Comment le planificateur Apache Spark scheduler divise-t-il les fichiers en tâches?
dans spark-summit 2014, Aaron donne la parole une compréhension plus profonde de Spark internes , dans sa diapositive, page 17 montrer une étape a été divisé en 4 tâches comme ci-dessous:
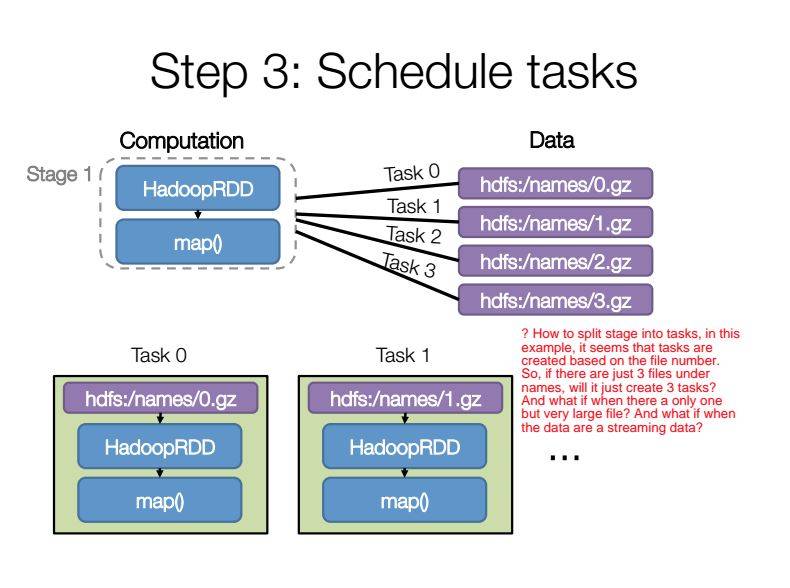
ici, je veux savoir trois choses sur la façon dont une étape est divisée en tâches?
-
dans cet exemple ci-dessus, il semble que le numéro des tâches soit créé en fonction du numéro de dossier, n'est-ce pas?
-
si j'ai raison au point 1, alors s'il n'y avait que 3 fichiers sous des noms de répertoires, cela créerait-il seulement 3 tâches?
-
si j'ai raison au point 2, Que se passe-t-il s'il n'y a qu'un seul fichier, mais un fichier très volumineux? Est-ce que ça divise cette étape en une seule tâche? Et si lorsque les données proviennent d'un flux de source de données?
merci beaucoup, je me sens confus dans Comment le stade été découpé en tâches.
3 réponses
vous pouvez configurer le # de partitions (splits) pour l'ensemble du processus comme deuxième paramètre d'une tâche, par exemple pour paralléliser si nous voulons 3 partitions:
a = sc.parallelize(myCollection, 3)
Spark divisera le travail en tailles relativement égales (*) . Les fichiers volumineux seront ventilés en conséquence - vous pouvez voir la taille réelle par:
rdd.partitions.size
donc non, vous ne finirez pas avec un seul travailleur qui se blottit longtemps sur un seul fichier.
( * ) si vous avez de très petits fichiers, cela peut changer ce traitement. Mais dans tous les cas les gros fichiers vont suivre ce modèle.
la scission se produit en deux étapes:
tout d'abord HDSF divise le fichier logique en fichiers physiques 64MB ou 128MB lorsque le fichier est chargé.
Deuxièmement SPARK programmera une tâche de mappage pour traiter chaque fichier physique. Il y a un processus de planification interne assez complexe puisqu'il y a trois copies de chaque fichier physique stockées sur trois serveurs différents et, pour les gros fichiers logiques, il peut ne pas être possible d'exécuter toutes les tâches à la fois. Façon c'est l'une des principales différences entre les distributions hadoop.
lorsque toutes les tâches de la carte ont exécuté les collecteurs, il est alors possible de mélanger et de réduire les tâches.
étape: nouvelle étape sera créée quand une transformation Large se produit
tâche: sera créé à partir de partitions dans un ouvrier
de Fixation sur le lien pour plus d'explication: Comment DAG fonctionne sous les couvertures dans les RDD?