Comment puis-je quantifier la différence entre deux images?
voici ce que j'aimerais faire:
je prends des photos avec une webcam à intervalles réguliers. Comme une sorte de time lapse chose. Toutefois, si rien n'a vraiment changé, c'est l'image assez bien regarde le même, je ne veux pas stocker le dernier instantané.
j'imagine qu'il y a un moyen de quantifier la différence, et je devrais déterminer empiriquement un seuil.
je suis vous cherchez la simplicité plutôt que la perfection. Je suis à l'aide de python.
20 réponses
idée Générale
Option 1: Charger les deux images en tableaux ( scipy.misc.imread ) et calculer une différence par élément (pixel par pixel). Calculer la norme de la différence.
Option 2: Charger les deux images. Calculer certaines disposent d'vecteur pour chacun d'eux (comme un histogramme). Calculez la distance entre les vecteurs caractéristiques plutôt que les images.
cependant, il y a certaines décisions à prendre en premier.
Questions
vous devez d'abord répondre à ces questions:
-
sont des images de la même forme et de la même dimension?
Si non, vous devrez peut-être redimensionner ou recadrer. PIL library vous aidera à le faire en Python.
S'ils sont pris avec les mêmes réglages et le même appareil, ils sont probablement les mêmes.
-
sont des images bien alignées?
si ce n'est pas le cas, vous pouvez effectuer la corrélation croisée en premier, pour trouver le meilleur alignement en premier. SciPy a des fonctions pour le faire.
Si la caméra et la scène sont toujours, les images sont susceptibles d'être bien alignés.
-
l'exposition des images est-elle toujours la même? (La légèreté / contraste est-elle la même?)
si non, vous pouvez vouloir pour normaliser image.
Mais attention, dans certaines situations, cela peut faire plus de mal que de bien. Par exemple, un seul pixel lumineux sur un fond sombre rendra l'image normalisée très différente.
-
l'information sur la couleur est-elle importante?
si vous voulez noter des changements de couleur, vous aurez un vecteur de valeurs de couleur par point, plutôt qu'une valeur scalaire comme dans l'image à échelle de gris. Vous avez besoin de plus d'attention quand Ecrire un tel code.
-
y a-t-il des bords distincts dans l'image? Sont-ils susceptibles de se déplacer?
si oui, vous pouvez appliquer l'algorithme de détection de bord d'abord (par exemple calculer le gradient avec la transformation de Sobel ou de Prewitt, appliquer un certain seuil), puis comparer les bords sur la première image aux bords sur la seconde.
-
y a-t-il du bruit dans l'image?
tous les capteurs polluent l'image avec une certaine quantité de bruit. Les détecteurs bon marché sont plus bruyants. Vous pouvez appliquer une réduction du bruit avant de comparer les images. Flou est l'approche la plus simple (mais pas la meilleure) ici.
-
Quels changements voulez-vous un avis?
cela peut affecter le choix de la norme à utiliser pour la différence entre les images.
envisager D'utiliser la norme Manhattan (la somme des valeurs absolues) ou zéro norme (le nombre d'éléments n'est pas égale à zéro) pour mesurer combien l'image a changé. Le premier vous dira combien l'image est désactivée, le second vous dira seulement combien de pixels diffèrent.
exemple
je suppose que vos images sont bien alignées, de la même taille et de la même forme, peut-être avec une exposition différente. Pour la simplicité, je les convertis en échelle de gris même s'il s'agit d'images couleur (RGB).
