mais qui ne sont pas équivalents sous n'importe quelle forme de normalisation Unicode. Par exemple, A (Latin), Α (grec), et А (Cyrillique). Le site Web Unicode a un confusables.txt fichier avec une liste de ceux-ci, destinés à aider les développeurs de se prémunir contre attaques homographes . Si nécessaire, vous pouvez analyser ce fichier et construire une table pour la "normalisation visuelle" des chaînes.
recherche les deux caractères dans une base de données Unicode et voir la différence .
L'une est la petite lettre grecque" 151980920 µ et l'autre est le Micro signe µ .
Name : MICRO SIGN Block : Latin-1 Supplement Category : Letter, Lowercase [Ll] Combine : 0 BIDI : Left-to-Right [L] Decomposition : <compat> GREEK SMALL LETTER MU (U+03BC) Mirror : N Index entries : MICRO SIGN Upper case : U+039C Title case : U+039C Version : Unicode 1.1.0 (June, 1993)
Name : GREEK SMALL LETTER MU Block : Greek and Coptic Category : Letter, Lowercase [Ll] Combine : 0 BIDI : Left-to-Right [L] Mirror : N Upper case : U+039C Title case : U+039C See Also : micro sign U+00B5 Version : Unicode 1.1.0 (June, 1993)
EDIT après la fusion de cette question avec comment comparer 'μ' et 'µ' dans C#
Réponse originale postée:
"μ".ToUpper().Equals("µ".ToUpper()); //This always return true.
EDIT Après avoir lu les commentaires, oui il n'est pas bon d'utiliser la méthode ci-dessus parce qu'elle peut fournir des résultats erronés pour un autre type d'entrées, pour ce que nous devrions utiliser normaliser en utilisant plein décomposition de compatibilité comme indiqué dans wiki . (Merci à la réponse posté par BoltClock )
static string GREEK_SMALL_LETTER_MU = new String(new char[] { '\u03BC' });
static string MICRO_SIGN = new String(new char[] { '\u00B5' });
public static void Main()
{
string Mus = "µμ";
string NormalizedString = null;
int i = 0;
do
{
string OriginalUnicodeString = Mus[i].ToString();
if (OriginalUnicodeString.Equals(GREEK_SMALL_LETTER_MU))
Console.WriteLine(" INFORMATIO ABOUT GREEK_SMALL_LETTER_MU");
else if (OriginalUnicodeString.Equals(MICRO_SIGN))
Console.WriteLine(" INFORMATIO ABOUT MICRO_SIGN");
Console.WriteLine();
ShowHexaDecimal(OriginalUnicodeString);
Console.WriteLine("Unicode character category " + CharUnicodeInfo.GetUnicodeCategory(Mus[i]));
NormalizedString = OriginalUnicodeString.Normalize(NormalizationForm.FormC);
Console.Write("Form C Normalized: ");
ShowHexaDecimal(NormalizedString);
NormalizedString = OriginalUnicodeString.Normalize(NormalizationForm.FormD);
Console.Write("Form D Normalized: ");
ShowHexaDecimal(NormalizedString);
NormalizedString = OriginalUnicodeString.Normalize(NormalizationForm.FormKC);
Console.Write("Form KC Normalized: ");
ShowHexaDecimal(NormalizedString);
NormalizedString = OriginalUnicodeString.Normalize(NormalizationForm.FormKD);
Console.Write("Form KD Normalized: ");
ShowHexaDecimal(NormalizedString);
Console.WriteLine("_______________________________________________________________");
i++;
} while (i < 2);
Console.ReadLine();
}
private static void ShowHexaDecimal(string UnicodeString)
{
Console.Write("Hexa-Decimal Characters of " + UnicodeString + " are ");
foreach (short x in UnicodeString.ToCharArray())
{
Console.Write("{0:X4} ", x);
}
Console.WriteLine();
}
Sortie
INFORMATIO ABOUT MICRO_SIGN
Hexa-Decimal Characters of µ are 00B5
Unicode character category LowercaseLetter
Form C Normalized: Hexa-Decimal Characters of µ are 00B5
Form D Normalized: Hexa-Decimal Characters of µ are 00B5
Form KC Normalized: Hexa-Decimal Characters of µ are 03BC
Form KD Normalized: Hexa-Decimal Characters of µ are 03BC
________________________________________________________________
INFORMATIO ABOUT GREEK_SMALL_LETTER_MU
Hexa-Decimal Characters of µ are 03BC
Unicode character category LowercaseLetter
Form C Normalized: Hexa-Decimal Characters of µ are 03BC
Form D Normalized: Hexa-Decimal Characters of µ are 03BC
Form KC Normalized: Hexa-Decimal Characters of µ are 03BC
Form KD Normalized: Hexa-Decimal Characters of µ are 03BC
________________________________________________________________
en lisant des informations dans Unicode_equivalence j'ai trouvé
le choix des critères d'équivalence peut affecter les résultats de la recherche. Par exemple, certains typographiques les ligatures comme U+FB03 (ffi), ..... ainsi ,une recherche pour U+0066 (f) comme substrat succéderait dans un NFKC normalisation de U+FB03 mais pas dans NFC normalisation de U+fb03.
