Comment puis-je obtenir des indices de n valeurs maximales dans un tableau de NumPy?
NumPy propose un moyen pour obtenir l'index de la valeur maximale d'un tableau via np.argmax .
je voudrais une chose semblable, mais en retournant les index des valeurs n maximum.
Par exemple, si j'ai un tableau, [1, 3, 2, 4, 5] , function(array, n=3) retourne [4, 3, 1] .
15 réponses
le plus simple que j'ai pu trouver est:
In [1]: import numpy as np
In [2]: arr = np.array([1, 3, 2, 4, 5])
In [3]: arr.argsort()[-3:][::-1]
Out[3]: array([4, 3, 1])
Cela implique une sorte de tableau. Je me demande si numpy fournit un moyen intégré de faire un tri partiel; jusqu'à présent je n'ai pas été en mesure d'en trouver un.
si cette solution s'avère trop lente (en particulier pour les petits n ), il peut être intéressant d'examiner le codage quelque chose vers le haut dans Cython .
les nouvelles versions de NumPy (1.8 et plus) ont une fonction appelée argpartition pour cela. Pour obtenir les indices des quatre plus grands éléments, faites 151980920"
>>> a = np.array([9, 4, 4, 3, 3, 9, 0, 4, 6, 0])
>>> a
array([9, 4, 4, 3, 3, 9, 0, 4, 6, 0])
>>> ind = np.argpartition(a, -4)[-4:]
>>> ind
array([1, 5, 8, 0])
>>> a[ind]
array([4, 9, 6, 9])
contrairement à argsort , cette fonction s'exécute en temps linéaire dans le pire des cas, mais les indices retournés ne sont pas triés, comme peut être vu du résultat de l'évaluation a[ind] . Si vous avez besoin de cela aussi, triez-les après:
>>> ind[np.argsort(a[ind])]
array([1, 8, 5, 0])
Pour obtenir le haut- k les éléments dans l'ordre de tri dans cette voie prend O( n + k journal k ).
plus simple encore:
idx = (-arr).argsort()[:n]
où n est le nombre de valeurs maximales.
Utiliser:
>>> import heapq
>>> import numpy
>>> a = numpy.array([1, 3, 2, 4, 5])
>>> heapq.nlargest(3, range(len(a)), a.take)
[4, 3, 1]
pour les listes Python régulières:
>>> a = [1, 3, 2, 4, 5]
>>> heapq.nlargest(3, range(len(a)), a.__getitem__)
[4, 3, 1]
si vous utilisez Python 2, Utilisez xrange au lieu de range .
si vous travaillez avec un tableau multidimensionnel alors vous aurez besoin d'aplatir et de démêler les indices:
def largest_indices(ary, n):
"""Returns the n largest indices from a numpy array."""
flat = ary.flatten()
indices = np.argpartition(flat, -n)[-n:]
indices = indices[np.argsort(-flat[indices])]
return np.unravel_index(indices, ary.shape)
par exemple:
>>> xs = np.sin(np.arange(9)).reshape((3, 3))
>>> xs
array([[ 0. , 0.84147098, 0.90929743],
[ 0.14112001, -0.7568025 , -0.95892427],
[-0.2794155 , 0.6569866 , 0.98935825]])
>>> largest_indices(xs, 3)
(array([2, 0, 0]), array([2, 2, 1]))
>>> xs[largest_indices(xs, 3)]
array([ 0.98935825, 0.90929743, 0.84147098])
si vous ne vous souciez pas de la commande des K-ème plus grands éléments que vous pouvez utiliser argpartition , qui devrait fonctionner mieux qu'un tri complet à travers argsort .
K = 4 # We want the indices of the four largest values
a = np.array([0, 8, 0, 4, 5, 8, 8, 0, 4, 2])
np.argpartition(a,-K)[-K:]
array([4, 1, 5, 6])
crédits passer à cette question .
j'ai fait quelques tests et il ressemble à argpartition outperforms argsort que la taille du tableau et la valeur de K augmentent.
pour les tableaux multidimensionnels, vous pouvez utiliser le mot-clé axis pour appliquer le partitionnement le long de l'axe prévu.