vous aurez besoin de ces importations:
import sys
from scipy.misc import imread
from scipy.linalg import norm
from scipy import sum, average
fonction principale, Lire deux images, convertir en échelle de gris, comparer et imprimer les résultats:
def main():
file1, file2 = sys.argv[1:1+2]
# read images as 2D arrays (convert to grayscale for simplicity)
img1 = to_grayscale(imread(file1).astype(float))
img2 = to_grayscale(imread(file2).astype(float))
# compare
n_m, n_0 = compare_images(img1, img2)
print "Manhattan norm:", n_m, "/ per pixel:", n_m/img1.size
print "Zero norm:", n_0, "/ per pixel:", n_0*1.0/img1.size
comment comparer. img1 et img2 sont des tableaux 2D SciPy ici:
def compare_images(img1, img2):
# normalize to compensate for exposure difference, this may be unnecessary
# consider disabling it
img1 = normalize(img1)
img2 = normalize(img2)
# calculate the difference and its norms
diff = img1 - img2 # elementwise for scipy arrays
m_norm = sum(abs(diff)) # Manhattan norm
z_norm = norm(diff.ravel(), 0) # Zero norm
return (m_norm, z_norm)
si le fichier est une image couleur, imread renvoie un tableau 3D, des canaux RVB moyens (le dernier axe du tableau) pour obtenir l'intensité. Pas besoin de le faire pour les images en niveaux de gris (par exemple .pgm ):
def to_grayscale(arr):
"If arr is a color image (3D array), convert it to grayscale (2D array)."
if len(arr.shape) == 3:
return average(arr, -1) # average over the last axis (color channels)
else:
return arr
la normalisation est triviale, vous pouvez choisir de normaliser à [0,1] au lieu de [0,255]. arr est un tableau SciPy ici, ainsi toutes les opérations sont element-wise:
def normalize(arr):
rng = arr.max()-arr.min()
amin = arr.min()
return (arr-amin)*255/rng
Exécuter main de la fonction:
if __name__ == "__main__":
main()
Maintenant vous pouvez mettre tout cela dans un script et courir contre deux images. Si nous comparons l'image à elle-même, il n'y a pas de différence:
$ python compare.py one.jpg one.jpg
Manhattan norm: 0.0 / per pixel: 0.0
Zero norm: 0 / per pixel: 0.0
si nous brouillons l'image et la comparons à l'original, il y a une différence:
$ python compare.py one.jpg one-blurred.jpg
Manhattan norm: 92605183.67 / per pixel: 13.4210411116
Zero norm: 6900000 / per pixel: 1.0
P. S. entier compare.py script.
mise à Jour: les techniques pertinentes
comme la question porte sur une séquence vidéo, où les images sont probablement presque les mêmes, et que vous cherchez quelque chose d'inhabituel, j'aimerais mentionner quelques approches alternatives qui peuvent être pertinentes:
- soustraction et segmentation du fond (pour détecter les objets du premier plan)
- écoulement optique clairsemé (pour détecter le mouvement)
- comparer des histogrammes ou d'autres statistiques au lieu d'images
je recommande vivement de jeter un oeil au livre" Learning OpenCV", chapitres 9 (parties D'Image et segmentation) et 10 (Tracking et motion). Le premier enseigne à utiliser la méthode de soustraction de fond, le ce dernier donne quelques informations sur les méthodes d'écoulement optique. Toutes les méthodes sont implémentées dans la bibliothèque OpenCV. Si vous utilisez Python, je vous suggère D'utiliser OpenCV ≥ 2.3, et son module Python cv2 .
la version la plus simple de la soustraction de fond:
- apprendre la valeur moyenne μ et l'écart-type σ pour chaque pixel de l'arrière-plan
- comparer les valeurs actuelles des pixels à la plage de (μ-2σ, μ+2σ) ou (μ-σ, μ+σ)
les versions plus avancées prennent en compte les séries chronologiques pour chaque pixel et gèrent les scènes non statiques (comme le déplacement des arbres ou de l'herbe).
l'idée du flux optique est de prendre deux ou plusieurs cadres, et d'attribuer un vecteur de vitesse à chaque pixel (flux optique dense) ou à certains d'entre eux (flux optique clairsemé). Pour estimer le débit optique clairsemé, vous pouvez utiliser la méthode Lucas-Kanade (elle est également implémentée dans OpenCV). Évidemment, s'il y a beaucoup de flux (moyenne élevée sur les valeurs max du champ de vitesse), alors quelque chose se déplace dans le cadre, et les images suivantes sont plus différentes.
