Comment calculer le nombre de sous-ensembles de coprimes de l'ensemble {1,2,3,..,et}
Je résous cette tâche (problème I) . La déclaration est:
Combien de sous-ensembles de l'ensemble {1, 2, 3, ..., n} sont premiers entre eux? Un ensemble d'entiers est appelé coprime si tous les deux de ses éléments sont coprime. Deux entiers sont coprime si leur plus grand diviseur commun est égal à 1.
Entrée
La Première ligne de l'entrée contient deux entiers n et m (1 <= n <= 3000, 1 <= m <= 10^9 + 9)
Sortie
Affiche le nombre de sous-ensembles de coprimes de {1, 2, 3, ..., n} modulo m.
Exemple
Entrée: 4 7 sortie: 5
Il y a 12 premiers entre eux des sous-ensembles de {1,2,3,4}: {}, {1}, {2}, {3}, {4}, {1,2}, {1,3}, {1,4}, {2,3}, {3,4}, {1,2,3}, {1,3,4}.
Je pense que cela peut être résolu en utilisant des nombres premiers. (suivi de si nous avons utilisé chaque nombre premier) ..mais je ne suis pas sûr.
Puis-je obtenir quelques conseils pour résoudre cette tâche?
- Vous pouvez trouver cette séquence ici : http://oeis.org/A084422
9 réponses
Ok, voici les marchandises. Le programme C qui suit obtient n = 3000 en moins de 5 secondes pour moi. Mon chapeau à l'équipe (s) qui a résolu ce problème problème dans un cadre concurrentiel.
L'algorithme est basé sur l'idée de traiter le petit et le grand nombres premiers différemment. Un premier est Petit si son carré est au plus N. Sinon, c'est grand. Observer que chaque nombre inférieur ou égal à n a au plus un grand facteur premier.
Nous faisons une table indexée par paires. Le premier composant de chaque paire spécifie le nombre de grands nombres premiers utilisés. La deuxième composante de la chaque paire spécifie l'ensemble des petits nombres premiers utilisés. La valeur à un particulier l'indice est le nombre de solutions avec ce modèle d'utilisation pas contenant 1 ou un grand nombre premier (on compte ceux-ci plus tard en multipliant par la puissance appropriée de 2).
Nous itérons vers le bas sur les nombres j sans grands facteurs premiers. À l' au début de chaque itération, la table contient les comptes pour les sous-ensembles de j..N. Il y a deux ajouts dans la boucle interne. Les premiers comptes pour étendre les sous-ensembles par j lui-même, ce qui n'augmente pas le nombre de grands nombres premiers en cours d'utilisation. La seconde tient compte de l'extension des sous-ensembles par j fois un grand premier, ce qui ne. Le nombre de grands nombres premiers est le nombre de grands nombres premiers ne dépassant pas n / j, moins le nombre de grands nombres premiers déjà utilisés, puisque l'itération descendante implique que chaque Grand Premier déjà utilisé n'est pas supérieur à n / J.
Au fin, nous additionnons les entrées de la table. Chaque sous-ensemble compté dans le tableau donne 2 * * K sous-ensembles où k est un plus le nombre d'inutilisés grands nombres premiers, comme 1 et chaque grand premier inutilisé peut être inclus ou exclus indépendamment.
/* assumes int, long are 32, 64 bits respectively */
#include <stdio.h>
#include <stdlib.h>
enum {
NMAX = 3000
};
static int n;
static long m;
static unsigned smallfactors[NMAX + 1];
static int prime[NMAX - 1];
static int primecount;
static int smallprimecount;
static int largeprimefactor[NMAX + 1];
static int largeprimecount[NMAX + 1];
static long **table;
static void eratosthenes(void) {
int i;
for (i = 2; i * i <= n; i++) {
int j;
if (smallfactors[i]) continue;
for (j = i; j <= n; j += i) smallfactors[j] |= 1U << primecount;
prime[primecount++] = i;
}
smallprimecount = primecount;
for (; i <= n; i++) {
if (!smallfactors[i]) prime[primecount++] = i;
}
if (0) {
int k;
for (k = 0; k < primecount; k++) printf("%d\n", prime[k]);
}
}
static void makelargeprimefactor(void) {
int i;
for (i = smallprimecount; i < primecount; i++) {
int p = prime[i];
int j;
for (j = p; j <= n; j += p) largeprimefactor[j] = p;
}
}
static void makelargeprimecount(void) {
int i = 1;
int j;
for (j = primecount; j > smallprimecount; j--) {
for (; i <= n / prime[j - 1]; i++) {
largeprimecount[i] = j - smallprimecount;
}
}
if (0) {
for (i = 1; i <= n; i++) printf("%d %d\n", i, largeprimecount[i]);
}
}
static void maketable(void) {
int i;
int j;
table = calloc(smallprimecount + 1, sizeof *table);
for (i = 0; i <= smallprimecount; i++) {
table[i] = calloc(1U << smallprimecount, sizeof *table[i]);
}
table[0][0U] = 1L % m;
for (j = n; j >= 2; j--) {
int lpc = largeprimecount[j];
unsigned sf = smallfactors[j];
if (largeprimefactor[j]) continue;
for (i = 0; i < smallprimecount; i++) {
long *cur = table[i];
long *next = table[i + 1];
unsigned f;
for (f = sf; f < (1U << smallprimecount); f = (f + 1U) | sf) {
cur[f] = (cur[f] + cur[f & ~sf]) % m;
}
if (lpc - i <= 0) continue;
for (f = sf; f < (1U << smallprimecount); f = (f + 1U) | sf) {
next[f] = (next[f] + cur[f & ~sf] * (lpc - i)) % m;
}
}
}
}
static long timesexp2mod(long x, int y) {
long z = 2L % m;
for (; y > 0; y >>= 1) {
if (y & 1) x = (x * z) % m;
z = (z * z) % m;
}
return x;
}
static long computetotal(void) {
long total = 0L;
int i;
for (i = 0; i <= smallprimecount; i++) {
unsigned f;
for (f = 0U; f < (1U << smallprimecount); f++) {
total = (total + timesexp2mod(table[i][f], largeprimecount[1] - i + 1)) % m;
}
}
return total;
}
int main(void) {
scanf("%d%ld", &n, &m);
eratosthenes();
makelargeprimefactor();
makelargeprimecount();
maketable();
if (0) {
int i;
for (i = 0; i < 100; i++) {
printf("%d %ld\n", i, timesexp2mod(1L, i));
}
}
printf("%ld\n", computetotal());
return EXIT_SUCCESS;
}
Voici une réponse qui passe par les 200 premiers éléments de la séquence en moins d'une seconde, donnant la bonne réponse 200 → 374855124868136960. Avec les optimisations (voir edit 1), Il peut calculer les 500 premières entrées en dessous des années 90, ce qui est rapide-bien que la réponse de @David Eisenstat soit probablement meilleure si elle peut être développée. Je pense que prend une approche différente des algorithmes donnés jusqu'à présent, y compris ma propre réponse originale, donc je l'affiche séparément.
Après l'optimisation, j'ai réalisé que je codais vraiment un problème de graphique, alors j'ai réécrit la solution en tant qu'implémentation de graphique (Voir edit 2). L'implémentation du graphe permet plus d'optimisations, est beaucoup plus élégante, plus d'un ordre de grandeur plus rapide, et évolue mieux: elle calcule {[4] } en 1.5 s, par rapport à 27s.
L'idée principale ici est d'utiliser une relation de récursivité. Pour tout ensemble, le nombre de sous-ensembles répondant au critère est la somme de:
- , le nombre de sous-ensembles avec un élément supprimé; et
- le nombre de sous-ensembles avec cet élément définitivement inclus.
Dans le second cas, lorsque l'élément est définitivement inclus, tous les autres éléments qui ne sont pas coprime avec lui doivent être supprimés.
Problèmes D'efficacité:
- j'ai choisi de supprimer l'élément le plus grand pour maximiser les chances que cet élément soit déjà coprime à tous les autres, auquel cas un seul plutôt que deux appels récursifs doivent être faits.
- la mise en cache / mémoization aide.
Code ci-dessous.
#include <cassert>
#include <vector>
#include <set>
#include <map>
#include <algorithm>
#include <iostream>
#include <ctime>
const int PRIMES[] = // http://rlrr.drum-corps.net/misc/primes1.shtml
{ 2, 3, 5, ...
