Comment puis-je segmenter un document en utilisant Tesseract puis sortir les boîtes de délimitation et les étiquettes résultantes
J'essaie de faire en sorte que Tesseract produise un fichier avec des boîtes délimitées qui résultent de la segmentation de la page (pré OCR). Je sais qu'il doit être capable de faire cela "hors des sentiers battus" en raison des résultats présentés aux concours ICDAR où les participants devaient segmenter et divers documents (document académique ici). Voici un exemple de ce document illustrant ce que je veux créer:

j'ai construit la dernière version de tesseract en utilisant brew,brew install tesseract --HEAD, et ont essayé de modifier les fichiers de configuration situés dans /usr/local/Cellar/tesseract/HEAD/share/tessdata/configs/ pour la sortie des boîtes étiquetées. La sortie reçue en utilisant hocr comme la configuration, i.e.
tesseract infile.tiff outfile_stem -l eng -psm 1 hocr
donne une boîte de limite pour tout et a un certain étiquetage dans class par exemple, les balises
<p class='ocr_par' dir='ltr' id='par_5_82' title="bbox 2194 4490 3842 4589">
<span class='ocr_line' id='line_5_142' ...
mais je ne peux pas visualiser ce. Existe-t-il un outil standard pour visualiser les fichiers hOCR, ou est-ce que la possibilité de créer un fichier de sortie avec des boîtes de limites intégrées dans Tesseract?
la tête actuelle détails de la version:
tesseract 3.04.00
leptonica-1.71
libjpeg 8d : libpng 1.6.16 : libtiff 4.0.3 : zlib 1.2.5
Modifier
je cherche vraiment à atteindre cet objectif en utilisant l'outil en ligne de commande (comme dans les exemples ci-dessus). @nguyenq m'a montré le référence API, malheureusement je n'ai pas d'expérience c++. Si la seule solution est d'utiliser L'API, pouvez-vous fournir un exemple rapide de python?
5 réponses
Succès. Merci beaucoup pour le peuple à l' la Reconnaissance des formes et Analyse d'Image, Laboratoire de Recherche (PRImA) pour la production d'outils pour les gérer. Vous pouvez les obtenir gratuitement sur leur site web ou github.
ci-dessous je donne la solution complète pour un Mac fonctionnant 10.10 et en utilisant le homebrew gestionnaire de paquets. J'utilise vin exécuter windows les fichiers exécutables.
vue d'ensemble