comparer les histogrammes peut aider à détecter les changements soudains entre les cadres consécutifs. Cette approche a été utilisée dans Courbon et al, 2010 :
"15191400920 la" Similarité des images consécutives. la distance entre deux les montures consécutives sont mesurées. Si elle est trop élevée, cela signifie que la deuxième image est corrompu et donc l'image est éliminé. Le kullback–Leibler distance , ou entropie mutuelle, sur les histogrammes des deux cadres:
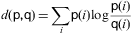
où p et q sont les histogrammes des cadres utilisés. Le seuil est fixé à 0.2.
une solution simple:
encodez l'image comme un jpeg et cherchez un changement important dans filesize .
j'ai implémenté quelque chose de similaire avec des vignettes vidéo, et j'ai eu beaucoup de succès et d'évolutivité.
vous pouvez comparer deux images en utilisant les fonctions de PIL .
import Image
import ImageChops
im1 = Image.open("splash.png")
im2 = Image.open("splash2.png")
diff = ImageChops.difference(im2, im1)
La diff objet est une image dans laquelle chaque pixel est le résultat de la soustraction des valeurs de couleur de ce pixel dans la seconde image de la première image. En utilisant l'image diff, vous pouvez faire plusieurs choses. Le plus simple est la fonction diff.getbbox() . Il vous indiquera le rectangle minimal qui contient tous les changements entre vos deux images.
vous pouvez probablement implémenter des approximations des autres choses mentionnées ici en utilisant des fonctions de PIL aussi bien.
deux méthodes populaires et relativement simples sont: (a) la distance euclidienne déjà suggérée, ou (B) La corrélation croisée normalisée. La corrélation croisée normalisée tend à être nettement plus robuste aux changements d'éclairage que la simple corrélation croisée. Wikipedia donne une formule pour la corrélation normalisée . Des méthodes plus sophistiquées existent aussi, mais ils nécessitent un peu plus de travail.
Utilisation de numpy syntaxe,
dist_euclidean = sqrt(sum((i1 - i2)^2)) / i1.size dist_manhattan = sum(abs(i1 - i2)) / i1.size dist_ncc = sum( (i1 - mean(i1)) * (i2 - mean(i2)) ) / ( (i1.size - 1) * stdev(i1) * stdev(i2) )
en présumant que i1 et i2 sont des tableaux d'images en 2D à échelle de gris.
Une chose banale à essayer:
Rééchantillonnez les deux images en petites vignettes (par exemple 64 x 64) et comparez les vignettes pixel par pixel avec un certain seuil. Si les images originales sont presque identiques, les vignettes rééchantillonnées seront très similaires ou même exactement identiques. Cette méthode prend soin du bruit qui peut se produire en particulier dans les scènes de faible luminosité. C'est peut-être même mieux si tu vas à grayscale.
j'aborde spécifiquement la question de savoir comment calculer s'ils sont"suffisamment différents". Je suppose que vous pouvez comprendre comment soustraire les pixels un par un.
tout d'abord, je prendrais un tas d'images avec rien changeant, et découvrir la quantité maximale que tout pixel change juste en raison de variations dans la capture, le bruit dans le système d'imagerie, les artefacts de compression JPEG, et les changements de moment en moment dans l'éclairage. Peut-être vous constaterez qu'il faut s'attendre à des différences de 1 ou 2 bits même si rien ne bouge.
puis pour le" vrai "test, vous voulez un critère comme celui-ci:
- même si jusqu'à P les pixels ne diffèrent pas de plus de E.
