Comment puis-je effectuer une interpolation bidimensionnelle en utilisant scipy?
Ce Q & A est conçu comme un canonique (- ish) concernant l'interpolation bidimensionnelle (et multidimensionnelle) en utilisant scipy. Il y a souvent des questions concernant la syntaxe de base de diverses méthodes d'interpolation multidimensionnelle, j'espère les mettre au clair aussi.
J'ai un ensemble de points de données bidimensionnels dispersés, et je voudrais les tracer comme une belle surface, de préférence en utilisant quelque chose comme contourf ou plot_surface dans matplotlib.pyplot. Comment puis-je interpoler mon données bidimensionnelles ou multidimensionnelles à un maillage en utilisant scipy?
J'ai trouvé le sous-paquet scipy.interpolate, mais je continue à avoir des erreurs en utilisant interp2d ou bisplrep ou griddata ou rbf. Quelle est la syntaxe appropriée de ces méthodes?
1 réponses
Avertissement: j'écris principalement ce post avec des considérations syntaxiques et un comportement général à l'esprit. Je ne suis pas familier avec l'aspect mémoire et CPU des méthodes décrites, et je vise cette réponse à ceux qui ont des ensembles de données raisonnablement petits, de sorte que la qualité de l'interpolation peut être l'aspect principal à considérer. Je suis conscient que lorsque vous travaillez avec de très grands ensembles de données, les méthodes les plus performantes (à savoir griddata et Rbf) pourraient ne pas être réalisables.
Je vais comparez trois types de méthodes d'interpolation multidimensionnelle(interp2d/cannelures, griddata et Rbf). Je vais les soumettre à deux types de tâches d'interpolation et deux types de fonctions sous-jacentes (points à partir desquels doivent être interpolés). Les exemples spécifiques démontreront l'interpolation bidimensionnelle, mais les méthodes viables sont applicables dans des dimensions arbitraires. Chaque méthode fournit différents types d'interpolation; dans tous les cas, je