donc, pour comparer l'équivalence, nous devrions normalement utiliser FormKC c.-à-d. la normalisation NFKC ou FormKD I. e NFKD normalisation.
J'étais peu curieux d'en savoir plus sur tous les caractères Unicode donc j'ai fait l'échantillon qui itérerait sur tous les caractères Unicode dans UTF-16 et j'ai obtenu quelques résultats que je veux discuter
- Information sur les caractères dont les valeurs normalisées
FormCetFormDn'étaient pas équivalentes
Total: 12,118
Character (int value): 192-197, 199-207, 209-214, 217-221, 224-253, ..... 44032-55203 - Informations sur les caractères dont les valeurs normalisées
FormKCetFormKDn'étaient pas équivalentes
Total: 12,245
Character (int value): 192-197, 199-207, 209-214, 217-221, 224-228, ..... 44032-55203, 64420-64421, 64432-64433, 64490-64507, 64512-64516, 64612-64617, 64663-64667, 64735-64736, 65153-65164, 65269-65274 - tous les caractères dont les valeurs normalisées
FormCetFormDn'étaient pas équivalentes, il n'y avait pas non plus de valeurs normaliséesFormKCetFormKDsauf ces caractères
Caractères:901 '΅', 8129 '῁', 8141 '῍', 8142 '῎', 8143 '῏', 8157 '῝', 8158 '῞'
, 8159 '῟', 8173 '῭', 8174 '΅' - Extra personnage dont le
FormKCetFormKDnormalisé valeur ne sont pas équivalentes, mais de làFormCetFormDvaleurs normalisées ont été équivalent
Total: 119
Caractères:452 'DŽ' 453 'Dž' 454 'dž' 12814 '㈎' 12815 '㈏' 12816 '㈐' 12817 '㈑' 12818 '㈒' 12819 '㈓' 12820 '㈔' 12821 '㈕', 12822 '㈖' 12823 '㈗' 12824 '㈘' 12825 '㈙' 12826 '㈚' 12827 '㈛' 12828 '㈜' 12829 '㈝' 12830 '㈞' 12910 '㉮' 12911 '㉯' 12912 '㉰' 12913 '㉱' 12914 '㉲' 12915 '㉳' 12916 '㉴' 12917 '㉵' 12918 '㉶' 12919 '㉷' 12920 '㉸' 12921 '㉹' 12922 '㉺' 12923 '㉻' 12924 '㉼' 12925 '㉽' 12926 '㉾' 13056 '㌀' 13058 '㌂' 13060 '㌄' 13063 '㌇' 13070 '㌎' 13071 '㌏' 13072 '㌐' 13073 '㌑' 13075 '㌓' 13077 '㌕' 13080 '㌘' 13081 '㌙' 13082 '㌚' 13086 '㌞' 13089 '㌡' 13092 '㌤' 13093 '㌥' 13094 '㌦' 13099 '㌫' 13100 '㌬' 13101 '㌭' 13102 '㌮' 13103 '㌯' 13104 '㌰' 13105 '㌱' 13106 '㌲' 13108 '㌴' 13111 '㌷' 13112 '㌸' 13114 '㌺' 13115 '㌻' 13116 '㌼' 13117 '㌽' 13118 '㌾' 13120 '㍀' 13130 '㍊' 13131 '㍋' 13132 '㍌' 13134 '㍎' 13139 '㍓' 13140 '㍔' 13142 '㍖' .......... ﺋ' 65164 'ﺌ' 65269 'ﻵ' 65270 'ﻶ' 65271 'ﻷ' 65272 'ﻸ' 65273 'ﻹ' 65274' - il y a quelques caractères que ne peut pas être normalisé , ils jettent
ArgumentExceptionsi essayé
Total:2081Characters(int value): 55296-57343, 64976-65007, 65534
ces liens peuvent être vraiment utiles pour comprendre quelles règles régissent L'équivalence Unicode
très probablement, il y a deux codes de caractères différents qui font (visiblement) le même caractère. Bien que techniquement pas égaux, ils semblent égaux. Regardez la table de caractères et voyez s'il y a plusieurs instances de ce caractère. Ou imprimez le code de caractères des deux caractères dans votre code.