donc, peut-être, si E = 0,02, P = 1000, cela signifierait (approximativement) qu'il serait "différent" si un seul pixel change de plus de ~5 unités (en supposant des images 8 bits), ou si plus de 1000 pixels avait des erreurs.
il s'agit principalement d'une bonne technique de" triage " permettant d'identifier rapidement les images suffisamment proches pour ne pas nécessiter un examen plus approfondi. Les images qui "échouent" peuvent alors être plus à une technique plus élaborée/coûteuse qui n'aurait pas de faux positifs si la caméra tremblait un peu, par exemple, ou était plus robuste à des changements d'éclairage.
je dirige un projet open source, OpenImageIO , qui contient un utilitaire appelé "idiff" qui compare les différences avec des seuils comme celui-ci (encore plus élaboré, en fait). Même si vous ne voulez pas utiliser ce logiciel, vous pouvez regarder la source pour voir comment nous l'avons fait. Il est utilisé commercialement assez peu et cette technique de battage a été développé de sorte que nous pourrions avoir une suite de test pour le rendu et le logiciel de traitement d'image, avec des "images de référence" qui pourraient avoir de petites différences de plate-forme à plate-forme ou comme nous avons fait des retouches mineures aux algorithmes tha, donc nous voulions une opération "match within tolerance".
la plupart des réponses données ne concernent pas les niveaux d'éclairage.
je voudrais d'abord normaliser l'image à un niveau de lumière standard avant de faire la comparaison.
avez-vous vu L'algorithme pour trouver des images similaires question? Consultez - le pour voir les suggestions.
je suggérerais une transformation en ondelette de vos cadres (j'ai écrit une extension C pour cela en utilisant la transformation Haar); puis, en comparant les indices des plus grands (proportionnellement) facteurs en ondelette entre les deux images, vous devriez obtenir une approximation de similarité numérique.
j'ai eu un problème similaire au travail, je réécrivais notre image transform endpoint et je voulais vérifier que la nouvelle version produisait la même ou presque la même sortie que l'ancienne version. Alors j'ai écrit ceci:
https://github.com/nicolashahn/diffimg
qui fonctionne sur des images de même taille, et à un niveau par pixel, mesure la différence de valeurs à chaque canal: R, G, B (, A), prend la moyenne différence de ces canaux, Puis fait la moyenne de la différence sur tous les pixels, et renvoie un ratio.
par exemple, avec une image 10x10 de pixels blancs, et la même image mais un pixel a changé en rouge, la différence à ce pixel est de 1/3 ou 0,33... (RGB 0,0,0 vs 255,0,0) et à tous les autres pixels est 0. Avec un total de 100 pixels, 0.33.../ 100 = une différence d'environ 0,33% dans l'image.
je crois que cela fonctionnerait parfaitement pour le projet de L'OP (je me rends compte que c'est un très ancien post maintenant, mais postant pour les futurs Stackoverfflowers qui veulent aussi comparer des images en python).
Je m'excuse si c'est trop tard pour répondre, mais comme j'ai fait quelque chose de semblable, j'ai pensé que je pourrais contribuer d'une façon ou d'une autre.
peut-être Qu'avec OpenCV vous pourriez utiliser un modèle de correspondance. En supposant que vous utilisez une webcam comme vous avez dit:
- simplifier les images (battage peut-être?)
- appliquer le modèle de correspondance et de vérifier le max_val avec minMaxLoc
Conseil: max_val (ou min_val selon la méthode utilisée) vous donnera des nombres, de grands nombres. Pour obtenir la différence en pourcentage, utilisez le modèle correspondant à la même image -- le résultat sera votre 100%.
Pseudo code pour illustrer:
previous_screenshot = ...
current_screenshot = ...
# simplify both images somehow
# get the 100% corresponding value
res = matchTemplate(previous_screenshot, previous_screenshot, TM_CCOEFF)
_, hundred_p_val, _, _ = minMaxLoc(res)
# hundred_p_val is now the 100%
res = matchTemplate(previous_screenshot, current_screenshot, TM_CCOEFF)
_, max_val, _, _ = minMaxLoc(res)
difference_percentage = max_val / hundred_p_val
# the tolerance is now up to you
J'espère que ça aidera.