vais utiliser cubique l'interpolation (ou quelque chose de proche1). Il est important de noter que chaque fois que vous utilisez l'interpolation, vous introduisez un biais par rapport à vos données brutes, et les méthodes spécifiques utilisées affectent les artefacts avec lesquels vous finirez. Soyez toujours conscient de cela et interpolez de manière responsable.
Les deux tâches d'interpolation seront
- suréchantillonnage (les données d'entrée sont sur une grille rectangulaire, les données de sortie sont sur une grille plus dense)
- interpolation de données dispersées sur un grille régulière
Les deux fonctions (sur le domaine [x,y] in [-1,1]x[-1,1]) est
- une fonction douce et amicale:
cos(pi*x)*sin(pi*y); gamme dans[-1, 1] - une fonction maléfique (et en particulier non continue): {[16] } avec une valeur de 0,5 proche de l'origine; plage dans
[-0.5, 0.5]
Voici à quoi ils ressemblent:
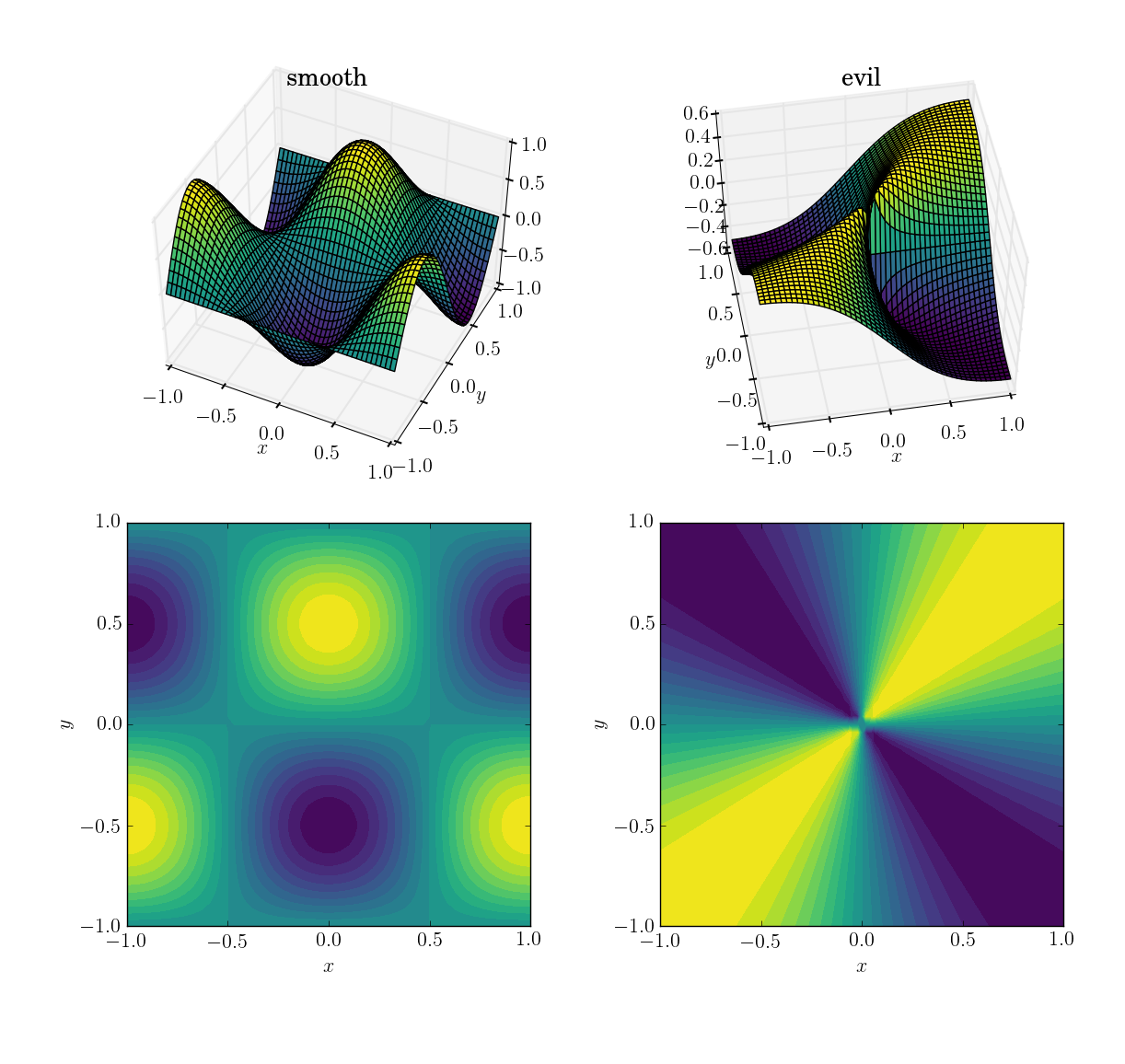
Je vais d'abord démontrer comment les trois méthodes se comportent sous ces quatre tests, puis je détaillerai la syntaxe de tous trois. Si vous savez ce que vous devez attendre d'une méthode, vous ne voudrez peut-être pas perdre votre temps à apprendre sa syntaxe (en vous regardant, interp2d).
Données D'essai
Par souci d'explicitation, voici le code avec lequel j'ai généré les données d'entrée. Bien que dans ce cas spécifique, je sois évidemment conscient de la fonction sous-jacente aux données, Je ne l'utiliserai que pour générer des entrées pour les méthodes d'interpolation. J'utilise numpy pour plus de commodité (et surtout pour générer les données) , mais scipy à elle seule, suffit aussi.
import numpy as np
import scipy.interpolate as interp
# auxiliary function for mesh generation
def gimme_mesh(n):
minval = -1
maxval = 1
# produce an asymmetric shape in order to catch issues with transpositions
return np.meshgrid(np.linspace(minval,maxval,n), np.linspace(minval,maxval,n+1))