- outils de téléchargement: Tesseract OCR to Page (TPT) et Page Viewer (PVT)
- utilisez le TPT pour exécuter tesseract sur votre document et convertir le xml HOCR en une page xml
- utilisez le PVT pour visualiser l'image originale avec l'information xml superposée
Code
brew install wine # takes a little while >10m
brew install gs # only for generating a tif example. Not required, you can use Preview
brew install wget # only for downloading example paper. Not required, you can do so manually!
cd ~/Downloads
wget -O paper.pdf "http://www.prima.cse.salford.ac.uk/www/assets/papers/ICDAR2013_Antonacopoulos_HNLA2013.pdf"
# This command can be ommitted and you can do the conversion to tiff with Preview
gs \
-o paper-%d.tif \
-sDEVICE=tiff24nc \
-r300x300 \
paper.pdf
cd ~/Downloads
# ttptool is the location you downloaded the Tesseract to PAGE tool to
ttptool="/Users/Me/Project/tools/TesseractToPAGE 1.3"
# sudo chmod 777 "$ttptool/bin/PRImA_Tesseract-1-3-78.exe"
touch "$ttptool/log.txt"
wine "$ttptool/bin/PRImA_Tesseract-1-3-78.exe" \
-inp-img "$dl/Downloads/paper-3.tif" \
-out-xml "$dl/Downloads/paper-3-tool.xml" \
-rec-mode layout>>log.txt
# pvtool is the location you downloaded the PAGE Viewer tool to
pvtool="/Users/Me/Project/tools/PAGEViewerMacOS_1.1/JPageViewer 1.1 (Mac OS, 64 bit)"
cd "$pvtool"
dl=~
java -XstartOnFirstThread -jar JPageViewer.jar "$dl/Downloads/paper-3-tool.xml" "$dl/Downloads/paper-3.tif"
Résultats
Document avec recouvrement (rollover to see texte et tapez)
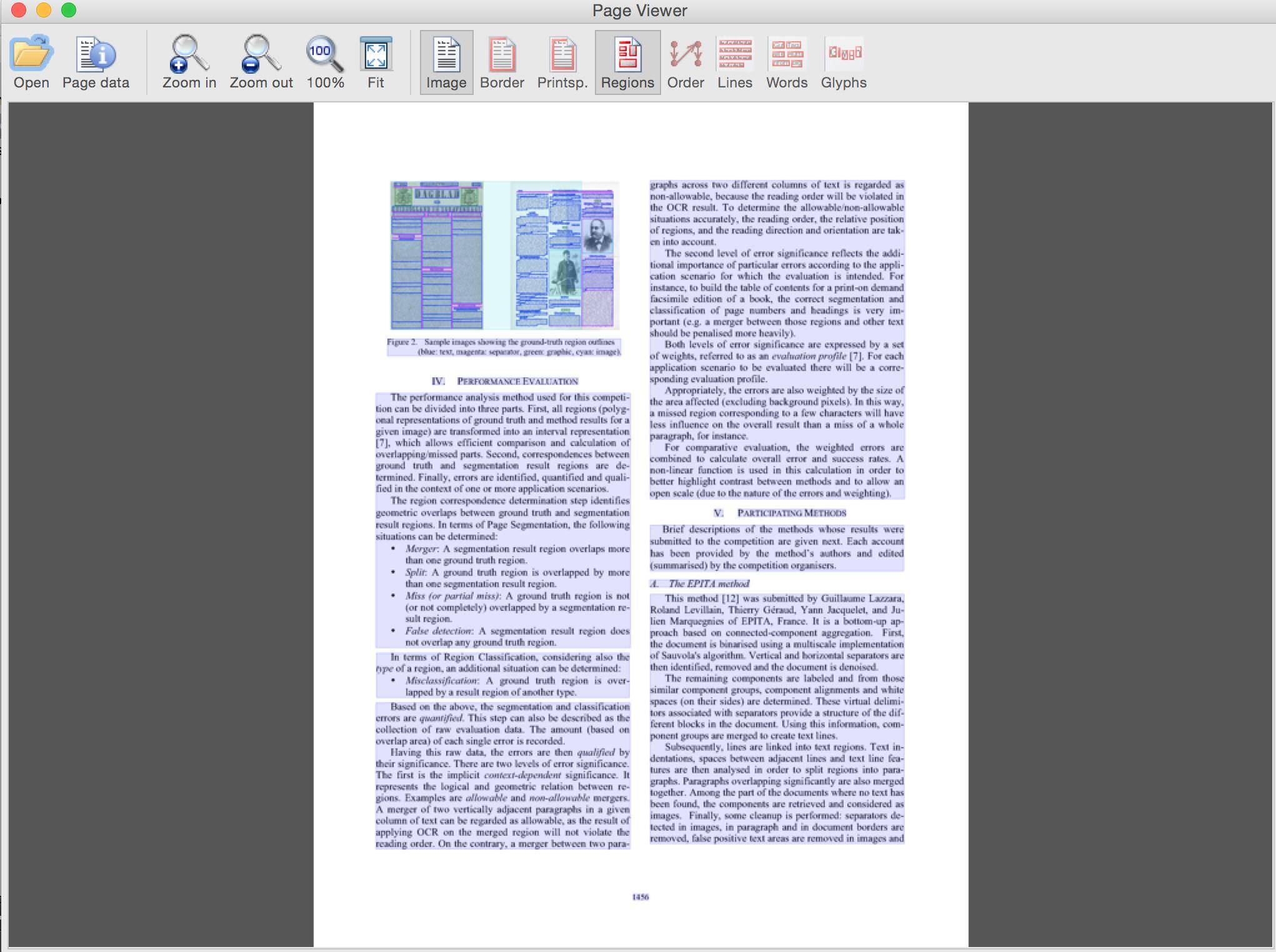 Superposition seule (utilisez les boutons GUI pour basculer)
Superposition seule (utilisez les boutons GUI pour basculer)
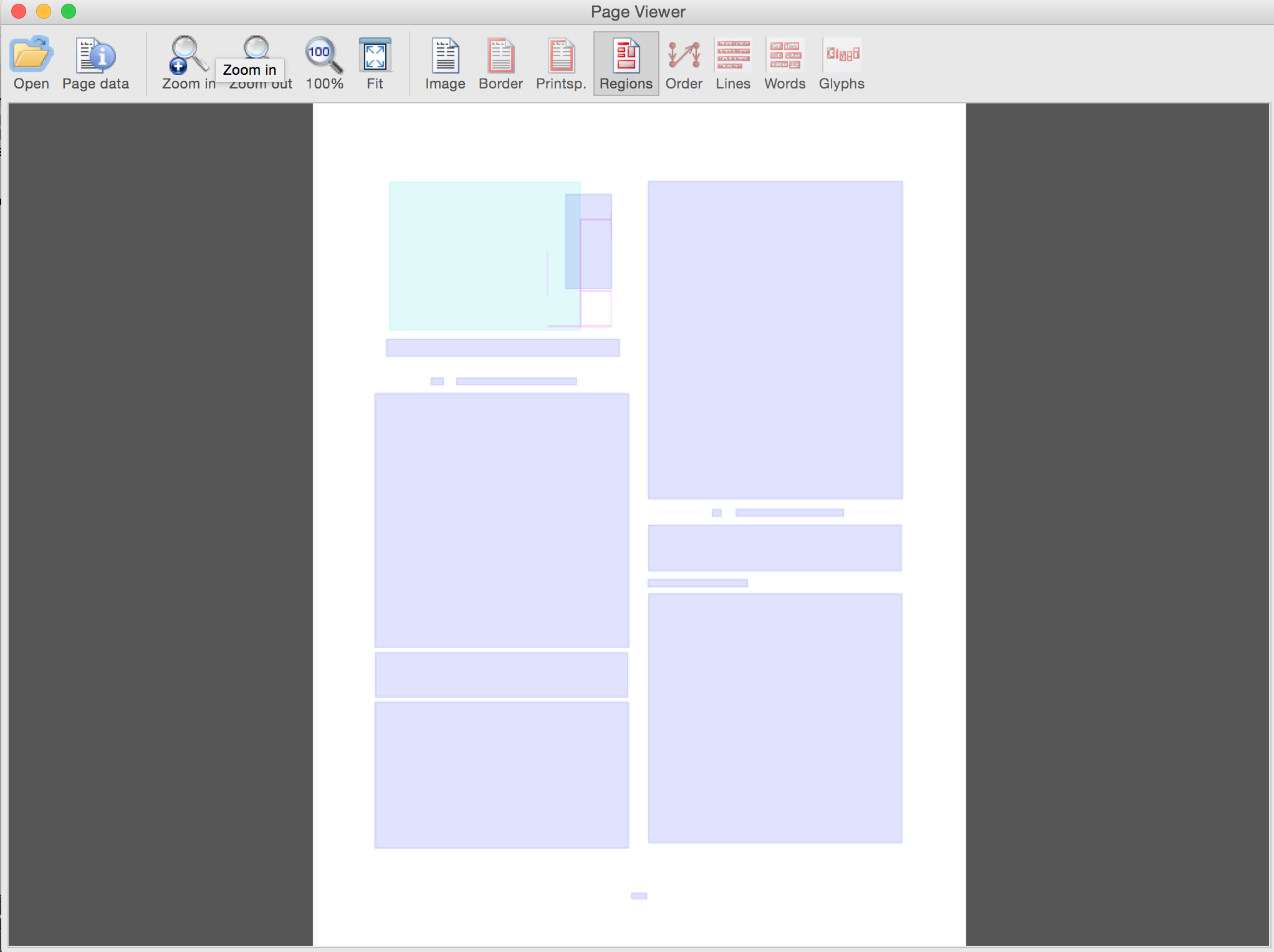
Annexe
vous pouvez lancer tesseract vous-même et utiliser un autre outil pour convertir sa sortie au format de PAGE. J'ai été incapable de faire marcher ça, mais je suis sûr que ça ira!
# Note that the pvtool does take as input HOCR xml but it ignores the region type
brew install tesseract --devel # installs v 3.03 at time of writing
tesseract ~/Downloads/paper-3.tif ~/Downloads/paper-3 hocr
mv paper-3.hocr paper-3.xml # The page viewer will only open XML files
java -XstartOnFirstThread -jar JPageViewer.jar "$dl/Downloads/paper-3.xml"