..., 2969, 2971, 2999 };
const int NPRIMES = sizeof(PRIMES) / sizeof(int);
typedef std::set<int> intset;
typedef std::vector<intset> intsetvec;
const int MAXCALC = 200; // answer at http://oeis.org/A084422/b084422.txt
intsetvec primeFactors(MAXCALC +1);
typedef std::vector<int> intvec;
// Caching / memoization
typedef std::map<intvec, double> intvec2dbl;
intvec2dbl set2NumCoPrimeSets;
double NumCoPrimeSets(const intvec& set)
{
if (set.empty())
return 1;
// Caching / memoization
const intvec2dbl::const_iterator i = set2NumCoPrimeSets.find(set);
if (i != set2NumCoPrimeSets.end())
return i->second;
// Result is the number of coprime sets in:
// setA, the set that definitely has the first element of the input present
// + setB, the set the doesn't have the first element of the input present
// Because setA definitely has the first element, we remove elements it isn't coprime with
// We also remove the first element: as this is definitely present it doesn't make any
// difference to the number of sets
intvec setA(set);
const int firstNum = *setA.begin();
const intset& factors = primeFactors[firstNum];
for(int factor : factors) {
setA.erase(std::remove_if(setA.begin(), setA.end(),
[factor] (int i) { return i % factor == 0; } ), setA.end());
}
// If the first element was already coprime with the rest, then we have setA = setB
// and we can do a single call (m=2). Otherwise we have two recursive calls.
double m = 1;
double c = 0;
assert(set.size() - setA.size() > 0);
if (set.size() - setA.size() > 1) {
intvec setB(set);
setB.erase(setB.begin());
c = NumCoPrimeSets(setB);
}
else {
// first elt coprime with rest
m = 2;
}
const double numCoPrimeSets = m * NumCoPrimeSets(setA) + c;
// Caching / memoization
set2NumCoPrimeSets.insert(intvec2dbl::value_type(set, numCoPrimeSets));
return numCoPrimeSets;
}
int main(int argc, char* argv[])
{
// Calculate prime numbers that factor into each number upto MAXCALC
primeFactors[1].insert(1); // convenient
for(int i=2; i<=MAXCALC; ++i) {
for(int j=0; j<NPRIMES; ++j) {
if (i % PRIMES[j] == 0) {
primeFactors[i].insert(PRIMES[j]);
}
}
}
const clock_t start = clock();
for(int n=1; n<=MAXCALC; ++n) {
intvec v;
for(int i=n; i>0; --i) { // reverse order to reduce recursion
v.push_back(i);
}
const clock_t now = clock();
const clock_t ms = now - start;
const double numCoPrimeSubsets = NumCoPrimeSets(v);
std::cout << n << ", " << std::fixed << numCoPrimeSubsets << ", " << ms << "\n";
}
return 0;
}
Temps caractéristiques de l'air beaucoup mieux que ma première réponse. Mais ne sera toujours pas aller jusqu'à 3000 en 5s!
Modifier 1
Il y a quelques optimisations intéressantes qui peuvent être faites à cette méthode. Dans l'ensemble, cela donne une amélioration 4x pour les plus grands n.
- tous les nombres de l'ensemble qui sont déjà coprime peuvent être supprimé en une seule étape de prétraitement: si
mNombre sont supprimés, alors l'ensemble d'origine a 2M facteur fois plus de combinaisons que le réduit (parce que pour chaque coprime, vous pouvez soit l'avoir dans ou hors de l'ensemble indépendamment des autres éléments). - , Plus important encore, il est possible de choisir un élément à supprimer est n'importe où dans l'ensemble. Il s'avère que la suppression de l'élément le plus connecté fonctionne mieux.
- la relation récursive qui a été précédemment utilisé peut être généralisé pour supprimer plus d'un élément où tous les éléments supprimés ont les mêmes facteurs premiers. E. g. pour l'ensemble
{2, 3, 15, 19, 45}, les nombres 15 et 45 ont les mêmes facteurs premiers de 3 et 5. Il y a 2 numéros retirés à la fois, et donc le nombre de sous-ensembles pour{2, 3, 15, 19, 45}= deux fois, le nombre de combinaisons pour 15 ou 45 présenter (pour l'ensemble{2, 19}, car 3 doit être absent si 15 ou 45 sont présents) + le nombre de sous-ensembles pour les 15 et 45 absent (pour l'ensemble{2, 3, 19}) - L'utilisation de
shortpour le type de nombre a amélioré les performances d'environ 10%. - enfin, il est également possible de transformer des ensembles en ensembles avec des facteurs premiers équivalents, dans l'espoir d'obtenir de meilleurs hits de cache en standardisant les ensembles. Par exemple, {[12] } est équivalent (isomorphe) à
2, 4, 6. Ce fut l'idée la plus radicale, mais probablement eu le moins d'effet sur la performance.
Il est probablement beaucoup plus facile de le comprendre avec un exemple concret. J'ai choisi, l'ensemble {1..12} qui est assez grand pour avoir une idée de comment cela fonctionne mais assez petit pour qu'il soit compréhensible.
NumCoPrimeSets({ 1 2 3 4 5 6 7 8 9 10 11 12 })
Removed 3 coprimes, giving set { 2 3 4 5 6 8 9 10 12 } multiplication factor now 8
Removing the most connected number 12 with 8 connections
To get setA, remove all numbers which have *any* of the prime factors { 2 3 }
setA = { 5 }
To get setB, remove 2 numbers which have *exactly* the prime factors { 2 3 }
setB = { 2 3 4 5 8 9 10 }
**** Recursing on 2 * NumCoPrimeSets(setA) + NumCoPrimeSets(setB)
NumCoPrimeSets({ 5 })
Base case return the multiplier, which is 2
NumCoPrimeSets({ 2 3 4 5 8 9 10 })
Removing the most connected number 10 with 4 connections
To get setA, remove all numbers which have *any* of the prime factors { 2 5 }
setA = { 3 9 }
To get setB, remove 1 numbers which have *exactly* the prime factors { 2 5 }
setB = { 2 3 4 5 8 9 }
**** Recursing on 1 * NumCoPrimeSets(setA) + NumCoPrimeSets(setB)
NumCoPrimeSets({ 3 9 })
Transformed 2 primes, giving new set { 2 4 }
Removing the most connected number 4 with 1 connections
To get setA, remove all numbers which have *any* of the prime factors { 2 }
setA = { }
To get setB, remove 2 numbers which have *exactly* the prime factors { 2 }
setB = { }
**** Recursing on 2 * NumCoPrimeSets(setA) + NumCoPrimeSets(setB)
NumCoPrimeSets({ })
Base case return the multiplier, which is 1
NumCoPrimeSets({ })
Base case return the multiplier, which is 1
**** Returned from recursing on 2 * NumCoPrimeSets({ }) + NumCoPrimeSets({ })
Caching for{ 2 4 }: 3 = 2 * 1 + 1
Returning for{ 3 9 }: 3 = 1 * 3
NumCoPrimeSets({ 2 3 4 5 8 9 })
Removed 1 coprimes, giving set { 2 3 4 8 9 } multiplication factor now 2
Removing the most connected number 8 with 2 connections
To get setA, remove all numbers which have *any* of the prime factors { 2 }
setA = { 3 9 }
To get setB, remove 3 numbers which have *exactly* the prime factors { 2 }
setB = { 3 9 }
**** Recursing on 3 * NumCoPrimeSets(setA) + NumCoPrimeSets(setB)
NumCoPrimeSets({ 3 9 })
Transformed 2 primes, giving new set { 2 4 }
Cache hit, returning 3 = 1 * 3
NumCoPrimeSets({ 3 9 })
Transformed 2 primes, giving new set { 2 4 }
Cache hit, returning 3 = 1 * 3
**** Returned from recursing on 3 * NumCoPrimeSets({ 3 9 }) + NumCoPrimeSets({ 3 9 })
Caching for{ 2 3 4 8 9 }: 12 = 3 * 3 + 3
Returning for{ 2 3 4 5 8 9 }: 24 = 2 * 12
**** Returned from recursing on 1 * NumCoPrimeSets({ 3 9 }) + NumCoPrimeSets({ 2 3 4 5 8 9 })
Caching for{ 2 3 4 5 8 9 10 }: 27 = 1 * 3 + 24
Returning for{ 2 3 4 5 8 9 10 }: 27 = 1 * 27
**** Returned from recursing on 2 * NumCoPrimeSets({ 5 }) + NumCoPrimeSets({ 2 3 4 5 8 9 10 })
Caching for{ 2 3 4 5 6 8 9 10 12 }: 31 = 2 * 2 + 27
Returning for{ 1 2 3 4 5 6 7 8 9 10 11 12 }: 248 = 8 * 31
Code ci-dessous
#include <cassert>
#include <vector>
#include <set>
#include <map>
#include <unordered_map>
#include <queue>
#include <algorithm>
#include <fstream>
#include <iostream>
#include <ctime>
typedef short numtype;
const numtype PRIMES[] = // http://rlrr.drum-corps.net/misc/primes1.shtml
...