# set up underlying test functions, vectorized
def fun_smooth(x, y):
return np.cos(np.pi*x)*np.sin(np.pi*y)
def fun_evil(x, y):
# watch out for singular origin; function has no unique limit there
return np.where(x**2+y**2>1e-10, x*y/(x**2+y**2), 0.5)
# sparse input mesh, 6x7 in shape
N_sparse = 6
x_sparse,y_sparse = gimme_mesh(N_sparse)
z_sparse_smooth = fun_smooth(x_sparse, y_sparse)
z_sparse_evil = fun_evil(x_sparse, y_sparse)
# scattered input points, 10^2 altogether (shape (100,))
N_scattered = 10
x_scattered,y_scattered = np.random.rand(2,N_scattered**2)*2 - 1
z_scattered_smooth = fun_smooth(x_scattered, y_scattered)
z_scattered_evil = fun_evil(x_scattered, y_scattered)
# dense output mesh, 20x21 in shape
N_dense = 20
x_dense,y_dense = gimme_mesh(N_dense)
Bon fonctionnement et suréchantillonnage
Commençons par la tâche la plus simple. Voici comment un suréchantillonnage d'un maillage de forme [6,7] à l'un des [20,21] Fonctionne pour la fonction de test lisse:
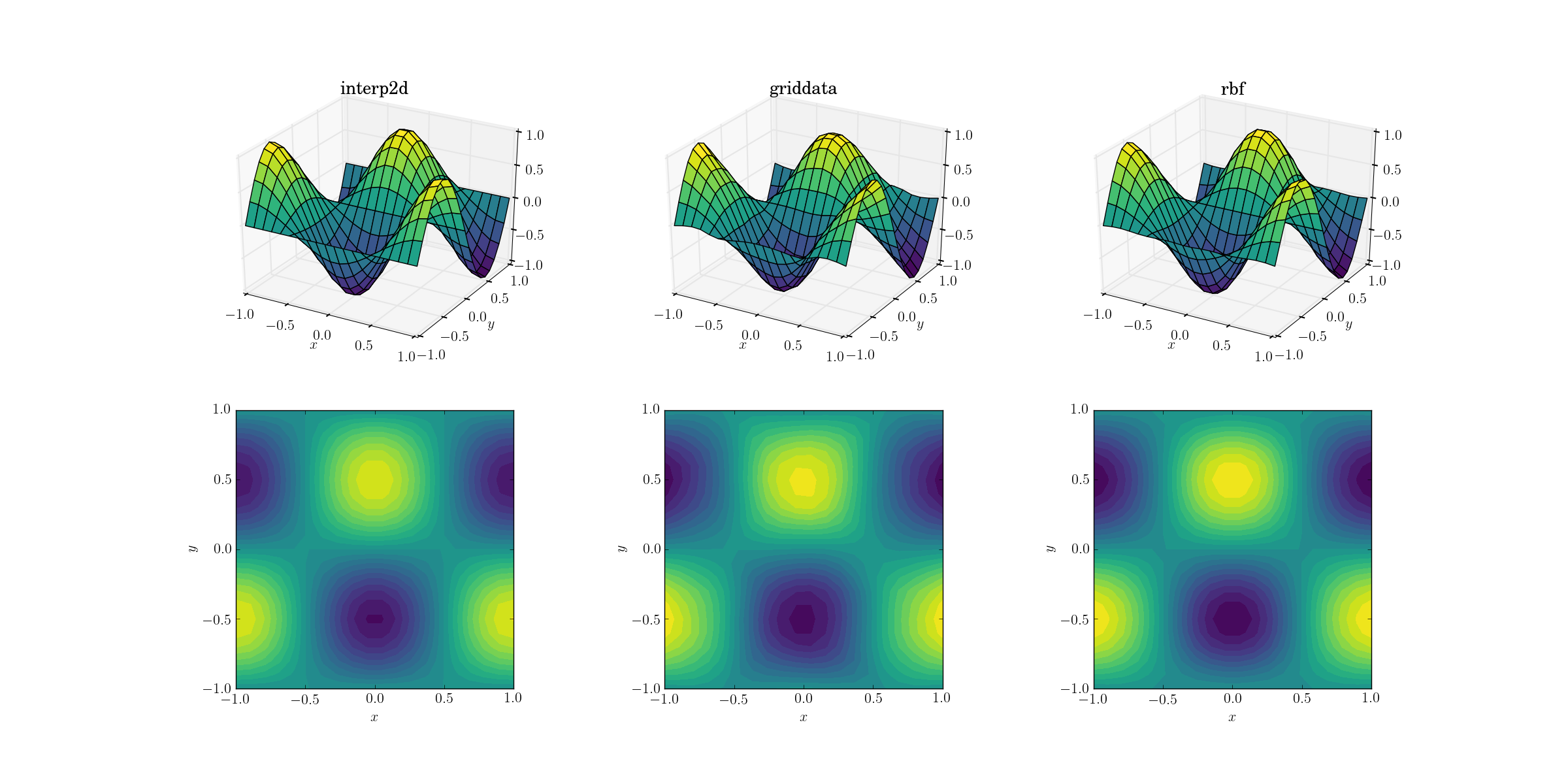
Même s'il s'agit d'une tâche simple, il existe déjà des différences subtiles entre les sorties. À première vue, les trois sorties sont raisonnables. Il y a deux caractéristiques à noter, sur la base de notre connaissance préalable de la fonction sous-jacente: le cas intermédiaire de griddata déforme le plus les données. Notez la limite y==-1 du tracé (la plus proche de l'étiquette x): la fonction doit être strictement nulle (puisque y==-1 est une ligne nodale pour la fonction lisse), mais ce n'est pas le cas pour griddata. Notez également la limite x==-1 des tracés (derrière, à gauche): la fonction sous-jacente a un maximum local (impliquant un gradient zéro près de la limite) à [-1, -0.5], mais la sortie griddata montre clairement un gradient non nul dans cette région. L'effet est subtil, mais c'est un biais néanmoins. (La fidélité de Rbf est encore meilleure avec le choix par défaut des fonctions radiales, surnommées multiquadratic.)