a ce point vous devez utiliser le PAGE Convertisseur Java Outil pour convertir le xml HOCR en une page xml. Il faut aller un peu quelque chose comme ceci:
pctool="/Users/Me/Project/tools/JPageConverter 1.0"
java -jar "$pctool/PageConverter.jar" -source-xml paper-3.xml -target-xml paper-3-hocrconvert.xml -convert-to LATEST
malheureusement, j'ai continué à recevoir des pointeurs nuls.
Could not convert to target XML schema format.
java.lang.NullPointerException
at org.primaresearch.dla.page.converter.PageConverter.run(PageConverter.java:126)
at org.primaresearch.dla.page.converter.PageConverter.main(PageConverter.java:65)
Could not save target PAGE XML file: paper-3-hocrconvert.xml
java.lang.NullPointerException
at org.primaresearch.dla.page.io.xml.XmlInputOutput.writePage(XmlInputOutput.java:144)
at org.primaresearch.dla.page.converter.PageConverter.run(PageConverter.java:135)
at org.primaresearch.dla.page.converter.PageConverter.main(PageConverter.java:65)
vous pouvez utiliser son API pour obtenir les boîtes limites à différents niveaux (caractère/mot/ligne/para) -- voir exemple D'API. Vous devez dessiner les étiquettes vous-même.
Raccourci
il est également possible d'ouvrir des fichiers HOCR directement avec L'outil PageViewer. L'extension du fichier doit être .xml, cependant.
avec Tesseract 4.0.0, une commande comme tesseract source/dir/myimage.tiff target/directory/basefilename hocr va créer un basefilename.hocr fichier avec des blocs-, des paragraphes-, des lignes-, et des mots-niveau délimitant des boîtes pour le texte OCR'ed. Même la commande sans le hocr config crée un fichier texte avec des lignes entre les blocs de texte, mais le format hocr est plus explicite.
Plus d'options de configuration ici: https://github.com/tesseract-ocr/tesseract/tree/master/tessdata/configs
la façon la plus simple d'avoir un fichier HOCR avec le niveau de caractère individuel est d'utiliser la fourchette de nickjwhite de Tesseract 3.05:https://github.com/nickjwhite/tesseract/tree/hocrcharboxes
compiler et télécharger des fichiers tessdata en suivant le wiki de Tesseract. Une fois l'installation vérifiée, utilisez :
tesseract {image file} -c tessedit_create_hocr=1 -c hocr_char_boxes=1 {output name}
et tadam !