const numtype NPRIMES = sizeof(PRIMES) / sizeof(numtype);
typedef std::set<numtype> numset;
typedef std::vector<numset> numsetvec;
const numtype MAXCALC = 200; // answer at http://oeis.org/A084422/b084422.txt
numsetvec primeFactors(MAXCALC +1);
typedef std::vector<numtype> numvec;
// Caching / memoization
typedef std::map<numvec, double> numvec2dbl;
numvec2dbl set2NumCoPrimeSets;
double NumCoPrimeSets(const numvec& initialSet)
{
// Preprocessing step: remove numbers which are already coprime
typedef std::unordered_map<numtype, numvec> num2numvec;
num2numvec prime2Elts;
for(numtype num : initialSet) {
const numset& factors = primeFactors[num];
for(numtype factor : factors) {
prime2Elts[factor].push_back(num);
}
}
numset eltsToRemove(initialSet.begin(), initialSet.end());
typedef std::vector<std::pair<numtype,int>> numintvec;
numvec primesRemaining;
for(const num2numvec::value_type& primeElts : prime2Elts) {
if (primeElts.second.size() > 1) {
for (numtype num : primeElts.second) {
eltsToRemove.erase(num);
}
primesRemaining.push_back(primeElts.first);
}
}
double mult = pow(2.0, eltsToRemove.size());
if (eltsToRemove.size() == initialSet.size())
return mult;
// Do the removal by creating a new set
numvec set;
for(numtype num : initialSet) {
if (eltsToRemove.find(num) == eltsToRemove.end()) {
set.push_back(num);
}
}
// Transform to use a smaller set of primes before checking the cache
// (beta code but it seems to work, mostly!)
std::sort(primesRemaining.begin(), primesRemaining.end());
numvec::const_iterator p = primesRemaining.begin();
for(int j=0; p!= primesRemaining.end() && j<NPRIMES; ++p, ++j) {
const numtype primeRemaining = *p;
if (primeRemaining != PRIMES[j]) {
for(numtype& num : set) {
while (num % primeRemaining == 0) {
num = num / primeRemaining * PRIMES[j];
}
}
}
}
// Caching / memoization
const numvec2dbl::const_iterator i = set2NumCoPrimeSets.find(set);
if (i != set2NumCoPrimeSets.end())
return mult * i->second;
// Remove the most connected number
typedef std::unordered_map<numtype, int> num2int;
num2int num2ConnectionCount;
for(numvec::const_iterator srcIt=set.begin(); srcIt!=set.end(); ++srcIt) {
const numtype src = *srcIt;
const numset& srcFactors = primeFactors[src];
for(numvec::const_iterator tgtIt=srcIt +1; tgtIt!=set.end(); ++tgtIt) {
for(numtype factor : srcFactors) {
const numtype tgt = *tgtIt;
if (tgt % factor == 0) {
num2ConnectionCount[src]++;
num2ConnectionCount[tgt]++;
}
}
}
}
num2int::const_iterator connCountIt = num2ConnectionCount.begin();
numtype numToErase = connCountIt->first;
int maxConnCount = connCountIt->second;
for (; connCountIt!=num2ConnectionCount.end(); ++connCountIt) {
if (connCountIt->second > maxConnCount || connCountIt->second == maxConnCount && connCountIt->first > numToErase) {
numToErase = connCountIt->first;
maxConnCount = connCountIt->second;
}
}
// Result is the number of coprime sets in:
// setA, the set that definitely has a chosen element of the input present
// + setB, the set the doesn't have the chosen element(s) of the input present
// Because setA definitely has a chosen element, we remove elements it isn't coprime with
// We also remove the chosen element(s): as they are definitely present it doesn't make any
// difference to the number of sets
numvec setA(set);
const numset& factors = primeFactors[numToErase];
for(numtype factor : factors) {
setA.erase(std::remove_if(setA.begin(), setA.end(),
[factor] (numtype i) { return i % factor == 0; } ), setA.end());
}
// setB: remove all elements which have the same prime factors
numvec setB(set);
setB.erase(std::remove_if(setB.begin(), setB.end(),
[&factors] (numtype i) { return primeFactors[i] == factors; }), setB.end());
const size_t numEltsWithSamePrimeFactors = (set.size() - setB.size());
const double numCoPrimeSets =
numEltsWithSamePrimeFactors * NumCoPrimeSets(setA) + NumCoPrimeSets(setB);
// Caching / memoization
set2NumCoPrimeSets.insert(numvec2dbl::value_type(set, numCoPrimeSets));
return mult * numCoPrimeSets;
}
int main(int argc, char* argv[])
{
// Calculate prime numbers that factor into each number upto MAXCALC
for(numtype i=2; i<=MAXCALC; ++i) {
for(numtype j=0; j<NPRIMES; ++j) {
if (i % PRIMES[j] == 0) {
primeFactors[i].insert(PRIMES[j]);
}
}
}
const clock_t start = clock();
std::ofstream fout("out.txt");
for(numtype n=0; n<=MAXCALC; ++n) {
numvec v;
for(numtype i=1; i<=n; ++i) {
v.push_back(i);
}
const clock_t now = clock();
const clock_t ms = now - start;
const double numCoPrimeSubsets = NumCoPrimeSets(v);
fout << n << ", " << std::fixed << numCoPrimeSubsets << ", " << ms << "\n";
std::cout << n << ", " << std::fixed << numCoPrimeSubsets << ", " << ms << "\n";
}
return 0;
}
Il est possible de traiter jusqu'à n=600 en environ 5 minutes. Le temps semble toujours exponentiel cependant, doublant tous les 50 à 60 n environ. Le graphique pour calculer un seul n est montré ci-dessous.
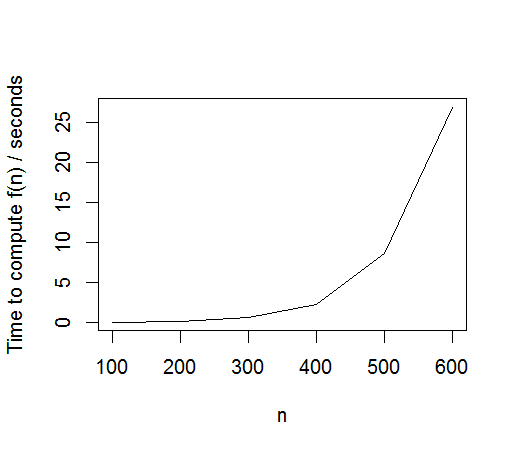
Modifier 2
Cette solution est beaucoup plus naturellement mise en œuvre en termes de graphique. Deux autres optimisations sont apparues:
Plus important encore, si le graphe G peut être partitionné en deux ensembles A et B tels qu'il n'y a pas de connexions entre A et B, alors coprimes(G) = coprimes(A) * coprimes(B).
Deuxièmement, il est possible de réduire tous les nombres pour un ensemble de facteurs premiers en un seul nœud, de sorte que la valeur du nœud est le nombre de nombres pour ses facteurs premiers.
Dans le code ci-dessous, la classe Graph contient la matrice d'adjacence d'origine et les valeurs de nœud, et la classe FilteredGraph contient la liste actuelle des nœuds restants en tant que bitset de sorte que lorsque les nœuds sont supprimés, la nouvelle matrice d'adjacence peut être calculée par masquage de bits (et il y a relativement peu de données à transmettre dans la récursivité).