Fonction maléfique et suréchantillonnage
Une tâche un peu plus difficile est d'effectuer un suréchantillonnage sur notre fonction maléfique:
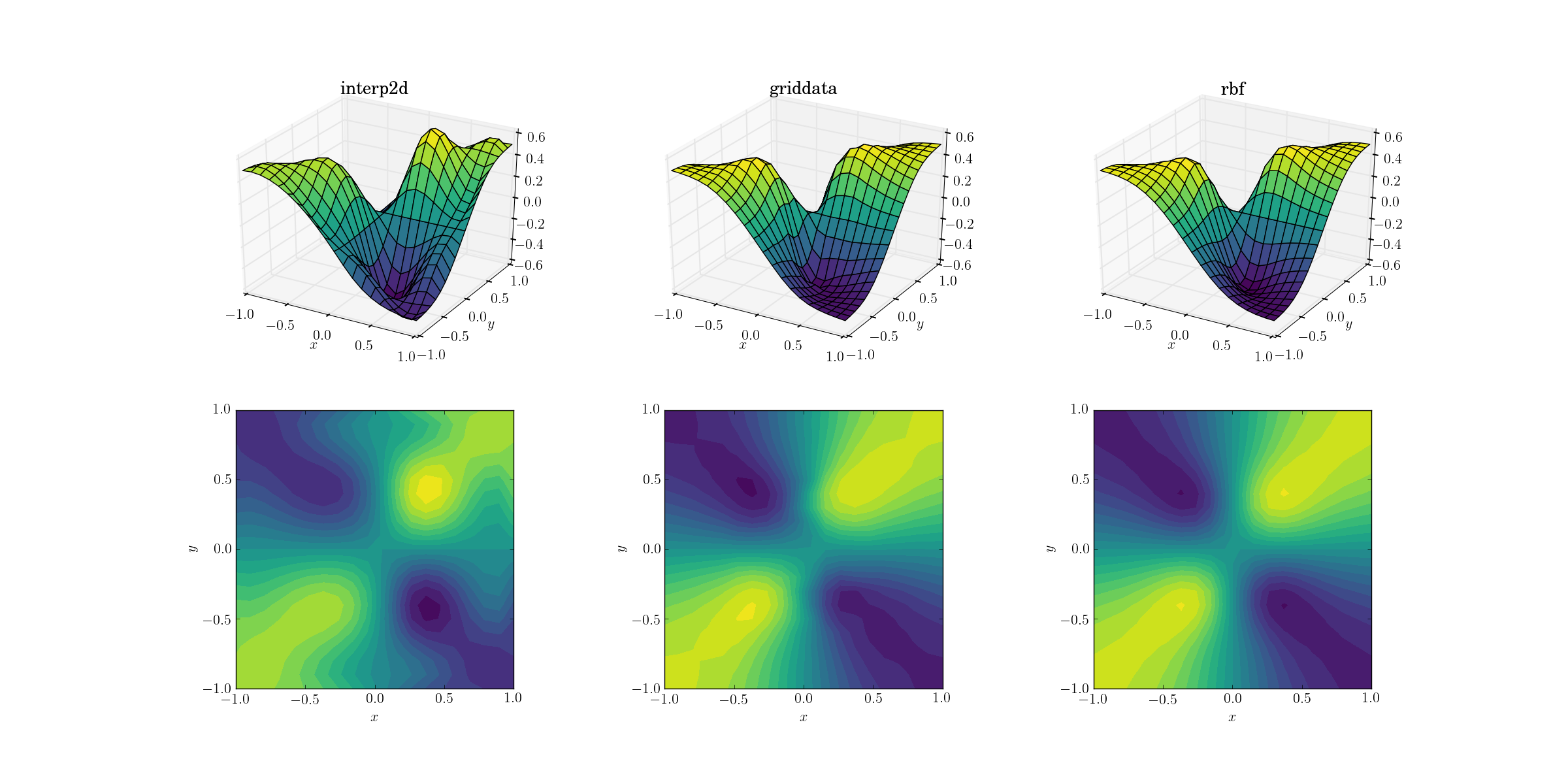
Des différences claires commencent à apparaître entre les trois méthodes. En regardant les tracés de surface, il y a des extrema parasites clairs apparaissant dans la sortie de interp2d (notez les deux bosses sur le côté droit de la surface tracée). Alors que griddata et Rbf semblent produire des résultats similaires à première vue, ce dernier semble produire un minimum plus profond proche de [0.4, -0.4] qui est absent de la fonction sous-jacente.
Cependant, il y a un aspect crucial dans lequel Rbf est de loin supérieur: il respecte la symétrie de la fonction sous-jacente (qui est bien sûr également rendue possible par la symétrie du maillage de l'échantillon). La sortie de griddata rompt la symétrie des points d'échantillonnage, ce qui est déjà faiblement visible dans le cas lisse.
Fonction lisse et données dispersées
Le plus souvent, on veut effectuer une interpolation sur des données dispersées. Pour cette raison, je m'attends à ce que ces tests soient plus importants. Comme indiqué ci-dessus, les points d'échantillonnage ont été choisis pseudo-uniforme dans le domaine d'intérêt. Dans des scénarios réalistes, vous pourriez avoir un bruit supplémentaire à chaque mesure, et vous devriez considérer s'il est logique d'interpoler vos données brutes pour commencer avec.
