Comment puis-je trouver les doublons dans une liste, et de créer une autre liste?
24 réponses
pour supprimer les doublons utilisez set(a) , pour imprimer les doublons-quelque chose comme
a = [1,2,3,2,1,5,6,5,5,5]
import collections
print [item for item, count in collections.Counter(a).items() if count > 1]
## [1, 2, 5]
notez que Counter n'est pas particulièrement efficace ( timings ) et probablement un surmenage ici, set sera plus performant. Ce code calcule une liste d'éléments uniques dans l'ordre source:
seen = set()
uniq = []
for x in a:
if x not in seen:
uniq.append(x)
seen.add(x)
ou, de façon plus concise:
seen = set()
uniq = [x for x in a if x not in seen and not seen.add(x)]
Je ne recommande pas ce dernier style, parce qu'il n'est pas évident ce que not seen.add(x) fait (la méthode add() retourne toujours None , d'où la nécessité de not ).
Pour calculer la liste des éléments dupliqués sans bibliothèques,
seen = {}
dupes = []
for x in a:
if x not in seen:
seen[x] = 1
else:
if seen[x] == 1:
dupes.append(x)
seen[x] += 1
si les éléments de liste ne sont pas hachables, vous ne pouvez pas utiliser set/dicts et devez recourir à une solution de temps quadratique (comparez Chaque que chacun), par exemple:
a = [ [1], [2], [3], [1], [5], [3] ]
no_dupes = [x for n, x in enumerate(a) if x not in a[:n]]
print no_dupes # [[1], [2], [3], [5]]
dupes = [x for n, x in enumerate(a) if x in a[:n]]
print dupes # [[1], [3]]
>>> l = [1,2,3,4,4,5,5,6,1]
>>> set([x for x in l if l.count(x) > 1])
set([1, 4, 5])
vous n'avez pas besoin du compte, juste si oui ou non l'objet a été vu avant. Adapté que répondre à à ce problème:
def list_duplicates(seq):
seen = set()
seen_add = seen.add
# adds all elements it doesn't know yet to seen and all other to seen_twice
seen_twice = set( x for x in seq if x in seen or seen_add(x) )
# turn the set into a list (as requested)
return list( seen_twice )
a = [1,2,3,2,1,5,6,5,5,5]
list_duplicates(a) # yields [1, 2, 5]
Juste au cas où la vitesse de questions, voici les horaires:
# file: test.py
import collections
def thg435(l):
return [x for x, y in collections.Counter(l).items() if y > 1]
def moooeeeep(l):
seen = set()
seen_add = seen.add
# adds all elements it doesn't know yet to seen and all other to seen_twice
seen_twice = set( x for x in l if x in seen or seen_add(x) )
# turn the set into a list (as requested)
return list( seen_twice )
def RiteshKumar(l):
return list(set([x for x in l if l.count(x) > 1]))
def JohnLaRooy(L):
seen = set()
seen2 = set()
seen_add = seen.add
seen2_add = seen2.add
for item in L:
if item in seen:
seen2_add(item)
else:
seen_add(item)
return list(seen2)
l = [1,2,3,2,1,5,6,5,5,5]*100
Voici les résultats: (well done @JohnLaRooy!)
$ python -mtimeit -s 'import test' 'test.JohnLaRooy(test.l)'
10000 loops, best of 3: 74.6 usec per loop
$ python -mtimeit -s 'import test' 'test.moooeeeep(test.l)'
10000 loops, best of 3: 91.3 usec per loop
$ python -mtimeit -s 'import test' 'test.thg435(test.l)'
1000 loops, best of 3: 266 usec per loop
$ python -mtimeit -s 'import test' 'test.RiteshKumar(test.l)'
100 loops, best of 3: 8.35 msec per loop
il est intéressant de noter que, outre les horaires eux-mêmes, le classement change légèrement lorsque l'on utilise pypy. Plus intéressant encore, l'approche contre-basée bénéficie énormément des optimisations de pypy, alors que l'approche de mise en cache de méthode que j'ai suggéré semble n'avoir pratiquement aucun effet.
