Comment fonctionne HashPartitioner?
j'ai lu sur la documentation de HashPartitioner . Malheureusement, rien n'a été expliqué à part les appels API. Je suis sous l'hypothèse que HashPartitioner partitionne l'ensemble distribué basé sur le hachage des clés. Par exemple, si mes données sont comme
(1,1), (1,2), (1,3), (2,1), (2,2), (2,3)
donc partitionneur mettrait ceci dans des partitions différentes avec les mêmes clés tombant dans la même partition. Cependant je ne comprends pas la signification de la argument du constructeur
new HashPartitoner(numPartitions) //What does numPartitions do?
pour l'ensemble de données ci-dessus, en quoi les résultats différeraient-ils si je le faisais
new HashPartitoner(1)
new HashPartitoner(2)
new HashPartitoner(10)
alors comment fonctionne HashPartitioner ?
3 réponses
Eh bien, permet de rendre votre ensemble de données légèrement plus intéressant:
val rdd = sc.parallelize(for {
x <- 1 to 3
y <- 1 to 2
} yield (x, None), 8)
nous avons six éléments:
rdd.count
Long = 6
pas de programme de partitionnement:
rdd.partitioner
Option[org.apache.spark.Partitioner] = None
et huit partitions:
rdd.partitions.length
Int = 8
permet maintenant de définir petit helper pour compter le nombre d'éléments par partition:
import org.apache.spark.rdd.RDD
def countByPartition(rdd: RDD[(Int, None.type)]) = {
rdd.mapPartitions(iter => Iterator(iter.length))
}
Puisque nous n'avons pas notre ensemble de données est distribué uniformément entre les partitions ( schéma de partitionnement par défaut dans Spark ):
countByPartition(rdd).collect()
Array[Int] = Array(0, 1, 1, 1, 0, 1, 1, 1)

permet maintenant de repartitionner notre ensemble de données:
import org.apache.spark.HashPartitioner
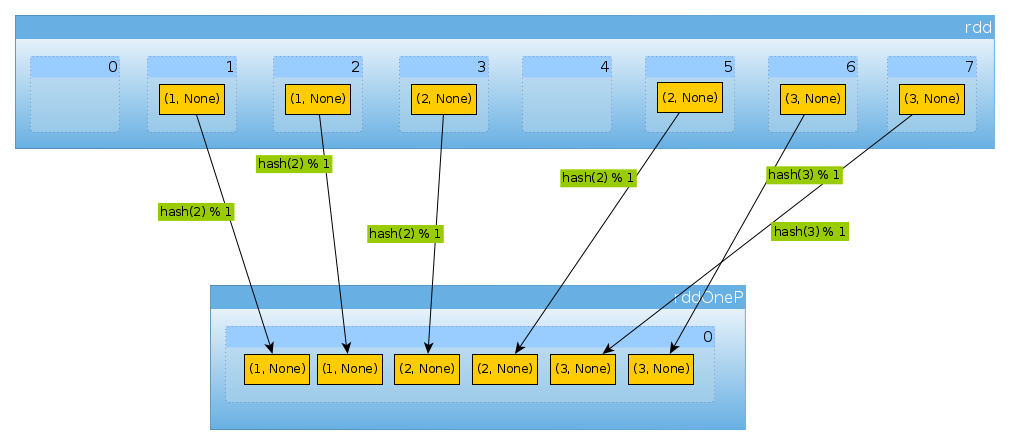
val rddOneP = rdd.partitionBy(new HashPartitioner(1))
depuis que le paramètre est passé à HashPartitioner définit le nombre de partitions, nous nous attendons à une partition:
rddOneP.partitions.length
Int = 1
comme nous n'avons qu'une partition, elle contient tous les éléments:
countByPartition(rddOneP).collect
Array[Int] = Array(6)
noter que l'ordre des valeurs après le mélange n'est pas déterministe.