Terre de déménageurs à distance pourrait être exactement ce dont vous avez besoin. Il pourrait être abit lourde à mettre en œuvre en temps réel si.
qu'en est-il du calcul de la Manhattan Distance des deux images. Cela vous donne des valeurs n*N. Alors vous pourriez faire quelque chose comme une moyenne de ligne pour réduire à n Les valeurs et une fonction au-dessus de cela pour obtenir une seule valeur.
j'ai eu beaucoup de chance avec jpg images prises avec le même appareil sur un trépied par (1) simplifier considérablement (comme passer de 3000 pixels de large à 100 pixels de large ou même moins)) (2) aplatir chaque réseau de jpg en un seul vecteur (3) corréler par paires des images séquentielles avec un algorithme corrélé simple pour obtenir le coefficient de corrélation (4)Coefficient de corrélation de quadrature pour obtenir R-carré (I. e fraction de variabilité dans une image expliquée par la variation dans la suivante) (5) généralement dans mon application si r-square < 0.9, je dis que les deux images sont différentes et que quelque chose s'est passé entre les deux.
c'est robuste et rapide dans ma mise en œuvre (Mathematica 7)
cela vaut la peine de jouer avec la partie de l'image qui vous intéresse et de se concentrer sur cela en coupant toutes les images à cette petite zone, sinon un lointain-de-la-caméra, mais un changement important sera manqué.
Je ne sais pas comment utiliser Python, mais je suis sûr qu'il fait des corrélations, aussi, Non?
vous pouvez calculer l'histogramme des deux images et puis calculer le coefficient Bhattacharyya , c'est un algorithme très rapide et je l'ai utilisé pour détecter les changements de prise de vue dans une vidéo de cricket (en C en utilisant openCV)
découvrez comment Haar Wavelets sont mis en œuvre par isk-daemon . Vous pouvez utiliser son code imgdb C++ pour calculer la différence entre les images à la volée:
isk-daemon est un serveur de base de données open source capable d'ajouter la recherche d'image (visuelle) basée sur le contenu à n'importe quel site web ou logiciel lié à l'image.
cette technologie permet aux utilisateurs de tout site web ou logiciel lié à l'image de dessiner sur un widget quelle image ils veulent trouver et que le site web leur réponde les images les plus similaires ou tout simplement demander des photos plus similaires à chaque page de détail d'image.
j'ai eu le même problème et j'ai écrit un module python simple qui compare deux images de même taille en utilisant ImageChops de pillow pour créer une image en noir et blanc diff et résume les valeurs de l'histogramme.
vous pouvez obtenir soit ce score directement, soit une valeur de pourcentage par rapport à un Complet Noir vs. Blanc diff.
il contient également une fonction is_equal simple, avec la possibilité de fournir un seuil flou sous (et y compris) l'image passe comme égal.
l'approche n'est pas très élaborée, mais peut-être est utile pour d'autres là-bas aux prises avec le même problème.
une approche un peu plus fondée est d'utiliser un descripteur global pour comparer des images, comme GIST ou CENTRIST. Une fonction de hachage, comme décrit ici , fournit également une solution similaire.
une autre façon simple et agréable de mesurer la similitude entre deux images:
import sys
from skimage.measure import compare_ssim
from skimage.transform import resize
from scipy.ndimage import imread
# get two images - resize both to 1024 x 1024
img_a = resize(imread(sys.argv[1]), (2**10, 2**10))
img_b = resize(imread(sys.argv[2]), (2**10, 2**10))
# score: {-1:1} measure of the structural similarity between the images
score, diff = compare_ssim(img_a, img_b, full=True)
print(score)
si d'autres sont intéressés à une façon plus puissante de comparer la similitude d'image, j'ai mis en place un tutorial et web app pour la mesure et la visualisation d'images similaires en utilisant Tensorflow.