$ pypy -mtimeit -s 'import test' 'test.JohnLaRooy(test.l)'
100000 loops, best of 3: 17.8 usec per loop
$ pypy -mtimeit -s 'import test' 'test.thg435(test.l)'
10000 loops, best of 3: 23 usec per loop
$ pypy -mtimeit -s 'import test' 'test.moooeeeep(test.l)'
10000 loops, best of 3: 39.3 usec per loop
cet effet est apparemment lié à la "duplicité" des données d'entrée. J'ai mis l = [random.randrange(1000000) for i in xrange(10000)] et obtenu ces résultats:
$ pypy -mtimeit -s 'import test' 'test.moooeeeep(test.l)'
1000 loops, best of 3: 495 usec per loop
$ pypy -mtimeit -s 'import test' 'test.JohnLaRooy(test.l)'
1000 loops, best of 3: 499 usec per loop
$ pypy -mtimeit -s 'import test' 'test.thg435(test.l)'
1000 loops, best of 3: 1.68 msec per loop
j'ai rencontré cette question en regardant quelque chose de relié - et je me demande pourquoi personne n'a offert une solution basée sur un générateur? Résoudre ce problème serait:
>>> print list(getDupes_9([1,2,3,2,1,5,6,5,5,5]))
[1, 2, 5]
je me souciais de l'évolutivité, donc testé plusieurs approches, y compris des éléments naïfs qui fonctionnent bien sur les petites listes, mais échelle horriblement que les listes deviennent plus grandes (note - aurait été mieux d'utiliser timeit, mais ceci est illustratif).
j'ai inclus @mooeeeep pour la comparaison (elle est remarquablement rapide: la plus rapide si la liste d'entrée est complètement aléatoire) et une approche itertools qui est encore plus rapide pour la plupart des listes triées... Inclut maintenant l'approche pandas de @firelynx -- lente, mais pas horriblement si, et simple. Note-l'approche de tri/tee/zip est toujours la plus rapide sur ma machine pour les grandes listes la plupart du temps commandées, mooeeeep est la plus rapide pour les listes mélangées, mais votre kilométrage peut varier.
avantages
- très simple à tester pour "n'importe quel" duplicata en utilisant le même code
suppositions
- les doublons ne doivent être déclarés qu'une seule fois
- de la commande Dupliquer n'a pas besoin d'être préservé
- en Double pourrait être n'importe où dans la liste
la solution la plus rapide, 1m d'entrées:
def getDupes(c):
'''sort/tee/izip'''
a, b = itertools.tee(sorted(c))
next(b, None)
r = None
for k, g in itertools.izip(a, b):
if k != g: continue
if k != r:
yield k
r = k
approches testées
import itertools
import time
import random
def getDupes_1(c):
'''naive'''
for i in xrange(0, len(c)):
if c[i] in c[:i]:
yield c[i]
def getDupes_2(c):
'''set len change'''
s = set()
for i in c:
l = len(s)
s.add(i)
if len(s) == l:
yield i
def getDupes_3(c):
'''in dict'''
d = {}
for i in c:
if i in d:
if d[i]:
yield i
d[i] = False
else:
d[i] = True
def getDupes_4(c):
'''in set'''
s,r = set(),set()
for i in c:
if i not in s:
s.add(i)
elif i not in r:
r.add(i)
yield i
def getDupes_5(c):
'''sort/adjacent'''
c = sorted(c)
r = None
for i in xrange(1, len(c)):
if c[i] == c[i - 1]:
if c[i] != r:
yield c[i]
r = c[i]
def getDupes_6(c):
'''sort/groupby'''
def multiple(x):
try:
x.next()
x.next()
return True
except:
return False
for k, g in itertools.ifilter(lambda x: multiple(x[1]), itertools.groupby(sorted(c))):
yield k
def getDupes_7(c):
'''sort/zip'''
c = sorted(c)
r = None
for k, g in zip(c[:-1],c[1:]):
if k == g:
if k != r:
yield k
r = k
def getDupes_8(c):
'''sort/izip'''
c = sorted(c)
r = None
for k, g in itertools.izip(c[:-1],c[1:]):
if k == g:
if k != r:
yield k
r = k
def getDupes_9(c):
'''sort/tee/izip'''
a, b = itertools.tee(sorted(c))
next(b, None)
r = None
for k, g in itertools.izip(a, b):
if k != g: continue
if k != r:
yield k
r = k
def getDupes_a(l):
'''moooeeeep'''
seen = set()
seen_add = seen.add