# For a 2D array
indices = np.argpartition(arr, -N, axis=1)[:, -N:]
et pour saisir les articles:
x = arr.shape[0]
arr[np.repeat(np.arange(x), N), indices.ravel()].reshape(x, N)
mais notez que ceci ne retournera pas un résultat trié. Dans ce cas, vous pouvez utiliser np.argsort() le long de l'axe prévu:
indices = np.argsort(arr, axis=1)[:, -N:]
# Result
x = arr.shape[0]
arr[np.repeat(np.arange(x), N), indices.ravel()].reshape(x, N)
voici un exemple:
In [42]: a = np.random.randint(0, 20, (10, 10))
In [44]: a
Out[44]:
array([[ 7, 11, 12, 0, 2, 3, 4, 10, 6, 10],
[16, 16, 4, 3, 18, 5, 10, 4, 14, 9],
[ 2, 9, 15, 12, 18, 3, 13, 11, 5, 10],
[14, 0, 9, 11, 1, 4, 9, 19, 18, 12],
[ 0, 10, 5, 15, 9, 18, 5, 2, 16, 19],
[14, 19, 3, 11, 13, 11, 13, 11, 1, 14],
[ 7, 15, 18, 6, 5, 13, 1, 7, 9, 19],
[11, 17, 11, 16, 14, 3, 16, 1, 12, 19],
[ 2, 4, 14, 8, 6, 9, 14, 9, 1, 5],
[ 1, 10, 15, 0, 1, 9, 18, 2, 2, 12]])
In [45]: np.argpartition(a, np.argmin(a, axis=0))[:, 1:] # 1 is because the first item is the minimum one.
Out[45]:
array([[4, 5, 6, 8, 0, 7, 9, 1, 2],
[2, 7, 5, 9, 6, 8, 1, 0, 4],
[5, 8, 1, 9, 7, 3, 6, 2, 4],
[4, 5, 2, 6, 3, 9, 0, 8, 7],
[7, 2, 6, 4, 1, 3, 8, 5, 9],
[2, 3, 5, 7, 6, 4, 0, 9, 1],
[4, 3, 0, 7, 8, 5, 1, 2, 9],
[5, 2, 0, 8, 4, 6, 3, 1, 9],
[0, 1, 9, 4, 3, 7, 5, 2, 6],
[0, 4, 7, 8, 5, 1, 9, 2, 6]])
In [46]: np.argpartition(a, np.argmin(a, axis=0))[:, -3:]
Out[46]:
array([[9, 1, 2],
[1, 0, 4],
[6, 2, 4],
[0, 8, 7],
[8, 5, 9],
[0, 9, 1],
[1, 2, 9],
[3, 1, 9],
[5, 2, 6],
[9, 2, 6]])
In [89]: a[np.repeat(np.arange(x), 3), ind.ravel()].reshape(x, 3)
Out[89]:
array([[10, 11, 12],
[16, 16, 18],
[13, 15, 18],
[14, 18, 19],
[16, 18, 19],
[14, 14, 19],
[15, 18, 19],
[16, 17, 19],
[ 9, 14, 14],
[12, 15, 18]])
Ce sera plus rapide qu'un tri en fonction de la taille de votre tableau d'origine et la taille de votre sélection:
>>> A = np.random.randint(0,10,10)
>>> A
array([5, 1, 5, 5, 2, 3, 2, 4, 1, 0])
>>> B = np.zeros(3, int)
>>> for i in xrange(3):
... idx = np.argmax(A)
... B[i]=idx; A[idx]=0 #something smaller than A.min()
...
>>> B
array([0, 2, 3])
il s'agit, bien sûr, d'altérer votre réseau d'origine. Que vous pouvez corriger (si nécessaire) en faisant une copie ou en remplaçant les valeurs originales. ...celui qui est le moins cher pour votre cas d'utilisation.
bottleneck a une fonction de tri partiel, si la dépense de tri de l'ensemble du tableau juste pour obtenir les N plus grandes valeurs est trop grande.
Je ne sais rien de ce module; Je viens de googler numpy partial sort .