import os
from PIL import Image
from PIL import ImageFile
import imagehash
#just use to the size diferent picture
def compare_image(img_file1, img_file2):
if img_file1 == img_file2:
return True
fp1 = open(img_file1, 'rb')
fp2 = open(img_file2, 'rb')
img1 = Image.open(fp1)
img2 = Image.open(fp2)
ImageFile.LOAD_TRUNCATED_IMAGES = True
b = img1 == img2
fp1.close()
fp2.close()
return b
#through picturu hash to compare
def get_hash_dict(dir):
hash_dict = {}
image_quantity = 0
for _, _, files in os.walk(dir):
for i, fileName in enumerate(files):
with open(dir + fileName, 'rb') as fp:
hash_dict[dir + fileName] = imagehash.average_hash(Image.open(fp))
image_quantity += 1
return hash_dict, image_quantity
def compare_image_with_hash(image_file_name_1, image_file_name_2, max_dif=0):
"""
max_dif: The maximum hash difference is allowed, the smaller and more accurate, the minimum is 0.
recommend to use
"""
ImageFile.LOAD_TRUNCATED_IMAGES = True
hash_1 = None
hash_2 = None
with open(image_file_name_1, 'rb') as fp:
hash_1 = imagehash.average_hash(Image.open(fp))
with open(image_file_name_2, 'rb') as fp:
hash_2 = imagehash.average_hash(Image.open(fp))
dif = hash_1 - hash_2
if dif < 0:
dif = -dif
if dif <= max_dif:
return True
else:
return False
def compare_image_dir_with_hash(dir_1, dir_2, max_dif=0):
"""
max_dif: The maximum hash difference is allowed, the smaller and more accurate, the minimum is 0.
"""
ImageFile.LOAD_TRUNCATED_IMAGES = True
hash_dict_1, image_quantity_1 = get_hash_dict(dir_1)
hash_dict_2, image_quantity_2 = get_hash_dict(dir_2)
if image_quantity_1 > image_quantity_2:
tmp = image_quantity_1
image_quantity_1 = image_quantity_2
image_quantity_2 = tmp
tmp = hash_dict_1
hash_dict_1 = hash_dict_2
hash_dict_2 = tmp
result_dict = {}
for k in hash_dict_1.keys():
result_dict[k] = None
for dif_i in range(0, max_dif + 1):
have_none = False
for k_1 in result_dict.keys():
if result_dict.get(k_1) is None:
have_none = True
if not have_none:
return result_dict
for k_1, v_1 in hash_dict_1.items():
for k_2, v_2 in hash_dict_2.items():
sub = (v_1 - v_2)
if sub < 0:
sub = -sub
if sub == dif_i and result_dict.get(k_1) is None:
result_dict[k_1] = k_2
break
return result_dict
def main():
print(compare_image('image1\815.jpg', 'image2\5.jpg'))
print(compare_image_with_hash('image1\815.jpg', 'image2\5.jpg', 6))
r = compare_image_dir_with_hash('image1\', image2\', 10)
for k in r.keys():
print(k, r.get(k))
if __name__ == '__main__':
main()
-
sortie:
False
Vrai
image2\5.jpg image1\815.jpg
image2\6.jpg image1\819.jpg
image2\7.jpg image1\900.jpg
image2\8.jpg image1\998.jpg
image2\9.jpg image1\1012.jpg
-
les images de l'exemple:
-
815.jpg

-
5.jpg

-
je pense que vous pourriez simplement calculer la distance euclidienne (i.e. sqrt(somme des carrés des différences, pixel par pixel)) entre la luminance des deux images, et les considérer égaux si cela tombe sous un certain seuil empirique. Et tu ferais mieux de le faire en enveloppant une fonction C.