# adds all elements it doesn't know yet to seen and all other to seen_twice
for x in l:
if x in seen or seen_add(x):
yield x
def getDupes_b(x):
'''iter*/sorted'''
x = sorted(x)
def _matches():
for k,g in itertools.izip(x[:-1],x[1:]):
if k == g:
yield k
for k, n in itertools.groupby(_matches()):
yield k
def getDupes_c(a):
'''pandas'''
import pandas as pd
vc = pd.Series(a).value_counts()
i = vc[vc > 1].index
for _ in i:
yield _
def hasDupes(fn,c):
try:
if fn(c).next(): return True # Found a dupe
except StopIteration:
pass
return False
def getDupes(fn,c):
return list(fn(c))
STABLE = True
if STABLE:
print 'Finding FIRST then ALL duplicates, single dupe of "nth" placed element in 1m element array'
else:
print 'Finding FIRST then ALL duplicates, single dupe of "n" included in randomised 1m element array'
for location in (50,250000,500000,750000,999999):
for test in (getDupes_2, getDupes_3, getDupes_4, getDupes_5, getDupes_6,
getDupes_8, getDupes_9, getDupes_a, getDupes_b, getDupes_c):
print 'Test %-15s:%10d - '%(test.__doc__ or test.__name__,location),
deltas = []
for FIRST in (True,False):
for i in xrange(0, 5):
c = range(0,1000000)
if STABLE:
c[0] = location
else:
c.append(location)
random.shuffle(c)
start = time.time()
if FIRST:
print '.' if location == test(c).next() else '!',
else:
print '.' if [location] == list(test(c)) else '!',
deltas.append(time.time()-start)
print ' -- %0.3f '%(sum(deltas)/len(deltas)),
print
print
Les résultats pour " tous les dupes de test étaient cohérentes, trouver le "premier" double "toutes les" doublons dans ce tableau:
Finding FIRST then ALL duplicates, single dupe of "nth" placed element in 1m element array
Test set len change : 500000 - . . . . . -- 0.264 . . . . . -- 0.402
Test in dict : 500000 - . . . . . -- 0.163 . . . . . -- 0.250
Test in set : 500000 - . . . . . -- 0.163 . . . . . -- 0.249
Test sort/adjacent : 500000 - . . . . . -- 0.159 . . . . . -- 0.229
Test sort/groupby : 500000 - . . . . . -- 0.860 . . . . . -- 1.286
Test sort/izip : 500000 - . . . . . -- 0.165 . . . . . -- 0.229
Test sort/tee/izip : 500000 - . . . . . -- 0.145 . . . . . -- 0.206 *
Test moooeeeep : 500000 - . . . . . -- 0.149 . . . . . -- 0.232
Test iter*/sorted : 500000 - . . . . . -- 0.160 . . . . . -- 0.221
Test pandas : 500000 - . . . . . -- 0.493 . . . . . -- 0.499
quand les listes sont mélangées en premier, Le prix de la sorte devient apparent - l'efficacité baisse sensiblement et l'approche @mooeeeep domine, avec les approches set & dict étant artistes interprètes ou exécutants similaires mais à crédit-bailleur:
Finding FIRST then ALL duplicates, single dupe of "n" included in randomised 1m element array
Test set len change : 500000 - . . . . . -- 0.321 . . . . . -- 0.473
Test in dict : 500000 - . . . . . -- 0.285 . . . . . -- 0.360
Test in set : 500000 - . . . . . -- 0.309 . . . . . -- 0.365
Test sort/adjacent : 500000 - . . . . . -- 0.756 . . . . . -- 0.823
Test sort/groupby : 500000 - . . . . . -- 1.459 . . . . . -- 1.896
Test sort/izip : 500000 - . . . . . -- 0.786 . . . . . -- 0.845
Test sort/tee/izip : 500000 - . . . . . -- 0.743 . . . . . -- 0.804
Test moooeeeep : 500000 - . . . . . -- 0.234 . . . . . -- 0.311 *
Test iter*/sorted : 500000 - . . . . . -- 0.776 . . . . . -- 0.840
Test pandas : 500000 - . . . . . -- 0.539 . . . . . -- 0.540
des collections.Counter est nouveau en python 2.7:
Python 2.5.4 (r254:67916, May 31 2010, 15:03:39)
[GCC 4.1.2 20080704 (Red Hat 4.1.2-46)] on linux2
a = [1,2,3,2,1,5,6,5,5,5]
import collections
print [x for x, y in collections.Counter(a).items() if y > 1]
Type "help", "copyright", "credits" or "license" for more information.
