Comment puis-je me connecter à un fichier formaté CSV en utilisant SQLPLUS?
je veux extraire quelques requêtes vers un format de sortie CSV. Malheureusement, je ne peux pas utiliser N'importe quel client SQL de fantaisie ou n'importe quelle langue pour le faire. Je dois utiliser SQLPLUS.
Comment faire?
13 réponses
vous pouvez aussi utiliser ce qui suit, bien qu'il introduise des espaces entre les champs.
set colsep , -- separate columns with a comma
set pagesize 0 -- No header rows
set trimspool on -- remove trailing blanks
set headsep off -- this may or may not be useful...depends on your headings.
set linesize X -- X should be the sum of the column widths
set numw X -- X should be the length you want for numbers (avoid scientific notation on IDs)
spool myfile.csv
select table_name, tablespace_name
from all_tables
where owner = 'SYS'
and tablespace_name is not null;
sortie sera comme:
TABLE_PRIVILEGE_MAP ,SYSTEM
SYSTEM_PRIVILEGE_MAP ,SYSTEM
STMT_AUDIT_OPTION_MAP ,SYSTEM
DUAL ,SYSTEM
...
Ce serait beaucoup moins fastidieuse que de taper tous les champs et la concaténation avec les virgules. Vous pouvez suivre avec un script simple sed pour supprimer les espaces qui apparaissent avant une virgule, Si vous voulez.
quelque chose comme ça pourrait marcher...(mon sed compétences sont très rouillés, donc cela aura probablement besoin de travail)
sed 's/\s+,/,/' myfile.csv
j'utilise cette commande pour les scripts qui extraient des données pour les tables dimensionnelles (DW). Donc, j'utilise la syntaxe suivante:
set colsep '|'
set echo off
set feedback off
set linesize 1000
set pagesize 0
set sqlprompt ''
set trimspool on
set headsep off
spool output.dat
select '|', <table>.*, '|'
from <table>
where <conditions>
spool off
et travaux. Je n'utilise pas sed pour formater le fichier de sortie.
je vois un problème similaire...
j'ai besoin de bobiner le fichier CSV de SQLPLUS, mais la sortie A 250 colonnes.
ce que j'ai fait pour éviter le formatage ennuyeux de la sortie SQLPLUS:
set linesize 9999
set pagesize 50000
spool myfile.csv
select x
from
(
select col1||';'||col2||';'||col3||';'||col4||';'||col5||';'||col6||';'||col7||';'||col8||';'||col9||';'||col10||';'||col11||';'||col12||';'||col13||';'||col14||';'||col15||';'||col16||';'||col17||';'||col18||';'||col19||';'||col20||';'||col21||';'||col22||';'||col23||';'||col24||';'||col25||';'||col26||';'||col27||';'||col28||';'||col29||';'||col30 as x
from (
... here is the "core" select
)
);
spool off
le problème est que vous perdrez les noms d'en-tête de colonne...
vous pouvez ajouter ceci:
set heading off
spool myfile.csv
select col1_name||';'||col2_name||';'||col3_name||';'||col4_name||';'||col5_name||';'||col6_name||';'||col7_name||';'||col8_name||';'||col9_name||';'||col10_name||';'||col11_name||';'||col12_name||';'||col13_name||';'||col14_name||';'||col15_name||';'||col16_name||';'||col17_name||';'||col18_name||';'||col19_name||';'||col20_name||';'||col21_name||';'||col22_name||';'||col23_name||';'||col24_name||';'||col25_name||';'||col26_name||';'||col27_name||';'||col28_name||';'||col29_name||';'||col30_name from dual;
select x
from
(
select col1||';'||col2||';'||col3||';'||col4||';'||col5||';'||col6||';'||col7||';'||col8||';'||col9||';'||col10||';'||col11||';'||col12||';'||col13||';'||col14||';'||col15||';'||col16||';'||col17||';'||col18||';'||col19||';'||col20||';'||col21||';'||col22||';'||col23||';'||col24||';'||col25||';'||col26||';'||col27||';'||col28||';'||col29||';'||col30 as x
from (
... here is the "core" select
)
);
spool off
je sais que c'est un peu hardcore, mais ça marche pour moi...