Sortie pour la fonction lisse:
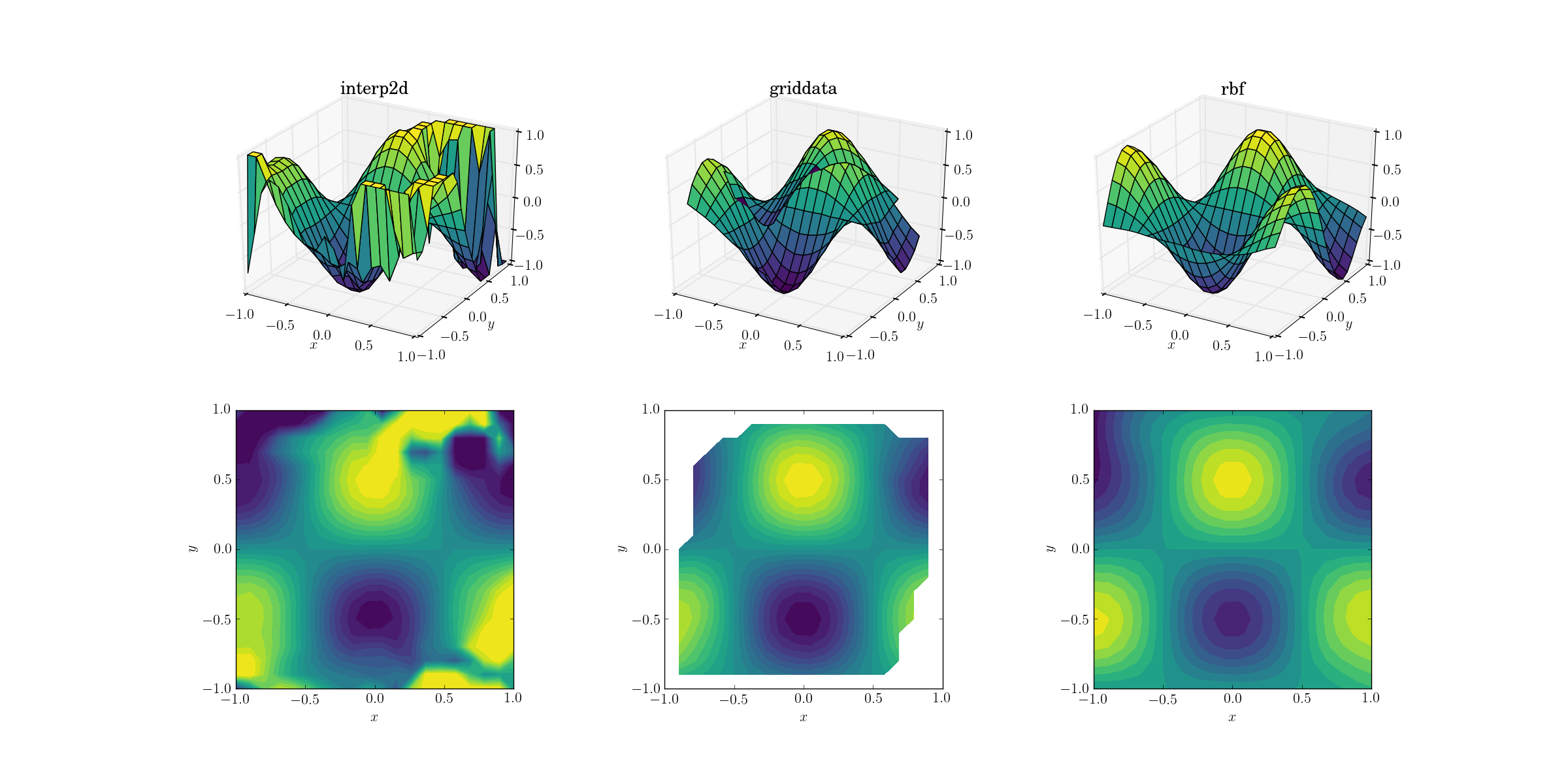
Maintenant, il y a déjà un peu de spectacle d'horreur en cours. J'ai coupé la sortie de {[10] } à entre [-1, 1] exclusivement pour le traçage, afin de préserver au moins une quantité minimale d'informations. Il est clair que si une partie de la forme sous-jacente est présente, il existe d'énormes régions bruyantes où la méthode se décompose complètement. Le deuxième cas de griddata reproduit assez bien la forme, mais notez le régions blanches à la frontière de la parcelle de contour. Cela est dû au fait que griddata ne fonctionne qu'à l'intérieur de la coque convexe des points de données d'entrée (en d'autres termes, il n'effectue aucune extrapolation ). J'ai gardé la valeur NaN par défaut pour les points de sortie situés à l'extérieur de la coque convexe.2 compte tenu de ces caractéristiques, Rbf semble fonctionner le mieux.