File "", line 1, in
AttributeError: 'module' object has no attribute 'Counter'
>>>
dans une version antérieure, vous pouvez utiliser un dict conventionnel à la place:
a = [1,2,3,2,1,5,6,5,5,5]
d = {}
for elem in a:
if elem in d:
d[elem] += 1
else:
d[elem] = 1
print [x for x, y in d.items() if y > 1]
vous pouvez utiliser iteration_utilities.duplicates :
>>> from iteration_utilities import duplicates
>>> list(duplicates([1,1,2,1,2,3,4,2]))
[1, 1, 2, 2]
ou si vous voulez seulement un de chaque duplicata cela peut être combiné avec iteration_utilities.unique_everseen :
>>> from iteration_utilities import unique_everseen
>>> list(unique_everseen(duplicates([1,1,2,1,2,3,4,2])))
[1, 2]
il peut également traiter des éléments inhashables (toutefois au prix de la performance):
>>> list(duplicates([[1], [2], [1], [3], [1]]))
[[1], [1]]
>>> list(unique_everseen(duplicates([[1], [2], [1], [3], [1]])))
[[1]]
c'est quelque chose que seules quelques-unes des autres approches ici peuvent gérer.
Benchmarks
j'ai fait un rapide test contenant la plupart (mais pas tous) les approches mentionnées ici.