#include "Primes.h"
#include <cassert>
#include <bitset>
#include <vector>
#include <set>
#include <map>
#include <unordered_map>
#include <algorithm>
#include <iostream>
#include <ctime>
// Graph declaration
const int MAXGROUPS = 1462; // empirically determined
class Graph
{
typedef std::bitset<MAXGROUPS> bitset;
typedef std::vector<bitset> adjmatrix;
typedef std::vector<int> intvec;
public:
Graph(int numNodes)
: m_nodeValues(numNodes), m_adjMatrix(numNodes) {}
void SetNodeValue(int i, int v) { m_nodeValues[i] = v; }
void SetConnection(int i, int j)
{
m_adjMatrix[i][j] = true;
m_adjMatrix[j][i] = true;
}
int size() const { return m_nodeValues.size(); }
private:
adjmatrix m_adjMatrix;
intvec m_nodeValues;
friend class FilteredGraph;
};
class FilteredGraph
{
typedef Graph::bitset bitset;
public:
FilteredGraph(const Graph* unfiltered);
int FirstNode() const;
int RemoveNode(int node);
void RemoveNodesConnectedTo(int node);
double RemoveDisconnectedNodes();
bool AttemptPartition(FilteredGraph* FilteredGraph);
size_t Hash() const { return std::hash<bitset>()(m_includedNodes); }
bool operator==(const FilteredGraph& x) const
{ return x.m_includedNodes == m_includedNodes && x.m_unfiltered == m_unfiltered; }
private:
bitset RawAdjRow(int i) const {
return m_unfiltered->m_adjMatrix[i];
}
bitset AdjRow(int i) const {
return RawAdjRow(i) & m_includedNodes;
}
int NodeValue(int i) const {
return m_unfiltered->m_nodeValues[i];
}
const Graph* m_unfiltered;
bitset m_includedNodes;
};
// Cache
namespace std {
template<>
class hash<FilteredGraph> {
public:
size_t operator()(const FilteredGraph & x) const { return x.Hash(); }
};
}
typedef std::unordered_map<FilteredGraph, double> graph2double;
graph2double cache;
// MAIN FUNCTION
double NumCoPrimesSubSets(const FilteredGraph& graph)
{
graph2double::const_iterator cacheIt = cache.find(graph);
if (cacheIt != cache.end())
return cacheIt->second;
double rc = 1;
FilteredGraph A(graph);
FilteredGraph B(graph);
if (A.AttemptPartition(&B)) {
rc = NumCoPrimesSubSets(A);
A = B;
}
const int nodeToRemove = A.FirstNode();
if (nodeToRemove < 0) // empty graph
return 1;
// Graph B is the graph with a node removed
B.RemoveNode(nodeToRemove);
// Graph A is the graph with the node present -- and hence connected nodes removed
A.RemoveNodesConnectedTo(nodeToRemove);
// The number of numbers in the node is the number of times it can be reused
const double removedNodeValue = A.RemoveNode(nodeToRemove);
const double A_disconnectedNodesMult = A.RemoveDisconnectedNodes();
const double B_disconnectedNodesMult = B.RemoveDisconnectedNodes();
const double A_coprimes = NumCoPrimesSubSets(A);
const double B_coprimes = NumCoPrimesSubSets(B);
rc *= removedNodeValue * A_disconnectedNodesMult * A_coprimes
+ B_disconnectedNodesMult * B_coprimes;
cache.insert(graph2double::value_type(graph, rc));
return rc;
}
// Program entry point
int Sequence2Graph(Graph** ppGraph, int n);
int main(int argc, char* argv[])
{
const clock_t start = clock();
int n=800; // runs in approx 6s on my machine
Graph* pGraph = nullptr;
const int coPrimesRemoved = Sequence2Graph(&pGraph, n);
const double coPrimesMultiplier = pow(2,coPrimesRemoved);
const FilteredGraph filteredGraph(pGraph);
const double numCoPrimeSubsets = coPrimesMultiplier * NumCoPrimesSubSets(filteredGraph);
delete pGraph;
cache.clear(); // as it stands the cache can't cope with other Graph objects, e.g. for other n
const clock_t now = clock();
const clock_t ms = now - start;
std::cout << n << ", " << std::fixed << numCoPrimeSubsets << ", " << ms << "\n";
return 0;
}
// Graph implementation
FilteredGraph::FilteredGraph(const Graph* unfiltered)
: m_unfiltered(unfiltered)
{
for(int i=0; i<m_unfiltered->size(); ++i) {
m_includedNodes.set(i);
}
}
int FilteredGraph::FirstNode() const
{
int firstNode=0;
for(; firstNode<m_unfiltered->size() && !m_includedNodes.test(firstNode); ++firstNode) {
}
if (firstNode == m_unfiltered->size())
return -1;
return firstNode;
}
int FilteredGraph::RemoveNode(int node)
{
m_includedNodes.set(node, false);
return NodeValue(node);
}
void FilteredGraph::RemoveNodesConnectedTo(const int node)
{
const bitset notConnected = ~RawAdjRow(node);
m_includedNodes &= notConnected;
}
double FilteredGraph::RemoveDisconnectedNodes()
{
double mult = 1.0;
for(int i=0; i<m_unfiltered->size(); ++i) {
if (m_includedNodes.test(i)) {
const int conn = AdjRow(i).count();
if (conn == 0) {
m_includedNodes.set(i, false);;
mult *= (NodeValue(i) +1);
}
}
}
return mult;
}
bool FilteredGraph::AttemptPartition(FilteredGraph* pOther)
{
typedef std::vector<int> intvec;
intvec includedNodesCache;
includedNodesCache.reserve(m_unfiltered->size());
for(int i=0; i<m_unfiltered->size(); ++i) {
if (m_includedNodes.test(i)) {
includedNodesCache.push_back(i);
}
}
if (includedNodesCache.empty())
return false;
const int startNode= includedNodesCache[0];
bitset currFoundNodes;
currFoundNodes.set(startNode);
bitset foundNodes;
do {
foundNodes |= currFoundNodes;
bitset newFoundNodes;
for(int i : includedNodesCache) {
if (currFoundNodes.test(i)) {
newFoundNodes |= AdjRow(i);
}
}
newFoundNodes &= ~ foundNodes;
currFoundNodes = newFoundNodes;
} while(currFoundNodes.count() > 0);
const size_t foundCount = foundNodes.count();
const size_t thisCount = m_includedNodes.count();
const bool isConnected = foundCount == thisCount;
if (!isConnected) {
if (foundCount < thisCount) {
pOther->m_includedNodes = foundNodes;
m_includedNodes &= ~foundNodes;
}
else {
pOther->m_includedNodes = m_includedNodes;
pOther->m_includedNodes &= ~foundNodes;
m_includedNodes = foundNodes;
}
}
return !isConnected;
}
// Initialization code to convert sequence from 1 to n into graph
typedef short numtype;
typedef std::set<numtype> numset;
bool setIntersect(const numset& setA, const numset& setB)
{
for(int a : setA) {
if (setB.find(a) != setB.end())
return true;
}
return false;
}
int Sequence2Graph(Graph** ppGraph, int n)
{
typedef std::map<numset, int> numset2int;
numset2int factors2count;
int coPrimesRemoved = n>0; // for {1}
// Calculate all sets of prime factors, and how many numbers belong to each set
for(numtype i=2; i<=n; ++i) {
if ((i > n/2) && (std::find(PRIMES, PRIMES+NPRIMES, i) !=PRIMES+NPRIMES)) {
++coPrimesRemoved;
}
else {
numset factors;
for(numtype j=0; j<NPRIMES && PRIMES[j]<n; ++j) {
if (i % PRIMES[j] == 0) {
factors.insert(PRIMES[j]);
}
}
factors2count[factors]++;
}
}
// Create graph
Graph*& pGraph = *ppGraph;
pGraph = new Graph(factors2count.size());
int srcNodeNum = 0;
for(numset2int::const_iterator i = factors2count.begin(); i!=factors2count.end(); ++i) {
pGraph->SetNodeValue(srcNodeNum, i->second);
numset2int::const_iterator j = i;
int tgtNodeNum = srcNodeNum+1;
for(++j; j!=factors2count.end(); ++j) {
if (setIntersect(i->first, j->first)) {
pGraph->SetConnection(srcNodeNum, tgtNodeNum);
}
++tgtNodeNum;
}
++srcNodeNum;
}
return coPrimesRemoved;
}
Le graphique pour le calcul des coprimes (n) est montré ci-dessous en rouge (avec l'ancienne approche en noir).