Fonction maléfique et données dispersées
Et le moment que nous avons tous attendu pour:
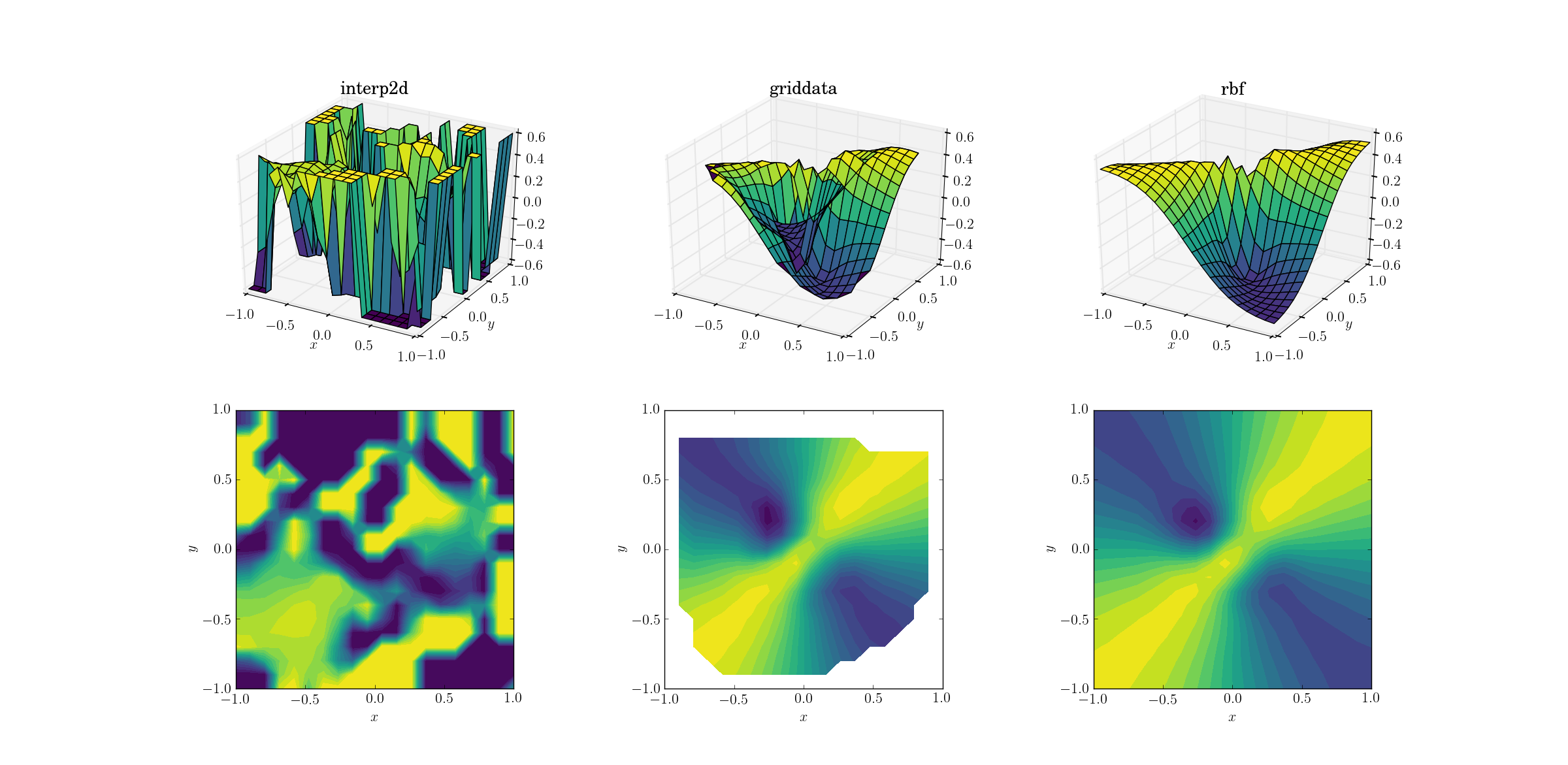
Ce n'est pas une grande surprise que interp2d abandonne. En fait, lors de l'appel à interp2d, vous devriez vous attendre à ce que des RuntimeWarningamicaux se plaignent de l'impossibilité de construire la spline. Comme pour les deux autres méthodes, Rbf semble produire la meilleure sortie, même près des frontières du domaine où le résultat est extrapolé.
Permettez-moi donc de dire quelques mots sur les trois méthodes, par ordre décroissant de préférence (de sorte que le pire est le moins susceptible d'être lu par quiconque).
scipy.interpolate.Rbf
La classe Rbf signifie "fonctions de base radiales". Pour être honnête, je n'ai jamais envisagé cette approche jusqu'à ce que je commence à faire des recherches pour ce post, mais je suis sûr que je vais les utiliser à l'avenir.