même façon si nous utilisons HashPartitioner(2)
val rddTwoP = rdd.partitionBy(new HashPartitioner(2))
nous aurons 2 partitions:
rddTwoP.partitions.length
Int = 2
Puisque rdd est divisé par des données clés ne sera plus distribué uniformément plus:
countByPartition(rddTwoP).collect()
Array[Int] = Array(2, 4)
parce qu'avec trois touches et seulement deux valeurs différentes de hashCode mod numPartitions il n'y a rien d'inattendu ici:
(1 to 3).map((k: Int) => (k, k.hashCode, k.hashCode % 2))
scala.collection.immutable.IndexedSeq[(Int, Int, Int)] = Vector((1,1,1), (2,2,0), (3,3,1))
juste pour confirmer ce qui précède:
rddTwoP.mapPartitions(iter => Iterator(iter.map(_._1).toSet)).collect()
Array[scala.collection.immutable.Set[Int]] = Array(Set(2), Set(1, 3))
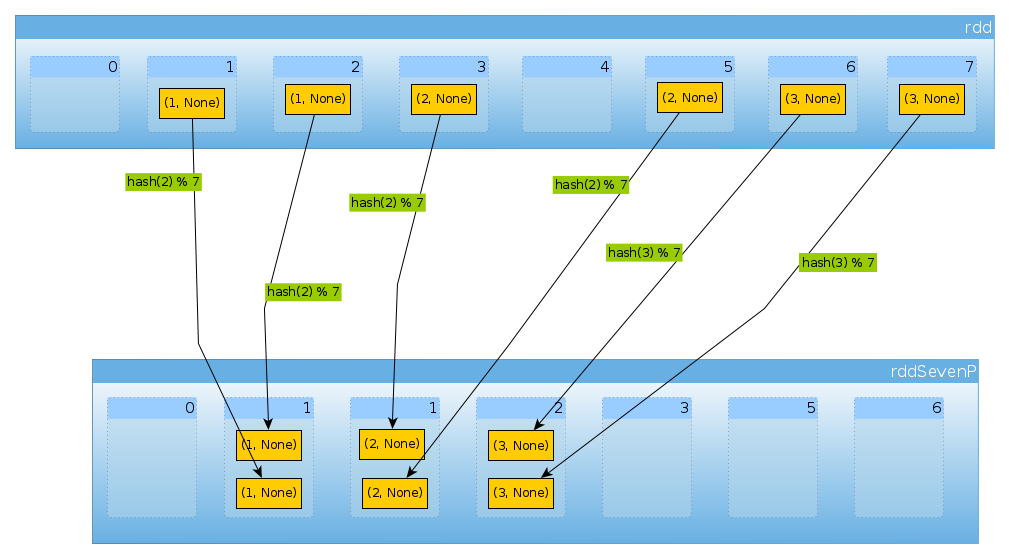
enfin avec HashPartitioner(7) nous obtenons sept partitions, trois non vides avec 2 éléments chacun:
val rddSevenP = rdd.partitionBy(new HashPartitioner(7))
rddSevenP.partitions.length
Int = 7
countByPartition(rddTenP).collect()
Array[Int] = Array(0, 2, 2, 2, 0, 0, 0)
résumé et Notes
-
HashPartitionerprend un seul argument qui définit le nombre de partitions -
les valeurs sont affectées à partitions utilisant
hashde touches.hashfonction peut différer selon la langue (Scala RDD peut utiliserhashCode,DataSetsutiliser MurmurHash 3, PySpark,portable_hash).dans un cas simple comme celui-ci, où la clé est un petit entier, vous pouvez supposer que
hashest une identité (i = hash(i)).L'API de Scala utilise
nonNegativeModpour déterminer la partition basée sur hash calculé, -
si la distribution des clés n'est pas uniforme, vous pouvez vous retrouver dans des situations où une partie de votre cluster est inactif
-
les clés doivent être hachables. Vous pouvez vérifier ma réponse pour une liste comme une clé pour reduceByKey de PySpark pour lire à propos de PySpark questions spécifiques. Un autre problème possible est souligné par documentation Hashparer :
les matrices Java ont des hashCodes qui sont basés sur l'identité des matrices plutôt que sur leur contenu, donc tenter de partager un RDD[Array[ ]] ou RDD[(Array[ ], _)] en utilisant un Hashpartioner produira un résultat inattendu ou incorrect.
-
en Python 3, vous devez vous assurer que le hachage est cohérent. Voir Qu'est-ce qui fait Exception: L'aléatoire de hachage de chaîne doit être désactivé via PYTHONHASHSEED moyen dans pyspark?
-
n'est ni injectif ni surjectif. Plusieurs clés peuvent être attribuées à une seule partition et certaines partitions peuvent rester vides.
-
veuillez noter que les méthodes actuellement basées sur le hash ne fonctionnent pas dans Scala lorsqu'elles sont combinées avec des classes de cas définies par REPL ( égalité des classes de cas en Apache Spark ).
-
HashPartitioner(ou tout autrePartitioner) mélange les données. À moins que le partitionnement soit réutilisé entre plusieurs opérations, il ne réduit pas la quantité de données à mélanger.
RDD est distribuée cela signifie qu'il est fractionné sur un certain nombre de pièces. Chacune de ces cloisons est potentiellement sur une machine différente. Hash partitioner avec arument numPartitions tuyaux sur quelle partition placer la paire (key, value) de la manière suivante:
- crée exactement
numPartitionspartitions. - Places
(key, value)dans la partition avec le numéroHash(key) % numPartitions
la méthode HashPartitioner.getPartition prend comme argument une clé et renvoie le index de la partition à laquelle la clé appartient. Le partitioner doit savoir ce que sont les indices valides, de sorte qu'il retourne des nombres dans la bonne gamme. Le nombre de partitions est spécifié par l'argument du constructeur numPartitions .
l'implémentation renvoie approximativement key.hashCode() % numPartitions . Voir Outil De Partitionnement.scala pour plus de détails.