avec les nouvelles versions des outils client, il existe plusieurs options pour formater la sortie de requête. Le reste est à la bobine dans un fichier ou enregistrer la sortie dans un fichier en fonction de l'outil client. Voici quelques exemples:
- SQL * Plus
en utilisant les commandes SQL*Plus que vous pourriez formater pour obtenir votre sortie désirée. Utilisez SPOOL pour bobiner la sortie vers un fichier.
par exemple,
SQL> SET colsep ,
SQL> SET pagesize 20
SQL> SET trimspool ON
SQL> SET linesize 200
SQL> SELECT * FROM scott.emp;
EMPNO,ENAME ,JOB , MGR,HIREDATE , SAL, COMM, DEPTNO
----------,----------,---------,----------,---------,----------,----------,----------
7369,SMITH ,CLERK , 7902,17-DEC-80, 800, , 20
7499,ALLEN ,SALESMAN , 7698,20-FEB-81, 1600, 300, 30
7521,WARD ,SALESMAN , 7698,22-FEB-81, 1250, 500, 30
7566,JONES ,MANAGER , 7839,02-APR-81, 2975, , 20
7654,MARTIN ,SALESMAN , 7698,28-SEP-81, 1250, 1400, 30
7698,BLAKE ,MANAGER , 7839,01-MAY-81, 2850, , 30
7782,CLARK ,MANAGER , 7839,09-JUN-81, 2450, , 10
7788,SCOTT ,ANALYST , 7566,09-DEC-82, 3000, , 20
7839,KING ,PRESIDENT, ,17-NOV-81, 5000, , 10
7844,TURNER ,SALESMAN , 7698,08-SEP-81, 1500, , 30
7876,ADAMS ,CLERK , 7788,12-JAN-83, 1100, , 20
7900,JAMES ,CLERK , 7698,03-DEC-81, 950, , 30
7902,FORD ,ANALYST , 7566,03-DEC-81, 3000, , 20
7934,MILLER ,CLERK , 7782,23-JAN-82, 1300, , 10
14 rows selected.
SQL>
- SQL Developer Version pre 4.1
alternativement, vous pouvez utiliser le nouveau /*csv*/ indice dans développeur SQL .
/*csv*/
par exemple, dans ma SQL Developer Version 3.2.20.10 :
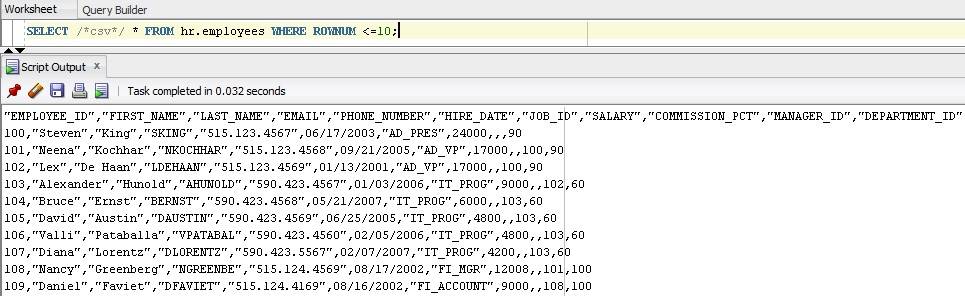
Maintenant, vous pouvez enregistrer la sortie dans un fichier.
- SQL Developer Version 4.1
nouveau dans la version 4.1 de SQL Developer, utilisez ce qui suit tout comme la commande sqlplus et exécutez comme script. Pas besoin de l'indicateur dans la requête.
SET SQLFORMAT csv
Maintenant, vous pouvez enregistrer la sortie dans un fichier.