Tout comme les méthodes basées sur spline (voir plus loin), l'utilisation se fait en deux étapes: la première crée une instance de classe Rbf appelable en fonction des données d'entrée, puis appelle cet objet pour une sortie donnée maillage pour obtenir le résultat interpolé. Exemple du test de suréchantillonnage en douceur:
import scipy.interpolate as interp
zfun_smooth_rbf = interp.Rbf(x_sparse, y_sparse, z_sparse_smooth, function='cubic', smooth=0) # default smooth=0 for interpolation
z_dense_smooth_rbf = zfun_smooth_rbf(x_dense, y_dense) # not really a function, but a callable class instance
Notez que les points d'entrée et de sortie étaient des tableaux 2d dans ce cas, et la sortie z_dense_smooth_rbf a la même forme que x_dense et y_dense sans aucun effort. Notez également que Rbf prend en charge les dimensions arbitraires pour l'interpolation.
Donc, scipy.interpolate.Rbf
- produit une sortie bien comportée même pour des données d'entrée folles
- prend en charge l'interpolation dans dimensions
- extrapole en dehors de la coque convexe des points d'entrée (bien sûr, l'extrapolation est toujours un pari, et vous ne devriez généralement pas y compter du tout)
- crée un interpolateur comme première étape, donc l'évaluer dans divers points de sortie est moins d'effort supplémentaire
- peut avoir des points de sortie de forme arbitraire (par opposition à être contraint à des mailles rectangulaires, voir plus loin)
- enclin à préserver la symétrie de l'entrée données
- prend en charge plusieurs types de fonctions radiales pour le mot-clé
function:multiquadric,inverse,gaussian,linear,cubic,quintic,thin_platedéfinies par l'utilisateur et arbitraire
scipy.interpolate.griddata
Mon ancien favori, griddata, est un cheval de bataille général pour l'interpolation dans des dimensions arbitraires. Il n'effectue pas d'extrapolation au-delà de la définition d'une seule valeur prédéfinie pour les points en dehors de la coque convexe des points nodaux, mais comme l'extrapolation est une chose très inconstante et dangereuse, c'est pas nécessairement un exemple d'utilisation con.:
z_dense_smooth_griddata = interp.griddata(np.array([x_sparse.ravel(),y_sparse.ravel()]).T,
z_sparse_smooth.ravel(),
(x_dense,y_dense), method='cubic') # default method is linear
Notez la syntaxe légèrement kludgy. Les points d'entrée doivent être spécifiés dans un tableau de forme [N, D] dans D dimensions. Pour cela, nous devons d'abord aplatir nos tableaux de coordonnées 2d (en utilisant ravel), puis concaténer les tableaux et transposer le résultat. Il y a plusieurs façons de le faire, mais tous semblent être encombrant. Les données d'entrée z doivent également être aplaties. Nous avons un peu plus de liberté en ce qui concerne les points de sortie: pour certains raison ceux-ci peuvent également être spécifiés comme un tuple de tableaux multidimensionnels. Notez que le help de {[8] } est trompeur, car il suggère que la même chose est vraie pour lesinput points (au moins pour la version 0.17.0):
griddata(points, values, xi, method='linear', fill_value=nan, rescale=False)
Interpolate unstructured D-dimensional data.
Parameters
----------
points : ndarray of floats, shape (n, D)
Data point coordinates. Can either be an array of
shape (n, D), or a tuple of `ndim` arrays.
values : ndarray of float or complex, shape (n,)
Data values.
xi : ndarray of float, shape (M, D)
Points at which to interpolate data.
En un mot, scipy.interpolate.griddata
- produit une sortie bien comportée même pour des données d'entrée folles
- prend en charge l'interpolation dans les dimensions supérieures
- n'effectue pas d'extrapolation, une seule valeur peut être définie pour la sortie en dehors du l'enveloppe convexe des points d'entrée (voir
fill_value) - calcule les valeurs interpolées en un seul appel, de sorte que le sondage de plusieurs ensembles de points de sortie commence à partir de zéro
- peut avoir des points de sortie de forme arbitraire
- prend en charge l'interpolation linéaire et la plus proche voisine dans des dimensions arbitraires, cubiques en 1d et 2D. l'interpolation linéaire et la plus proche voisine utilisent respectivement
NearestNDInterpolatoretLinearNDInterpolatorsous le capot. 1D Cubic interpolation utilise une spline, 2D cubique interpolation utiliseCloughTocher2DInterpolatorpour construire un interpolateur cubique par morceaux différentiable en continu. - pourrait violer la symétrie des données d'entrée
scipy.interpolate.interp2d/scipy.interpolate.bisplrep
La seule raison pour laquelle je parle de interp2d et de ses proches est qu'il a un nom trompeur, et les gens sont susceptibles d'essayer de l'utiliser. Alerte Spoiler: ne l'utilisez pas (à partir de la version 0.17.0 de scipy). Il est déjà plus spécial que les sujets précédents en ce sens qu'il est spécifiquement utilisé pour les deux dimensions interpolation, mais je soupçonne que c'est de loin le cas le plus commun pour l'interpolation multivariée.