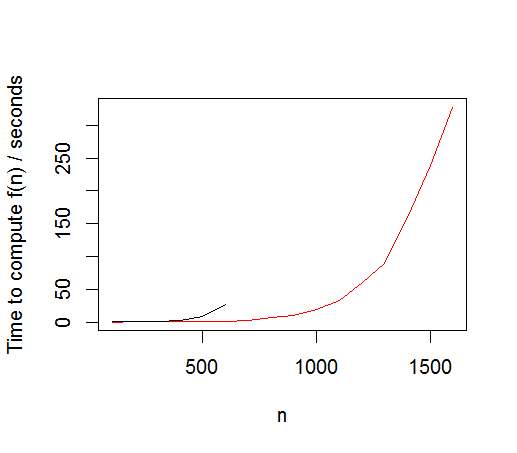
Sur la base du taux d'augmentation (exponentiel) observé, la prédiction pour n=3000 est de 30 heures, en supposant que le programme ne explose pas. Cela commence à sembler réalisable sur le plan informatique, en particulier avec plus d'optimisations, mais est loin des 5s requis! Sans doute la solution requise est courte et douce, mais cela a été amusant...
Voici quelque chose de plutôt simple dans Haskell, qui prend environ 2 secondes pour n = 200 et ralentit de façon exponentielle.
{-# OPTIONS_GHC -O2 #-}
f n = 2^(length second + 1) * (g [] first 0) where
second = filter (\x -> isPrime x && x > div n 2) [2..n]
first = filter (flip notElem second) [2..n]
isPrime k =
null [ x | x <- [2..floor . sqrt . fromIntegral $ k], k `mod`x == 0]
g s rrs depth
| null rrs = 2^(length s - depth)
| not $ and (map ((==1) . gcd r) s) = g s rs depth
+ g s' rs' (depth + 1)
| otherwise = g (r:s) rs depth
where r:rs = rrs
s' = r : filter ((==1) . gcd r) s
rs' = filter ((==1) . gcd r) rs
Voici une approche qui obtient la séquence donnée jusqu'à n=62 en moins de 5s (avec des optimisations, elle fonctionne n=75 en 5s, mais notez que ma deuxième tentative à ce problème fait mieux). Je suppose que la partie modulo du problème consiste simplement à éviter les erreurs numériques lorsque la fonction devient grande, donc je l'ignore pour l'instant.
L'approche est basée sur le fait que nous pouvons choisir au plus un nombre dans un sous-ensemble pour chaque nombre premier.
- nous commençons par le premier, 2. Si nous n'incluons pas 2, alors nous avons 1 combinaison pour ce premier. Si nous incluons 2, alors nous avons autant de combinaisons que ce sont des nombres divisibles par 2.
- ensuite, nous allons sur le deuxième premier, 3, et décider si oui ou non d'inclure cela. Si nous ne l'incluons pas, nous avons 1 combinaison pour ce premier. Si nous incluons 2, alors nous avons autant de combinaisons que ce sont des nombres divisibles par 3.
- ... et ainsi de suite.
En prenant l'exemple {1,2,3,4}, nous cartographions les nombres dans l'ensemble sur les nombres premiers comme suit. J'ai inclus 1 comme premier car cela rend l'exposition plus facile à ce stade.
1 → {1}
2 → {2,4}
3 → {3}
, Nous avons 2 combinaisons pour le "premier" 1 (ne pas l'inclure ou l'1), 3 combinaisons pour le premier 2 (ne pas inclure ou 2 ou 4), et 2 combinaisons de 3 (ne pas inclure ou 3). Donc, le nombre de sous-ensembles est 2 * 3 * 2 = 12.
De Même pour {1,2,3,4,5} nous
1 → {1}
2 → {2,4}
3 → {3}
5 → {5}
Donnant 2 * 3 * 2 * 2= 24.
Mais pour {1,2,3,4,5,6}, les choses ne sont pas si simples. Nous avoir
1 → {1}
2 → {2,4,6}
3 → {3}
5 → {5}
Mais si nous choisissons le nombre 6 pour le premier 2, nous ne pouvons pas choisir un nombre pour le premier 3 (comme une note de bas de page, dans ma première approche, à laquelle je peux revenir, j'ai traité cela comme si les choix pour 3 étaient coupés en deux quand nous avons choisi 6, donc j'ai utilisé 3.5 plutôt que 4 pour le nombre de combinaisons pour le premier 2 et 2 * 3.5 * 2 * 2 = 28 a donné la bonne réponse. Cependant, je ne pouvais pas faire fonctionner cette approche au-delà de n=17.)
La façon dont je traitais cela est de diviser le traitement pour chaque ensemble de facteurs principaux à chaque niveau. Donc {2,4} ont des facteurs premiers {2}, alors que {6} a des facteurs premiers {2,3}. En omettant l'entrée fausse pour 1 (qui n'est pas un premier), nous avons maintenant
2 → {{2}→{2,4}, {2,3}→6}
3 → {{3}→{3}}
5 → {{5}→{5}}
Maintenant, il y a trois chemins pour calculer le nombre de combinaisons, un chemin où nous ne sélectionnons pas le premier 2, et deux chemins où nous le faisons: à travers {2}→{2,4} et à travers {2,3}→6.
- le premier chemin a
1 * 2 * 2 = 4combinaisons parce que nous pouvons soit sélectionner 3 ou non, et nous pouvons soit sélectionnez 5 ou non. - de même la seconde a des combinaisons
2 * 2 * 2 = 8notant que nous pouvons choisir 2 ou 4. - le troisième a
1 * 1 * 2 = 2combinaisons, parce que nous avons seulement un choix pour le premier 3-Ne pas l'utiliser.
Au total, cela nous donne des combinaisons 4 + 8 + 2 = 14 (en tant qu'optimisation, notez que les premier et deuxième chemins auraient pu être réduits ensemble pour obtenir 3 * 2 * 2 = 12). Nous avons également le choix de sélectionner 1 ou non, de sorte que le nombre total de combinaisons est 2 * 14 = 28.
Le code C++ à exécuter récursivement à travers les chemins est ci-dessous. (C'est C++11, écrit sur Visual Studio 2012, mais devrait fonctionner sur d'autres gcc car je n'ai rien inclus De spécifique à la plate-forme).