Utiliser:
from operator import itemgetter
from heapq import nlargest
result = nlargest(N, enumerate(your_list), itemgetter(1))
maintenant la liste result contiendrait N tuples ( index , value ) où value est maximisé.
utiliser:
def max_indices(arr, k):
'''
Returns the indices of the k first largest elements of arr
(in descending order in values)
'''
assert k <= arr.size, 'k should be smaller or equal to the array size'
arr_ = arr.astype(float) # make a copy of arr
max_idxs = []
for _ in range(k):
max_element = np.max(arr_)
if np.isinf(max_element):
break
else:
idx = np.where(arr_ == max_element)
max_idxs.append(idx)
arr_[idx] = -np.inf
return max_idxs
il fonctionne aussi avec des matrices 2D. Par exemple,
In [0]: A = np.array([[ 0.51845014, 0.72528114],
[ 0.88421561, 0.18798661],
[ 0.89832036, 0.19448609],
[ 0.89832036, 0.19448609]])
In [1]: max_indices(A, 8)
Out[1]:
[(array([2, 3], dtype=int64), array([0, 0], dtype=int64)),
(array([1], dtype=int64), array([0], dtype=int64)),
(array([0], dtype=int64), array([1], dtype=int64)),
(array([0], dtype=int64), array([0], dtype=int64)),
(array([2, 3], dtype=int64), array([1, 1], dtype=int64)),
(array([1], dtype=int64), array([1], dtype=int64))]
In [2]: A[max_indices(A, 8)[0]][0]
Out[2]: array([ 0.89832036])
méthode np.argpartition renvoie seulement les indices k les plus grands, effectue un tri local, et est plus rapide que np.argsort (effectuer un tri complet) quand le tableau est assez grand. Mais les indices retournés sont pas dans l'ordre ascendant/descendant . Disons avec un exemple:

nous pouvons voir que si vous voulez un ordre strict Ascendant Top K indices, np.argpartition ne sera pas rends ce que tu veux.
à part faire un tri manuellement après np.argpartition, ma solution est D'utiliser PyTorch, torch.topk , un outil pour la construction de réseaux neuronaux, fournissant des API de type NumPy avec un support CPU et GPU. Il est aussi rapide que NumPy avec MKL, et offre un coup de pouce GPU si vous avez besoin de grands calculs de matrice/vecteur.
code Strict des indices K ascendants/descendants sera:
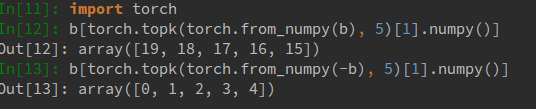
Note que torch.topk accepte une torche tenseur, et renvoie à la fois haut les valeurs de k et de haut k indices de type torch.Tensor . Similaire avec np, torche.topk accepte également un argument axis de sorte que vous pouvez gérer les tableaux/tenseurs multidimensionnels.
j'ai trouvé plus intuitif d'utiliser np.unique .
L'idée est que l'unique méthode retourne les indices des valeurs d'entrée. Ensuite, à partir de la valeur unique max et des indices, La position des valeurs originales peut être recréée.
multi_max = [1,1,2,2,4,0,0,4]
uniques, idx = np.unique(multi_max, return_inverse=True)
print np.squeeze(np.argwhere(idx == np.argmax(uniques)))
>> [4 7]
je pense que le moyen le plus efficace dans le temps est itérate manuellement à travers le tableau et garder un min-heap K-size, comme d'autres personnes l'ont mentionné.
et je trouve aussi une approche de force brute:
top_k_index_list = [ ]
for i in range(k):
top_k_index_list.append(np.argmax(my_array))
my_array[top_k_index_list[-1]] = -float('inf')
définit le plus grand élément à une grande valeur négative après avoir utilisé argmax pour obtenir son indice. Et puis le prochain appel d'argmax retournera le deuxième plus grand élément. Et vous pouvez enregistrer la valeur originale de ces éléments et les récupérer si vous le souhaitez.
ce qui suit est un moyen très facile de voir les éléments maximums et ses positions. Ici axis est le domaine; axis = 0 signifie le nombre maximum par colonne et axis = 1 signifie le nombre Max par ligne pour le cas 2D. Et pour les dimensions supérieures, cela dépend de vous.
M = np.random.random((3, 4))
print(M)
print(M.max(axis=1), M.argmax(axis=1))