le premier indice de référence ne comprenait qu'une petite gamme de longueurs de listes parce que certaines approches ont un comportement O(n**2) .
dans les graphiques, l'axe des ordonnées représente le temps, donc une valeur plus basse signifie mieux. Il est également tracé log-log de sorte que la large gamme de valeurs peut être visualisé mieux:
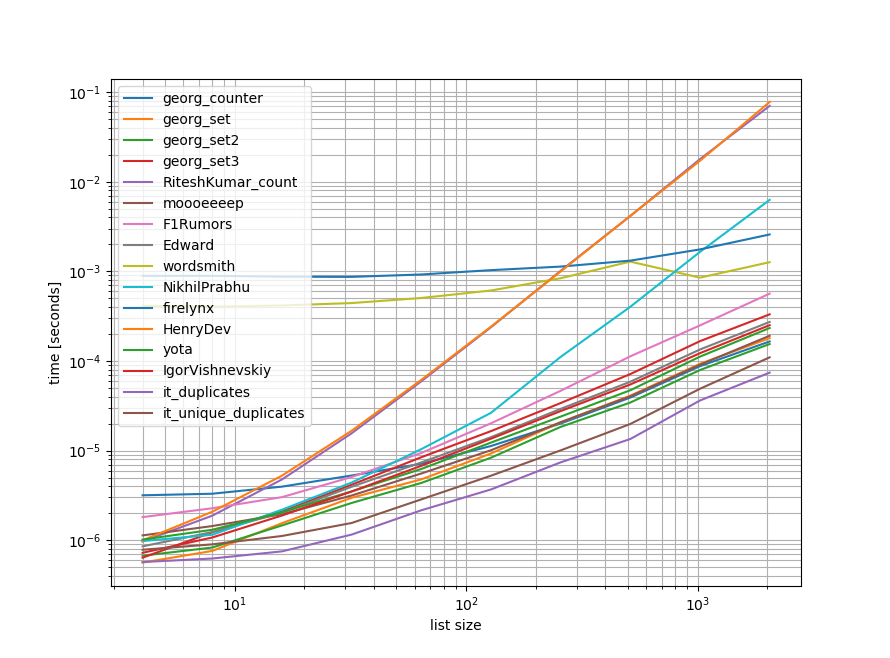
suppression des approches O(n**2) j'ai fait un autre benchmark jusqu'à un demi-million d'éléments dans une liste:
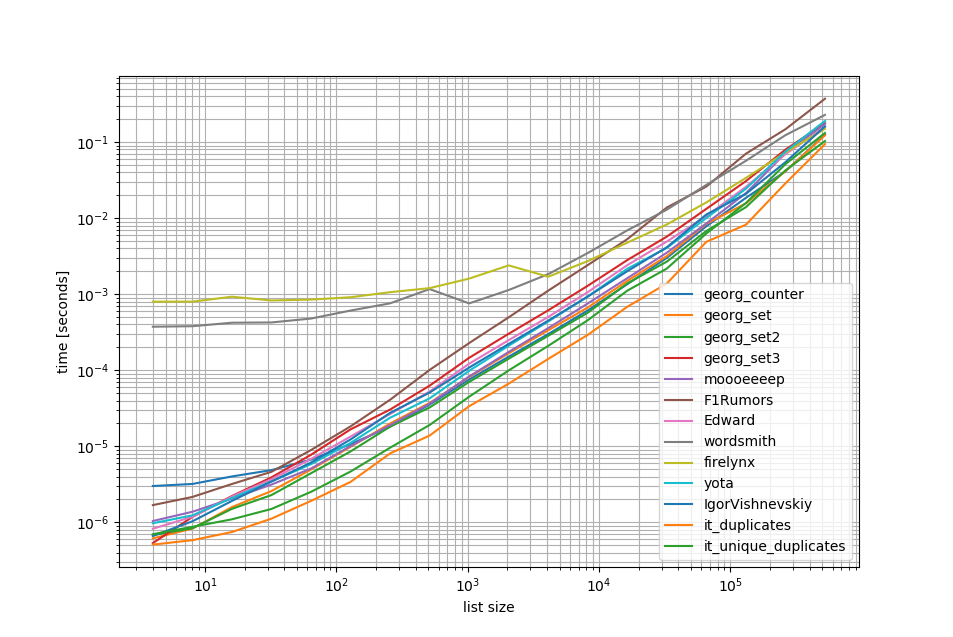
comme vous pouvez le voir, l'approche iteration_utilities.duplicates est plus rapide que toutes les autres approches et même l'enchaînement unique_everseen(duplicates(...)) était plus rapide ou tout aussi rapide que les autres approches.
une autre chose intéressante à noter ici est que les approches pandas sont très lentes pour les petites listes mais peuvent facilement rivaliser pour des listes plus longues.
cependant, comme ces benchmarks montrent que la plupart des approches fonctionnent à peu près de la même façon, donc peu importe laquelle est utilisée (à l'exception des 3 qui avaient O(n**2) runtime).