#include <cassert>
#include <vector>
#include <set>
#include <algorithm>
#include <iterator>
#include <iostream>
#include <ctime>
const int PRIMES[] = // http://rlrr.drum-corps.net/misc/primes1.shtml
{ 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47,
53, 59, 61, 67, 71, 73, 79, 83, 89, 97,
103, 107, 109, 113, 127, 131, 137, 139, 149,
151, 157, 163, 167, 173, 179, 181, 191, 193, 197, 199 };
const int NPRIMES = sizeof(PRIMES) / sizeof(int);
typedef std::vector<int> intvec;
typedef std::set<int> intset;
typedef std::vector<std::set<int>> intsetvec;
struct FactorSetNumbers
{
intset factorSet;
intvec numbers; // we only need to store numbers.size(), but nice to see the vec itself
FactorSetNumbers() {}
FactorSetNumbers(const intset& factorSet_, int n)
: factorSet(factorSet_)
{
numbers.push_back(n);
}
};
typedef std::vector<FactorSetNumbers> factorset2numbers;
typedef std::vector<factorset2numbers> factorset2numbersArray;
double NumCoPrimeSubsets(
const factorset2numbersArray& factorSet2Numbers4FirstPrime,
int primeIndex, const intset& excludedPrimes)
{
const factorset2numbers& factorSet2Numbers = factorSet2Numbers4FirstPrime[primeIndex];
if (factorSet2Numbers.empty())
return 1;
// Firstly, we may choose not to use this prime number at all
double numCoPrimeSubSets = NumCoPrimeSubsets(factorSet2Numbers4FirstPrime,
primeIndex + 1, excludedPrimes);
// Optimization: if we're not excluding anything, then we can collapse
// the above call and the first call in the loop below together
factorset2numbers::const_iterator i = factorSet2Numbers.begin();
if (excludedPrimes.empty()) {
const FactorSetNumbers& factorSetNumbers = *i;
assert(factorSetNumbers.factorSet.size() == 1);
numCoPrimeSubSets *= (1 + factorSetNumbers.numbers.size());
++i;
}
// We are using this prime number. The number of subsets for this prime number is the sum of
// the number of subsets for each set of integers whose factors don't include an excluded factor
for(; i!=factorSet2Numbers.end(); ++i) {
const FactorSetNumbers& factorSetNumbers = *i;
intset intersect;
std::set_intersection(excludedPrimes.begin(),excludedPrimes.end(),
factorSetNumbers.factorSet.begin(),factorSetNumbers.factorSet.end(),
std::inserter(intersect,intersect.begin()));
if (intersect.empty()) {
intset unionExcludedPrimes;
std::set_union(excludedPrimes.begin(),excludedPrimes.end(),
factorSetNumbers.factorSet.begin(),factorSetNumbers.factorSet.end(),
std::inserter(unionExcludedPrimes,unionExcludedPrimes.begin()));
// Optimization: don't exclude on current first prime,
// because can't possibly occur later on
unionExcludedPrimes.erase(unionExcludedPrimes.begin());
numCoPrimeSubSets += factorSetNumbers.numbers.size() *
NumCoPrimeSubsets(factorSet2Numbers4FirstPrime,
primeIndex + 1, unionExcludedPrimes);
}
}
return numCoPrimeSubSets;
}
int main(int argc, char* argv[])
{
const int MAXCALC = 80;
intsetvec primeFactors(MAXCALC +1);
// Calculate prime numbers that factor into each number upto MAXCALC
for(int i=2; i<=MAXCALC; ++i) {
for(int j=0; j<NPRIMES; ++j) {
if (i % PRIMES[j] == 0) {
primeFactors[i].insert(PRIMES[j]);
}
}
}
const clock_t start = clock();
factorset2numbersArray factorSet2Numbers4FirstPrime(NPRIMES);
for(int n=2; n<=MAXCALC; ++n) {
{
// For each prime, store all the numbers whose first prime factor is that prime
// E.g. for the prime 2, for n<=20, we store
// {2}, { 2, 4, 8, 16 }
// {2, 3}, { 6, 12, 18 }
// {2, 5}, { 5, 10, 20 }
// {2, 7}, { 14 }
const int firstPrime = *primeFactors[n].begin();
const int firstPrimeIndex = std::find(PRIMES, PRIMES + NPRIMES, firstPrime) - PRIMES;
factorset2numbers& factorSet2Numbers = factorSet2Numbers4FirstPrime[firstPrimeIndex];
const factorset2numbers::iterator findFactorSet = std::find_if(factorSet2Numbers.begin(), factorSet2Numbers.end(),
[&](const FactorSetNumbers& x) { return x.factorSet == primeFactors[n]; });
if (findFactorSet == factorSet2Numbers.end()) {
factorSet2Numbers.push_back(FactorSetNumbers(primeFactors[n], n));
}
else {
findFactorSet->numbers.push_back(n);
}
// The number of coprime subsets is the number of coprime subsets for the first prime number,
// starting with an empty exclusion list
const double numCoPrimeSubSetsForNEquals1 = 2;
const double numCoPrimeSubsets = numCoPrimeSubSetsForNEquals1 *
NumCoPrimeSubsets(factorSet2Numbers4FirstPrime,
0, // primeIndex
intset()); // excludedPrimes
const clock_t now = clock();
const clock_t ms = now - start;
std::cout << n << ", " << std::fixed << numCoPrimeSubsets << ", " << ms << "\n";
}
}
return 0;
}
Horaires: calcule la séquence jusqu'à 40 à
Bien que cela semble certainement produire les bons chiffres, il est, comme on pouvait s'y attendre, trop coûteux. En particulier il faut au moins temps exponentiel (et très probablement temps combinatoire).
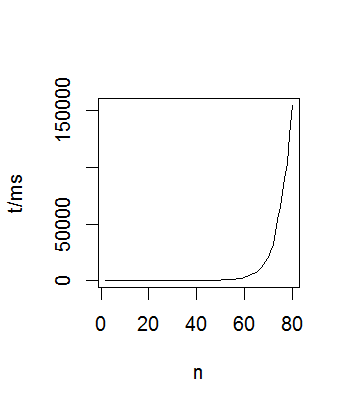
Clairement cette approche ne s'adapte pas comme requis . Cependant, il peut y avoir quelque chose ici qui donne des idées aux autres (ou exclut cette approche comme un échec). Il semble qu'il y ait deux possibilités:
- cette approche peut fonctionner, en raison d'une combinaison des éléments suivants.
- Il y a des optimisations mathématiques intelligentes que je n'ai pas repérées éliminer complètement les calculs.
- Il y a quelques optimisations d'efficacité, par exemple utiliser
bitsetplutôt queset. - mise en cache. Cela semble le plus prometteur, en ce sens que Il pourrait être possible de changer la structure d'appel récursive en une structure arborescente, qui pourrait être mise à jour progressivement (où une relation parent-enfant indique multiplier, et une relation frère indique ajouter).
- cette approche ne peut pas fonctionner.
- voilà est une approche qui n'est en grande partie pas liée à celle-ci.
- Il est possible que la première approche que j'ai utilisée puisse fonctionner. C'était beaucoup plus une solution de "forme fermée" qui fonctionnait très efficacement pour upto
n=17et échouait àn=18et au-dessus, étant sorti par un petit nombre. J'ai passé beaucoup de temps à écrire les modèles et à essayer de comprendre pourquoi il a soudainement échoué pourn=18, mais je ne pouvais pas le voir. Je peux y revenir, ou je l'inclurai comme réponse alternative si quelqu'un l'est intéresser.
Edit : j'ai fait quelques optimisations en utilisant quelques astuces pour éviter de refaire les calculs existants si possible et le code est environ 10 fois plus rapide. Cela semble bien, mais ce n'est qu'une amélioration constante. Ce qui est vraiment nécessaire, c'est un aperçu de ce problème-par exemple, pouvons-nous baser #subsets(n+1) sur #subsets(n)?
Voici comment je le ferais:
- Trouver les facteurs premiers
mod mdes nombres jusqu'àn - créez une file d'attente
qd'ensembles, ajoutez-y l'ensemble vide et définissez counter sur 1 - Alors que la file d'attente n'est pas vide, pop un élément
Xde la file d'attente - Pour tous les nombres
kà partir demax(X)àn, vérifier si les facteurs de l'ensemble se croisent avec les facteurs du numer. Si non, ajouter à la file d'attenteX U ket incrémenter le compteur de 1. Sinon, passez à la prochain K. - compteur de retour
Deux choses importantes doivent être soulignées:
- Vous n'avez pas besoin de la factorisation des nombres jusqu'à
n, mais juste leurs facteurs premiers, cela signifie que, pour 12 vous avez juste besoin de 2 et 3. De cette façon, vérifier si 2 nombres sont coprime devient vérifier si l'intersection de deux ensembles est vide. - , Vous pouvez garder une trace de l'ensemble des facteurs" de chaque nouveau jeu que vous créez, de cette façon, vous n'aurez pas à tester chaque nouveau numéro contre tous les autres nombres de l'ensemble, mais juste intersct ses facteurs principaux mis contre celui de l'ensemble.
Voici un chemin dans O (n * 2^p), où p est le nombre de nombres premiers sous n. La non utilisation du module.
class FailureCoprimeSubsetCounter{
int[] primes;//list of primes under n
PrimeSet[] primeSets;//all 2^primes.length
//A set of primes under n. And a count which goes with it.
class PrimeSet{
BitSet id;//flag x is 1 iff prime[x] is a member of this PrimeSet
long tally;//number of coprime sets that do not have a factor among these primes and do among all the other primes
//that is, we count the number of coprime sets whose maximal coprime subset of primes[] is described by this object
PrimeSet(int np){...}
}
int coprimeSubsets(int n){
//... initialization ...
for(int k=1; k<=n; k++){
PrimeSet p = listToPrimeSet(PrimeFactorizer.factorize(k));
for(int i=0; i<Math.pow(2,primes.length); i++){
//if p AND primes[i] is empty
//add primes[i].tally to PrimeSet[ p OR primes[i] ]
}
}
//return sum of all the tallies
}
}
Mais comme il s'agit d'un problème de concurrence, il doit y avoir une solution plus rapide et plus sale. Et étant donné que cette méthode a besoin de temps et d'espace exponentiels et qu'il y a 430 nombres premiers sous 3000, quelque chose de plus élégant aussi.
