Comment transformer une base de données en une série de listes?
j'ai eu à faire plusieurs fois et je suis toujours frustré. J'ai un dataframe:
df = pd.DataFrame([[1, 2, 3, 4], [5, 6, 7, 8]], ['a', 'b'], ['A', 'B', 'C', 'D'])
print df
A B C D
a 1 2 3 4
b 5 6 7 8
je veux tourner df en:
pd.Series([[1, 2, 3, 4], [5, 6, 7, 8]], ['a', 'b'])
a [1, 2, 3, 4]
b [5, 6, 7, 8]
dtype: object
j'ai essayé
df.apply(list, axis=1)
Qui vient de me le de la même df
Quelle est une façon pratique et efficace de le faire?
3 réponses
Vous pouvez d'abord convertir DataFramenumpy array par values, puis convertir en liste et créer la dernière nouvelle Series index df si besoin solution plus rapide:
print (pd.Series(df.values.tolist(), index=df.index))
a [1, 2, 3, 4]
b [5, 6, 7, 8]
dtype: object
Timings avec de petites DataFrame:
In [76]: %timeit (pd.Series(df.values.tolist(), index=df.index))
1000 loops, best of 3: 295 µs per loop
In [77]: %timeit pd.Series(df.T.to_dict('list'))
1000 loops, best of 3: 685 µs per loop
In [78]: %timeit df.T.apply(tuple).apply(list)
1000 loops, best of 3: 958 µs per loop
et avec de gros:
from string import ascii_letters
letters = list(ascii_letters)
df = pd.DataFrame(np.random.choice(range(10), (52 ** 2, 52)),
pd.MultiIndex.from_product([letters, letters]),
letters)
In [71]: %timeit (pd.Series(df.values.tolist(), index=df.index))
100 loops, best of 3: 2.06 ms per loop
In [72]: %timeit pd.Series(df.T.to_dict('list'))
1 loop, best of 3: 203 ms per loop
In [73]: %timeit df.T.apply(tuple).apply(list)
1 loop, best of 3: 506 ms per loop
pandas s'efforce de rendre les images de données pratiques. En tant que tel, il interprète les listes et les tableaux comme des choses que vous voudriez diviser en colonnes. Je ne vais pas me plaindre, c'est presque toujours utile.
j'ai fait cela de deux façons.
Option 1:
# Only works with a non MultiIndex
# and its slow, so don't use it
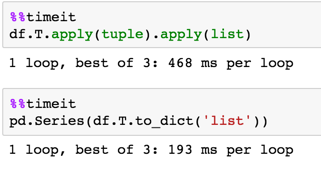
df.T.apply(tuple).apply(list)
Option 2:
pd.Series(df.T.to_dict('list'))
les Deux de vous donner:
a [1, 2, 3, 4]
b [5, 6, 7, 8]
dtype: object
Cependant Option 2 échelles mieux.
Calendrier
donné df
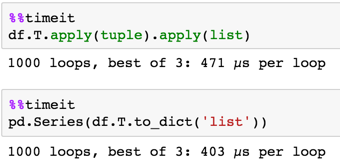
beaucoup plus grand df
from string import ascii_letters
letters = list(ascii_letters)
df = pd.DataFrame(np.random.choice(range(10), (52 ** 2, 52)),
pd.MultiIndex.from_product([letters, letters]),
letters)
Résultats df.T.apply(tuple).apply(list) sont erronés parce que cette solution ne fonctionne pas sur un MultiIndex.
Dataframe à la liste de conversion
List_name =df_name.values.tolist()