from iteration_utilities import duplicates, unique_everseen
from collections import Counter
import pandas as pd
import itertools
def georg_counter(it):
return [item for item, count in Counter(it).items() if count > 1]
def georg_set(it):
seen = set()
uniq = []
for x in it:
if x not in seen:
uniq.append(x)
seen.add(x)
def georg_set2(it):
seen = set()
return [x for x in it if x not in seen and not seen.add(x)]
def georg_set3(it):
seen = {}
dupes = []
for x in it:
if x not in seen:
seen[x] = 1
else:
if seen[x] == 1:
dupes.append(x)
seen[x] += 1
def RiteshKumar_count(l):
return set([x for x in l if l.count(x) > 1])
def moooeeeep(seq):
seen = set()
seen_add = seen.add
# adds all elements it doesn't know yet to seen and all other to seen_twice
seen_twice = set( x for x in seq if x in seen or seen_add(x) )
# turn the set into a list (as requested)
return list( seen_twice )
def F1Rumors_implementation(c):
a, b = itertools.tee(sorted(c))
next(b, None)
r = None
for k, g in zip(a, b):
if k != g: continue
if k != r:
yield k
r = k
def F1Rumors(c):
return list(F1Rumors_implementation(c))
def Edward(a):
d = {}
for elem in a:
if elem in d:
d[elem] += 1
else:
d[elem] = 1
return [x for x, y in d.items() if y > 1]
def wordsmith(a):
return pd.Series(a)[pd.Series(a).duplicated()].values
def NikhilPrabhu(li):
li = li.copy()
for x in set(li):
li.remove(x)
return list(set(li))
def firelynx(a):
vc = pd.Series(a).value_counts()
return vc[vc > 1].index.tolist()
def HenryDev(myList):
newList = set()
for i in myList:
if myList.count(i) >= 2:
newList.add(i)
return list(newList)
def yota(number_lst):
seen_set = set()
duplicate_set = set(x for x in number_lst if x in seen_set or seen_set.add(x))
return seen_set - duplicate_set
def IgorVishnevskiy(l):
s=set(l)
d=[]
for x in l:
if x in s:
s.remove(x)
else:
d.append(x)
return d
def it_duplicates(l):
return list(duplicates(l))
def it_unique_duplicates(l):
return list(unique_everseen(duplicates(l)))
Test 1
from simple_benchmark import benchmark
import random
funcs = [
georg_counter, georg_set, georg_set2, georg_set3, RiteshKumar_count, moooeeeep,
F1Rumors, Edward, wordsmith, NikhilPrabhu, firelynx,
HenryDev, yota, IgorVishnevskiy, it_duplicates, it_unique_duplicates
]
args = {2**i: [random.randint(0, 2**(i-1)) for _ in range(2**i)] for i in range(2, 12)}
b = benchmark(funcs, args, 'list size')
b.plot()
Test 2
funcs = [
georg_counter, georg_set, georg_set2, georg_set3, moooeeeep,
F1Rumors, Edward, wordsmith, firelynx,
yota, IgorVishnevskiy, it_duplicates, it_unique_duplicates
]
args = {2**i: [random.randint(0, 2**(i-1)) for _ in range(2**i)] for i in range(2, 20)}
b = benchmark(funcs, args, 'list size')
b.plot()
Avertissement
1 C'est à partir d'une bibliothèque tierce j'ai écrit: iteration_utilities .
utilisant pandas:
>>> import pandas as pd
>>> a = [1, 2, 1, 3, 3, 3, 0]
>>> pd.Series(a)[pd.Series(a).duplicated()].values
array([1, 3, 3])
Voici un clair et concis de la solution de
for x in set(li):
li.remove(x)
li = list(set(li))
je voudrais faire cela avec les pandas, car j'utilise des pandas beaucoup
import pandas as pd
a = [1,2,3,3,3,4,5,6,6,7]
vc = pd.Series(a).value_counts()
vc[vc > 1].index.tolist()
donne
[3,6]
N'est probablement pas très efficace, mais il est certain que c'est moins de code que beaucoup d'autres réponses, donc j'ai pensé que je contribuerais
Un peu en retard, mais peut-être utile pour certains. Pour une grande liste, j'ai trouvé que ça marchait pour moi.
l=[1,2,3,5,4,1,3,1]
s=set(l)
d=[]
for x in l:
if x in s:
s.remove(x)
else:
d.append(x)
d
[1,3,1]
Montre et tous les doublons et préserve l'ordre.