EDIT: une approche récursive ajoutée. Résout en 5 secondes jusqu'à n = 50.
#include <iostream>
#include <vector>
using namespace std;
int coPrime[3001][3001] = {0};
int n, m;
// function that checks whether a new integer is coprime with all
//elements in the set S.
bool areCoprime ( int p, vector<int>& v ) {
for ( int i = 0; i < v.size(); i++ ) {
if ( !coPrime[v[i]][p] )
return false;
}
return true;
}
// implementation of Euclid's GCD between a and b
bool isCoprimeNumbers( int a, int b ) {
for ( ; ; ) {
if (!(a %= b)) return b == 1 ;
if (!(b %= a)) return a == 1 ;
}
}
int subsets( vector<int>& coprimeList, int index ) {
int count = 0;
for ( int i = index+1; i <= n; i++ ) {
if ( areCoprime( i, coprimeList ) ) {
count = ( count + 1 ) % m;
vector<int> newVec( coprimeList );
newVec.push_back( i );
count = ( count + subsets( newVec, i ) ) % m;
}
}
return count;
}
int main() {
cin >> n >> m;
int count = 1; // empty set
count += n; // sets with 1 element each.
// build coPrime matrix
for ( int i = 1; i <= 3000; i++ )
for ( int j = i+1; j <= 3000; j++ )
if ( isCoprimeNumbers( i, j ) )
coPrime[i][j] = 1;
// find sets beginning with i
for ( int i = 1; i <= n; i++ ) {
vector<int> empty;
empty.push_back( i );
count = ( count + subsets( empty, i ) ) % m;
}
cout << count << endl;
return 0;
}
Une approche naïve peut être (pour n = 3000):
Étape 1: Construire une matrice booléenne
1. Construire une liste de nombres premiers de 2 à 1500.
2. Pour chaque numéro 1 à 3000, construisez un ensemble de ses facteurs principaux.
3. Comparez chaque paire d'ensembles et obtenez une matrice booléenne [3000] [3000] qui indique si les éléments i et j sont mutuellement coprime (1) ou non (0).
Étape 2: calculer le nombre d'ensembles de coprimes de longueur k (k = 0 à 3000)
1. Initialiser count = 1 ( jeu vide). Maintenant k = 1. Maintenir une liste d'ensembles de longueur K.
2. Construire 3000 ensembles contenant uniquement cet élément particulier. (incrémenter le compte)
3. Scannez chaque élément de k à 3000 et voyez si un nouvel ensemble peut être formé en l'ajoutant à l'un des ensembles existants de longueur K. Note: certains ensembles nouvellement formés peuvent ou non être identiques . Si vous utilisez set of sets, seuls les ensembles uniques seront stockés.
4. Supprimer tous les ensembles qui ont encore une longueur k .
5. Incrémenter le nombre par le nombre actuel d'ensembles uniques.
6. k = k + 1 et passez à l'étape 3.
Vous pouvez également maintenir une liste de produits de chacun des éléments d'un ensemble et vérifier si le nouvel élément est coprime avec le produit. Dans ce cas, vous n'avez pas besoin de stocker la matrice Booléenne.
La complexité de l'algorithme ci-dessus semble quelque part entre O(N^2) et O(N^3).
Code complet en C++: (amélioration: condition ajoutée que l'élément doit être vérifié dans un ensemble seulement s'il est > que la plus grande valeur de l'ensemble).
#include <iostream>
#include <vector>
#include <set>
using namespace std;
int coPrime[3001][3001] = {0};
// function that checks whether a new integer is coprime with all
//elements in the set S.
bool areCoprime ( int p, set<int> S ) {
set<int>::iterator it_set;
for ( it_set = S.begin(); it_set != S.end(); it_set++ ) {
if ( !coPrime[p][*it_set] )
return false;
}
return true;
}
// implementation of Euclid's GCD between a and b
bool isCoprimeNumbers( int a, int b ) {
for ( ; ; ) {
if (!(a %= b)) return b == 1 ;
if (!(b %= a)) return a == 1 ;
}
}
int main() {
int n, m;
cin >> n >> m;
int count = 1; // empty set
set< set<int> > setOfSets;
set< set<int> >::iterator it_setOfSets;
// build coPrime matrix
for ( int i = 1; i <= 3000; i++ )
for ( int j = 1; j <= 3000; j++ )
if ( i != j && isCoprimeNumbers( i, j ) )
coPrime[i][j] = 1;
// build set of sets containing 1 element.
for ( int i = 1; i <= n; i++ ) {
set<int> newSet;
newSet.insert( i );
setOfSets.insert( newSet );
count = (count + 1) % m;
}
// Make sets of length k
for ( int k = 2; k <= n; k++ ) {
// Scane each element from k to n
set< set<int> > newSetOfSets;
for ( int i = k; i <= n; i++ ) {
//Scan each existing set.
it_setOfSets = setOfSets.begin();
for ( ; it_setOfSets != setOfSets.end(); it_setOfSets++ ) {
if ( i > *(( *it_setOfSets ).rbegin()) && areCoprime( i, *it_setOfSets ) ) {
set<int> newSet( *it_setOfSets );
newSet.insert( i );
newSetOfSets.insert( newSet );
}
}
}
count = ( count + newSetOfSets.size() ) % m;
setOfSets = newSetOfSets;
}
cout << count << endl;
return 0;
}
Le code ci-dessus semble donner un résultat correct mais consomme beaucoup de temps: Dites que M est assez grand:
For N = 4, count = 12. (almost instantaneous)
For N = 20, count = 3232. (2-3 seconds)
For N = 25, count = 11168. (2-3 seconds)
For N = 30, count = 31232 (4 seconds)
For N = 40, count = 214272 (30 seconds)
Voici l'approche différente que j'ai mentionnée plus tôt.
Il est en effet beaucoup plus rapide que celui que j'ai utilisé avant. Il peut calculer jusqu'à coprime_subsets(117) en moins de 5 secondes, en utilisant un interpréteur en ligne(ideone).
Le code construit les ensembles possibles à partir de l'ensemble vide et insère chaque nombre dans tous les sous-ensembles possibles.