En ce qui concerne la syntaxe, interp2d est similaire à Rbf en ce sens qu'il faut d'abord construire une instance d'interpolation, qui peut être appelée pour fournir les valeurs interpolées réelles. Il y a un hic, cependant: les points de sortie doivent être situés sur un maillage rectangulaire, donc les entrées entrant dans l'appel à l'interpolateur doivent être des vecteurs 1d qui couvrent la grille de sortie, comme si de numpy.meshgrid:
# reminder: x_sparse and y_sparse are of shape [6, 7] from numpy.meshgrid
zfun_smooth_interp2d = interp.interp2d(x_sparse, y_sparse, z_sparse_smooth, kind='cubic') # default kind is 'linear'
# reminder: x_dense and y_dense are of shape [20, 21] from numpy.meshgrid
xvec = x_dense[0,:] # 1d array of unique x values, 20 elements
yvec = y_dense[:,0] # 1d array of unique y values, 21 elements
z_dense_smooth_interp2d = zfun_smooth_interp2d(xvec,yvec) # output is [20, 21]-shaped array
L'une des erreurs les plus courantes lors de l'utilisation de interp2d est de mettre vos maillages 2d complets dans l'appel d'interpolation, ce qui entraîne une consommation de mémoire explosive, et, espérons-le, Un MemoryError hâtif.
Maintenant, le plus grand problème avec interp2d est que cela ne fonctionne souvent pas. Pour comprendre cela, nous devons regarder sous le capot. Il s'avère que interp2d est un wrapper pour le bas niveau des fonctions bisplrep+bisplev, qui sont à leur tour des wrappers pour les routines FITPACK (écrites en Fortran). L'appel équivalent à l'exemple précédent serait
kind = 'cubic'
if kind=='linear':
kx=ky=1
elif kind=='cubic':
kx=ky=3
elif kind=='quintic':
kx=ky=5
# bisplrep constructs a spline representation, bisplev evaluates the spline at given points
bisp_smooth = interp.bisplrep(x_sparse.ravel(),y_sparse.ravel(),z_sparse_smooth.ravel(),kx=kx,ky=ky,s=0)
z_dense_smooth_bisplrep = interp.bisplev(xvec,yvec,bisp_smooth).T # note the transpose
Maintenant, voici la chose à propos de interp2d: (dans la version scipy 0.17.0) il y a un bon commentaire dans interpolate/interpolate.py pour interp2d:
if not rectangular_grid:
# TODO: surfit is really not meant for interpolation!
self.tck = fitpack.bisplrep(x, y, z, kx=kx, ky=ky, s=0.0)
Et en effet dans interpolate/fitpack.py, dans bisplrep Il y a une configuration et finalement
tx, ty, c, o = _fitpack._surfit(x, y, z, w, xb, xe, yb, ye, kx, ky,
task, s, eps, tx, ty, nxest, nyest,
wrk, lwrk1, lwrk2)
Et c'est tout. Les routines sous-jacentes à interp2d ne sont pas vraiment destinées à effectuer une interpolation. Ils pourraient suffire pour des données suffisamment bien comportées, mais dans des circonstances réalistes, vous voudrez probablement utiliser autre chose.
Juste pour conclure, interpolate.interp2d
- peut conduire à des artefacts même avec des données bien tempérées
- est spécifiquement pour les problèmes bivariés (bien qu'il y ait le
interpnlimité pour les points d'entrée définis sur une grille) - effectue une extrapolation
- crée un interpolateur comme première étape, donc l'évaluer dans divers points de sortie est moins d'effort supplémentaire
- peut seulement produire une sortie sur une grille rectangulaire, pour une sortie dispersée, vous devez appeler l'interpolateur dans une boucle
- supporte l'interpolation linéaire, cubique et quintique
- pourrait violer la symétrie des données d'entrée
1je suis assez certain que les cubic et linear type de fonctions de base de Rbf ne correspondent pas exactement aux autres interpolateurs du même nom.
2Ces NaNs sont également la raison pour laquelle la surface l'intrigue semble si étrange: matplotlib a historiquement des difficultés à tracer des objets 3D complexes avec des informations de profondeur appropriées. Les valeurs NaN dans les données confondent le moteur de rendu, de sorte que les parties de la surface qui doivent être à l'arrière sont tracées pour être à l'avant. Il s'agit d'un problème de visualisation et non d'interpolation.