le troisième exemple de la réponse acceptée donne une réponse erronée et ne tente pas de donner des doublons. Voici la version correcte:
number_lst = [1, 1, 2, 3, 5, ...]
seen_set = set()
duplicate_set = set(x for x in number_lst if x in seen_set or seen_set.add(x))
unique_set = seen_set - duplicate_set
pourquoi ne pas simplement faire une boucle à travers chaque élément de la liste en vérifiant le nombre d'occurrences, puis en les ajoutant à un ensemble qui va ensuite imprimer les doublons. Espérons que cela aide quelqu'un là-bas.
myList = [2 ,4 , 6, 8, 4, 6, 12];
newList = set()
for i in myList:
if myList.count(i) >= 2:
newList.add(i)
print(list(newList))
## [4 , 6]
la façon très simple et rapide de trouver des dupes avec une itération en Python est:
testList = ['red', 'blue', 'red', 'green', 'blue', 'blue']
testListDict = {}
for item in testList:
try:
testListDict[item] += 1
except:
testListDict[item] = 1
print testListDict
sortie sera la suivante:
>>> print testListDict
{'blue': 3, 'green': 1, 'red': 2}
ceci et plus dans mon blog http://www.howtoprogramwithpython.com
nous pouvons utiliser itertools.groupby pour trouver tous les produits qui ont des dups:
from itertools import groupby
myList = [2, 4, 6, 8, 4, 6, 12]
# when the list is sorted, groupby groups by consecutive elements which are similar
for x, y in groupby(sorted(myList)):
# list(y) returns all the occurences of item x
if len(list(y)) > 1:
print x
la sortie sera:
4
6
list2 = [1, 2, 3, 4, 1, 2, 3]
lset = set()
[(lset.add(item), list2.append(item))
for item in list2 if item not in lset]
print list(lset)
Une solution en ligne:
set([i for i in list if sum([1 for a in list if a == i]) > 1])
Il y a beaucoup de réponses ici, mais je pense que c'est relativement très lisible et facile à comprendre démarche:
def get_duplicates(sorted_list):
duplicates = []
last = sorted_list[0]
for x in sorted_list[1:]:
if x == last:
duplicates.append(x)
last = x
return set(duplicates)
Notes:
- pour " set " en bas pour obtenir la liste complète
- Si vous préférez utiliser des générateurs, remplacer doublons.ajouter (x) avec rendement x et le retour déclaration au bas (vous pouvez lancer à définir plus tard)
Voici un rapide générateur qui utilise un dictionnaire pour stocker chaque élément comme une clé avec une valeur booléenne pour vérifier si l'article a déjà été donné.
pour les listes comportant tous les éléments qui sont des types hachables:
def gen_dupes(array):
unique = {}
for value in array:
if value in unique and unique[value]:
unique[value] = False
yield value
else:
unique[value] = True
array = [1, 2, 2, 3, 4, 1, 5, 2, 6, 6]
print(list(gen_dupes(array)))
# => [2, 1, 6]
pour les listes pouvant contenir des listes:
def gen_dupes(array):
unique = {}
for value in array:
is_list = False
if type(value) is list:
value = tuple(value)
is_list = True
if value in unique and unique[value]:
unique[value] = False
if is_list:
value = list(value)
yield value
else:
unique[value] = True
array = [1, 2, 2, [1, 2], 3, 4, [1, 2], 5, 2, 6, 6]
print(list(gen_dupes(array)))
# => [2, [1, 2], 6]
def removeduplicates(a):
seen = set()
for i in a:
if i not in seen:
seen.add(i)
return seen
print(removeduplicates([1,1,2,2]))
quelques autres essais. Bien sûr à faire...
set([x for x in l if l.count(x) > 1])
...est trop coûteux. Il est environ 500 fois plus rapide (le tableau plus long donne de meilleurs résultats) pour utiliser la prochaine méthode finale:
def dups_count_dict(l):
d = {}
for item in l:
if item not in d:
d[item] = 0
d[item] += 1
result_d = {key: val for key, val in d.iteritems() if val > 1}
return result_d.keys()
seulement 2 boucles, pas d'opérations l.count() très coûteuses.