Vous demandez: "comment les comparer" mais vous ne nous dites pas ce que vous voulez faire.
il y a au moins deux façons principales de les comparer:
soit vous les comparez directement comme vous êtes et ils sont différents
ou vous utilisez la normalisation de compatibilité Unicode si votre besoin est d'une comparaison qui les trouve pour correspondre.
il pourrait y avoir un problème cependant parce que la normalisation de compatibilité Unicode faites beaucoup d'autres caractères comparer égal. Si vous voulez seulement que ces deux caractères soient traités de la même façon, vous devriez lancer vos propres fonctions de normalisation ou de comparaison.
Pour une solution spécifique nous avons besoin de connaître votre problème spécifique. Dans quel contexte êtes-vous tombé sur ce problème?
si je voudrais être pédant, je dirais que votre question n'a pas de sens, mais puisque nous approchons de Noël et que les oiseaux chantent, Je vais continuer avec ça.
tout d'abord, les 2 entités que vous essayez de comparer sont glyph s, un glyphe fait partie d'un ensemble de glyphes fournis par ce qui est généralement connu comme une "police", la chose qui vient habituellement dans un ttf , otf ou quel que soit le format de fichier que vous utilisez.
les glyphes sont une représentation d'un symbole donné, et puisqu'ils sont une représentation qui dépend d'un ensemble spécifique, vous ne pouvez pas vous attendre à avoir 2 symboles identiques similaires ou même" meilleurs", c'est une phrase qui n'a pas de sens si vous considérez le contexte, vous devriez au moins spécifier quelle police ou quel ensemble de glyphes vous envisagez lorsque vous formulez une question comme celle-ci.
Ce qui est généralement utilisée pour résoudre un problème similaire à celui que vous êtes rencontre, C'est un OCR, essentiellement un logiciel qui reconnaît et compare les glyphes, si C# fournit un OCR par défaut Je ne sais pas, mais c'est généralement une très mauvaise idée si vous n'avez pas vraiment besoin D'un OCR et que vous savez quoi faire avec.
vous pouvez éventuellement finir par interpréter un livre de physique comme un livre grec ancien sans mentionner le fait que les OCR sont généralement coûteux en termes de ressources.
il y a un la raison pour laquelle ces caractères sont localisés de la façon dont ils sont localisés, mais ne le faites pas.
il est possible de dessiner les deux caractères avec le même style de police et la même taille avec la méthode DrawString . Après deux bitmaps avec des symboles ont été générés, il est possible de les comparer pixel par pixel.
avantage de cette méthode est que vous pouvez comparer non seulement absolu charcters égaux, mais similaire aussi (avec une tolérance définie).