primes_to_3000 = set([2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151, 157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229, 233, 239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317, 331, 337, 347, 349, 353, 359, 367, 373, 379, 383, 389, 397, 401, 409, 419, 421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 479, 487, 491, 499, 503, 509, 521, 523, 541, 547, 557, 563, 569, 571, 577, 587, 593, 599, 601, 607, 613, 617, 619, 631, 641, 643, 647, 653, 659, 661, 673, 677, 683, 691, 701, 709, 719, 727, 733, 739, 743, 751, 757, 761, 769, 773, 787, 797, 809, 811, 821, 823, 827, 829, 839, 853, 857, 859, 863, 877, 881, 883, 887, 907, 911, 919, 929, 937, 941, 947, 953, 967, 971, 977, 983, 991, 997, 1009, 1013, 1019, 1021, 1031, 1033, 1039, 1049, 1051, 1061, 1063, 1069, 1087, 1091, 1093, 1097, 1103, 1109, 1117, 1123, 1129, 1151, 1153, 1163, 1171, 1181, 1187, 1193, 1201, 1213, 1217, 1223, 1229, 1231, 1237, 1249, 1259, 1277, 1279, 1283, 1289, 1291, 1297, 1301, 1303, 1307, 1319, 1321, 1327, 1361, 1367, 1373, 1381, 1399, 1409, 1423, 1427, 1429, 1433, 1439, 1447, 1451, 1453, 1459, 1471, 1481, 1483, 1487, 1489, 1493, 1499, 1511, 1523, 1531, 1543, 1549, 1553, 1559, 1567, 1571, 1579, 1583, 1597, 1601, 1607, 1609, 1613, 1619, 1621, 1627, 1637, 1657, 1663, 1667, 1669, 1693, 1697, 1699, 1709, 1721, 1723, 1733, 1741, 1747, 1753, 1759, 1777, 1783, 1787, 1789, 1801, 1811, 1823, 1831, 1847, 1861, 1867, 1871, 1873, 1877, 1879, 1889, 1901, 1907, 1913, 1931, 1933, 1949, 1951, 1973, 1979, 1987, 1993, 1997, 1999, 2003, 2011, 2017, 2027, 2029, 2039, 2053, 2063, 2069, 2081, 2083, 2087, 2089, 2099, 2111, 2113, 2129, 2131, 2137, 2141, 2143, 2153, 2161, 2179, 2203, 2207, 2213, 2221, 2237, 2239, 2243, 2251, 2267, 2269, 2273, 2281, 2287, 2293, 2297, 2309, 2311, 2333, 2339, 2341, 2347, 2351, 2357, 2371, 2377, 2381, 2383, 2389, 2393, 2399, 2411, 2417, 2423, 2437, 2441, 2447, 2459, 2467, 2473, 2477, 2503, 2521, 2531, 2539, 2543, 2549, 2551, 2557, 2579, 2591, 2593, 2609, 2617, 2621, 2633, 2647, 2657, 2659, 2663, 2671, 2677, 2683, 2687, 2689, 2693, 2699, 2707, 2711, 2713, 2719, 2729, 2731, 2741, 2749, 2753, 2767, 2777, 2789, 2791, 2797, 2801, 2803, 2819, 2833, 2837, 2843, 2851, 2857, 2861, 2879, 2887, 2897, 2903, 2909, 2917, 2927, 2939, 2953, 2957, 2963, 2969, 2971, 2999])
# primes up to sqrt(3000), used for factoring numbers
primes = set([2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53])
factors = [set() for _ in xrange(3001)]
for p in primes:
for n in xrange(p, 3001, p):
factors[n].add(p)
def coprime_subsets(highest):
count = 1
used = {frozenset(): 1}
for n in xrange(1, highest+1):
if n in primes_to_3000:
# insert the primes into all sets
count <<= 1
if n < 54:
used.update({k.union({n}): v for k, v in used.iteritems()})
else:
for k in used:
used[k] *= 2
else:
for k in used:
# only insert into subsets that don't share any prime factors
if not factors[n].intersection(k):
count += used[k]
used[k.union(factors[n])] += used[k]
return count
Voici mon idée et une implémentation en python. Il semble être lent, mais je ne suis pas sûr si c'est juste la façon dont je testais(en utilisant un en ligne interprète)...
Il se pourrait que l'exécutant sur un "vrai" ordinateur peut faire une différence, mais je ne peux pas tester l'instant.
Il y a deux parties à cette approche:
- Pré-générer une liste de facteurs premiers
- crée une fonction récursive mise en cache pour déterminer le nombre de sous-ensembles possibles:
- pour chaque nombre, vérifiez ses facteurs pour voir s'il peut être ajouté au sous-ensemble
- s'il peut être ajouté, obtenez le compte pour le cas récursif, et ajoutez au total
Après ça, je suppose que vous prenez juste le modulo...
Voici mon implémentation python(version améliorée):
# primes up to 1500
primes = 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151, 157, 163, 167, 173, 179, 181, 191, 193, 197, 199, 211, 223, 227, 229, 233, 239, 241, 251, 257, 263, 269, 271, 277, 281, 283, 293, 307, 311, 313, 317, 331, 337, 347, 349, 353, 359, 367, 373, 379, 383, 389, 397, 401, 409, 419, 421, 431, 433, 439, 443, 449, 457, 461, 463, 467, 479, 487, 491, 499, 503, 509, 521, 523, 541, 547, 557, 563, 569, 571, 577, 587, 593, 599, 601, 607, 613, 617, 619, 631, 641, 643, 647, 653, 659, 661, 673, 677, 683, 691, 701, 709, 719, 727, 733, 739, 743, 751, 757, 761, 769, 773, 787, 797, 809, 811, 821, 823, 827, 829, 839, 853, 857, 859, 863, 877, 881, 883, 887, 907, 911, 919, 929, 937, 941, 947, 953, 967, 971, 977, 983, 991, 997, 1009, 1013, 1019, 1021, 1031, 1033, 1039, 1049, 1051, 1061, 1063, 1069, 1087, 1091, 1093, 1097, 1103, 1109, 1117, 1123, 1129, 1151, 1153, 1163, 1171, 1181, 1187, 1193, 1201, 1213, 1217, 1223, 1229, 1231, 1237, 1249, 1259, 1277, 1279, 1283, 1289, 1291, 1297, 1301, 1303, 1307, 1319, 1321, 1327, 1361, 1367, 1373, 1381, 1399, 1409, 1423, 1427, 1429, 1433, 1439, 1447, 1451, 1453, 1459, 1471, 1481, 1483, 1487, 1489, 1493, 1499
factors = [set() for _ in xrange(3001)]
for p in primes:
for n in xrange(p, 3001, p):
factors[n].add(p)
def coprime_subsets(highest, current=1, factors_used=frozenset(), cache={}):
"""
Determine the number of possible coprime subsets of numbers,
using numbers starting at index current.
factor_product is used for determining if a number can be added
to the current subset.
"""
if (current, factors_used) in cache:
return cache[current, factors_used]
count = 1
for n in xrange(current, highest+1):
if factors_used.intersection(factors[n]):
continue
count += coprime_subsets(highest, n+1, factors_used.union(factors[n]))
cache[current, factors_used] = count
return count
J'ai aussi une autre idée, que je vais essayer de mettre en œuvre si j'ai le temps. Je crois qu'une approche différente pourrait être un peu plus rapide.
Il semble que les réponses proposées, ainsi que le préambule de la question, abordent une question différente de celle posée.
La question était:
Output the number of coprime subsets of {1, 2, 3, ..., n} modulo m.
Les réponses proposées tentent d'en aborder une autre:
Output the number of coprime subsets of {1, 2, 3, ..., n}.
Ces questions ne sont pas équivalentes. Le 1er traite de l'anneau fini Z_m, et le 2ème traite de l'anneau des entiers Z qui a une arithmétique complètement différente.
De plus, la définition " deux entiers sont coprime si leur le plus grand diviseur commun est égal à 1" dans le préambule de la question ne s'applique pas à Z_m: les anneaux finis n'ont pas de comparaison arithmétiquement stable, donc il n'y a pas de "plus grand" diviseur commun.
La même objection s'applique à l'exemple de la question: 3 et 4 ne sont pas relativement premiers modulo 7 car les deux sont divisibles par 2 modulo 7: 4=(2*2)%7 et 3=(2*5)%7.
En fait, l'arithmétique Z_m est si étrange que l'on peut donner la réponse en temps O (1), au moins pour le premier m: pour tout n et premier m il n'y a pas de paires de coprimes modulo M. Voici pourquoi: les éléments Non nuls de Z_m forment un groupe cyclique d'ordre m-1, ce qui implique que pour tous les éléments non nuls a et b de Z_m on peut écrire a = bc pour certains c dans Z_m. cela prouve qu'il]}
De l'exemple dans la question: prenons un coup d'oeil à {2, 3} mod 7 et {3, 4} mod 7: 2=(3*3)%7 et 3=(4*6)%7. Par conséquent, {2,3} ne sont pas coprime dans Z_7 (les deux sont divisibles par 3) et {3,4} sont pas coprime dans Z_7 (les deux sont divisibles par 4).
Considérons maintenant le cas de non-Premier M. écrivez ma comme un produit des puissances premières m=p_1^i_1*...* p_k^i_k. si a et b ont un facteur premier commun qu'ils ne sont clairement pas coprime. Si au moins l'un d'entre eux, disons b, ne divise aucun des nombres premiers p_1,..., p_k alors a et b ont un facteur commun pour à peu près la même raison que dans le cas du premier m: b serait une unité multiplicative de Z_m, et donc a serait divisible par B dans Z_m.
Il reste donc à considérer le cas où m est composite et a et b sont divisibles par des facteurs premiers distincts de m, disons a est divisible par p et b est divisible par Q. Dans ce cas, ils peuvent en effet être des coprimes. Par exemple, 2 et 3 modulo 6 sont des coprimes.
Donc, la question pour les paires de coprime se résume à ces étapes:
Trouver des facteurs premiers de m qui sont inférieurs à n. Si aucun alors il n'y a pas de paires de coprimes.
Énumérer produits de puissances de ces facteurs premiers qui restent les facteurs de m qui sont inférieur à n.
Calcul du nombre de paires Z-comprime parmi celles-ci.