Si vous utilisez 12.2, vous pouvez simplement dire
set markup csv on
c'est brut, mais:
set pagesize 0 linesize 500 trimspool on feedback off echo off
select '"' || empno || '","' || ename || '","' || deptno || '"' as text
from emp
spool emp.csv
/
spool off
je sais qu'il s'agit d'un vieux fil, mais j'ai remarqué que personne n'a mentionné l'option underline, qui peut supprimer les underlines sous les titres de colonne.
set pagesize 50000--50k is the max as of 12c
set linesize 10000
set trimspool on --remove trailing blankspaces
set underline off --remove the dashes/underlines under the col headers
set colsep ~
select * from DW_TMC_PROJECT_VW;
vous pouvez explicitement formater la requête pour produire une chaîne délimitée avec quelque chose comme:
select '"'||foo||'","'||bar||'"'
from tab
Et configurer les options de sortie approprié. En option, la variable COLSEP sur SQLPlus vous permettra de produire des fichiers délimités sans avoir à générer explicitement une chaîne avec les champs concaténés ensemble. Cependant, vous devrez placer des guillemets autour des chaînes sur les colonnes qui pourraient contenir des caractères virgule intégrés.
préfère utiliser "set colsep" dans sqlplus prompt au lieu d'éditer col name un par un. Utiliser sed pour éditer le fichier de sortie.
set colsep '","' -- separate columns with a comma
sed 's/^/"/;s/$/"/;s/\s *"/"/g;s/"\s */"/g' $outfile > $outfile.csv
j'ai écrit une fois un petit script SQL*Plus qui utilise dbms_sql et dbms_output pour créer un csv (en fait un ssv). Vous pouvez le trouver sur mon dépôt githup .
utilisez vi ou vim pour écrire le sql, utilisez colsep avec un control - a (en vi et vim précèdent le ctrl-A avec un ctrl-v). Assurez-vous de mettre les linesize et pagesize à quelque chose de rationnel et tourner sur trimspool et trimout.
envoie ça dans un fichier. Puis...
sed -e 's/,/;/g' -e 's/ *{ctrl-a} */,/g' {spooled file} > output.csv
cette chose sed peut être transformée en script. Le " *" avant et après le ctrl-Un serre tous les espaces inutiles. N'est-ce pas génial qu'ils aient pris la peine d'activer html sortie de sqlplus mais pas de CSV natif?????
je le fais de cette façon parce qu'il traite les virgules dans les données. Je tourne à des points-virgules.
vous devez être conscient que les valeurs des champs peuvent contenir des virgules et des guillemets, de sorte que certaines des réponses suggérées ne fonctionneraient pas, car le fichier de sortie CSV ne serait pas correct. Pour remplacer les guillemets dans un champ, et le remplacer par le caractère double guillemet, vous pouvez utiliser la fonction de remplacement que oracle fournit, pour changer un simple guillemet à double guillemet.
set echo off
set heading off
set feedback off
set linesize 1024 -- or some other value, big enough
set pagesize 50000
set verify off
set trimspool on
spool output.csv
select trim(
'"' || replace(col1, '"', '""') ||
'","' || replace(col2, '"', '""') ||
'","' || replace(coln, '"', '""') || '"' ) -- etc. for all the columns
from yourtable
/
spool off
Ou, si vous voulez l'apostrophe pour les champs:
set echo off
set heading off
set feedback off
set linesize 1024 -- or some other value, big enough
set pagesize 50000
set verify off
set trimspool on
spool output.csv
select trim(
'"' || replace(col1, '''', '''''') ||
'","' || replace(col2, '''', '''''') ||
'","' || replace(coln, '''', '''''') || '"' ) -- etc. for all the columns
from yourtable
/
spool off
vous pouvez utiliser un indice csv. Voir l'exemple suivant:
select /*csv*/ table_name, tablespace_name
from all_tables
where owner = 'SYS'
and tablespace_name is not null;