Voici un code pour comparer les méthodes par exemple. Le code est ci-dessous, voici la sortie:
dups_count: 13.368s # this is a function which uses l.count()
dups_count_dict: 0.014s # this is a final best function (of the 3 functions)
dups_count_counter: 0.024s # collections.Counter
le code d'essai:
import numpy as np
from time import time
from collections import Counter
class TimerCounter(object):
def __init__(self):
self._time_sum = 0
def start(self):
self.time = time()
def stop(self):
self._time_sum += time() - self.time
def get_time_sum(self):
return self._time_sum
def dups_count(l):
return set([x for x in l if l.count(x) > 1])
def dups_count_dict(l):
d = {}
for item in l:
if item not in d:
d[item] = 0
d[item] += 1
result_d = {key: val for key, val in d.iteritems() if val > 1}
return result_d.keys()
def dups_counter(l):
counter = Counter(l)
result_d = {key: val for key, val in counter.iteritems() if val > 1}
return result_d.keys()
def gen_array():
np.random.seed(17)
return list(np.random.randint(0, 5000, 10000))
def assert_equal_results(*results):
primary_result = results[0]
other_results = results[1:]
for other_result in other_results:
assert set(primary_result) == set(other_result) and len(primary_result) == len(other_result)
if __name__ == '__main__':
dups_count_time = TimerCounter()
dups_count_dict_time = TimerCounter()
dups_count_counter = TimerCounter()
l = gen_array()
for i in range(3):
dups_count_time.start()
result1 = dups_count(l)
dups_count_time.stop()
dups_count_dict_time.start()
result2 = dups_count_dict(l)
dups_count_dict_time.stop()
dups_count_counter.start()
result3 = dups_counter(l)
dups_count_counter.stop()
assert_equal_results(result1, result2, result3)
print 'dups_count: %.3f' % dups_count_time.get_time_sum()
print 'dups_count_dict: %.3f' % dups_count_dict_time.get_time_sum()
print 'dups_count_counter: %.3f' % dups_count_counter.get_time_sum()
sans conversion en liste et probablement la manière la plus simple serait quelque chose comme ci-dessous. cela peut être utile lors d'une entrevue quand ils demandent de ne pas utiliser les ensembles
a=[1,2,3,3,3]
dup=[]
for each in a:
if each not in dup:
dup.append(each)
print(dup)
c'est la façon dont j'ai dû le faire parce que je me suis mis au défi de ne pas utiliser d'autres méthodes:
def dupList(oldlist):
if type(oldlist)==type((2,2)):
oldlist=[x for x in oldlist]
newList=[]
newList=newList+oldlist
oldlist=oldlist
forbidden=[]
checkPoint=0
for i in range(len(oldlist)):
#print 'start i', i
if i in forbidden:
continue
else:
for j in range(len(oldlist)):
#print 'start j', j
if j in forbidden:
continue
else:
#print 'after Else'
if i!=j:
#print 'i,j', i,j
#print oldlist
#print newList
if oldlist[j]==oldlist[i]:
#print 'oldlist[i],oldlist[j]', oldlist[i],oldlist[j]
forbidden.append(j)
#print 'forbidden', forbidden
del newList[j-checkPoint]
#print newList
checkPoint=checkPoint+1
return newList
donc votre échantillon fonctionne comme:
>>>a = [1,2,3,3,3,4,5,6,6,7]
>>>dupList(a)
[1, 2, 3, 4, 5, 6, 7]
Lorsqu'on utilise toolz :
from toolz import frequencies, valfilter
a = [1,2,2,3,4,5,4]
>>> list(valfilter(lambda count: count > 1, frequencies(a)).keys())
[2,4]
utilisez la fonction sort() . Les doublons peuvent être identifiés en faisant une boucle au-dessus et en cochant l1[i] == l1[i+1] .