Comment puis-je optimiser davantage une requête de table dérivée qui fonctionne mieux que l'équivalent joint?
Mise à jour: j'ai trouvé une solution. Voir ma réponse ci-dessous.
Ma Question
Comment puis-je optimiser cette requête pour minimiser mon temps d'arrêt? Je dois mettre à jour plus de 50 schémas avec le nombre de billets allant de 100 000 à 2 millions. Est-il conseillé d'essayer de définir tous les champs dans tickets_extra en même temps? Je pense qu'il y a une solution ici que je ne vois tout simplement pas. Je me suis cogné la tête contre ce problème pendant plus d'une journée.
Aussi, j'ai d'abord essayé sans utiliser de sous-sélection, mais la performance était beaucoup pire que ce que j'ai actuellement.
Contexte
J'essaie d'optimiser ma base de données pour un rapport qui doit être exécuté. Les champs sur lesquels je dois agréger sont très coûteux à calculer, donc je dénormalise monschéma existant un peu pour accommoder ce rapport. Notez que j'ai simplifié un peu la table des tickets en supprimant quelques dizaines de colonnes non pertinentes.
Mon rapport sera agrégé billet compte par Gestionnaire Lors de la création et Manager Lorsque Résolu. Cette relation compliquée est schématisée ici:
EAV http://cdn.cloudfiles.mosso.com/c163801/eav.png
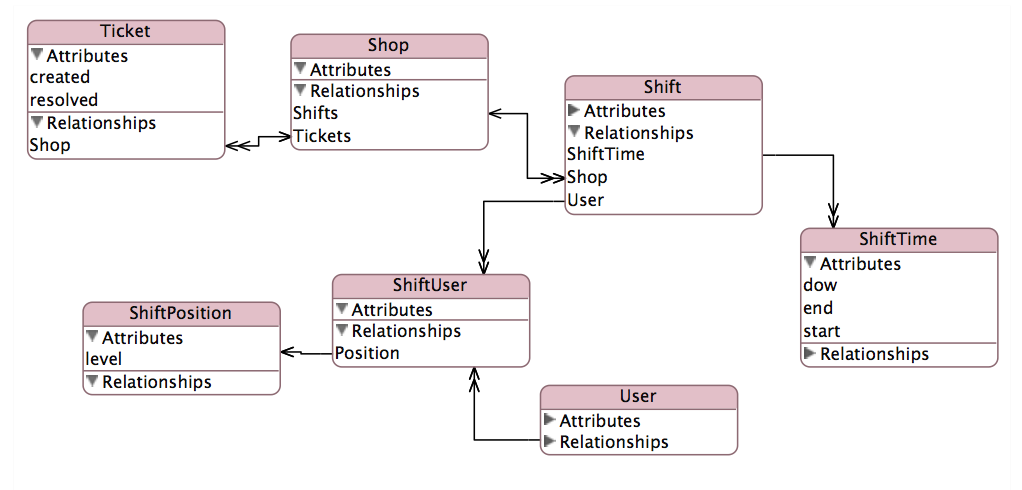{kind=link}
Pour éviter la demi-douzaine de jointures méchantes nécessaires pour calculer cela à la volée, j'ai ajouté le tableau suivant à mon schéma:
mysql> show create table tickets_extraG
*************************** 1. row ***************************
Table: tickets_extra
Create Table: CREATE TABLE `tickets_extra` (
`ticket_id` int(11) NOT NULL,
`manager_created` int(11) DEFAULT NULL,
`manager_resolved` int(11) DEFAULT NULL,
PRIMARY KEY (`ticket_id`),
KEY `manager_created` (`manager_created`,`manager_resolved`),
KEY `manager_resolved` (`manager_resolved`,`manager_created`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
Le problème maintenant est que je n'ai pas stocké ces données n'importe où. Le gestionnaire a toujours été calculé dynamiquement. J'ai millions de tickets à travers plusieurs bases de données avec le même schéma qui doivent avoir cette table remplie. Je veux le faire de la manière la plus efficace possible, mais j'ai échoué à optimiser les requêtes que j'utilise pour le faire:
INSERT INTO tickets_extra (ticket_id, manager_created)
SELECT
t.id,
su.user_id
FROM (
SELECT
t.id,
shift_times.shift_id AS shift_id
FROM tickets t
JOIN shifts ON t.shop_id = shifts.shop_id
JOIN shift_times ON (shifts.id = shift_times.shift_id
AND shift_times.dow = DAYOFWEEK(t.created)
AND TIME(t.created) BETWEEN shift_times.start AND shift_times.end)
) t
LEFT JOIN shifts_users su ON t.shift_id = su.shift_id
LEFT JOIN shift_positions ON su.shift_position_id = shift_positions.id
WHERE shift_positions.level = 1
Cette requête prend plus d'une heure pour s'exécuter sur un schéma a > 1,7 millions de billets. C'est inacceptable pour la fenêtre de maintenance que j'ai. En outre, il ne gère même pas le calcul du champ manager_resolved, en essayant de le combiner dans la même requête pousse le temps de requête dans la stratosphère. Mon inclination actuelle est de les garder séparés, et d'utiliser une mise à jour pour remplir le champ manager_resolved, mais je ne suis pas sûr.
Enfin, voici la sortie EXPLAIN de la partie SELECT de cette requête:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 167661
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: su
type: ref
possible_keys: shift_id_fk_idx,shift_position_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: t.shift_id
rows: 5
Extra: Using where
*************************** 3. row ***************************
id: 1
select_type: PRIMARY
table: shift_positions
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 6
Extra: Using where; Using join buffer
*************************** 4. row ***************************
id: 2
select_type: DERIVED
table: t
type: ALL
possible_keys: fk_tickets_shop_id
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 5. row ***************************
id: 2
select_type: DERIVED
table: shifts
type: ref
possible_keys: PRIMARY,shop_id_fk_idx
key: shop_id_fk_idx
key_len: 4
ref: dev_acmc.t.shop_id
rows: 1
Extra:
*************************** 6. row ***************************
id: 2
select_type: DERIVED
table: shift_times
type: ref
possible_keys: shift_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: dev_acmc.shifts.id
rows: 4
Extra: Using where
6 rows in set (6.30 sec)
Merci beaucoup pour la lecture!
4 réponses
Eh bien, j'ai trouvé une solution. Il a fallu beaucoup d'expérimentation, et je pense qu'un bon peu de chance aveugle, mais le voici:
CREATE TABLE magic ENGINE=MEMORY
SELECT
s.shop_id AS shop_id,
s.id AS shift_id,
st.dow AS dow,
st.start AS start,
st.end AS end,
su.user_id AS manager_id
FROM shifts s
JOIN shift_times st ON s.id = st.shift_id
JOIN shifts_users su ON s.id = su.shift_id
JOIN shift_positions sp ON su.shift_position_id = sp.id AND sp.level = 1
ALTER TABLE magic ADD INDEX (shop_id, dow);
CREATE TABLE tickets_extra ENGINE=MyISAM
SELECT
t.id AS ticket_id,
(
SELECT m.manager_id
FROM magic m
WHERE DAYOFWEEK(t.created) = m.dow
AND TIME(t.created) BETWEEN m.start AND m.end
AND m.shop_id = t.shop_id
) AS manager_created,
(
SELECT m.manager_id
FROM magic m
WHERE DAYOFWEEK(t.resolved) = m.dow
AND TIME(t.resolved) BETWEEN m.start AND m.end
AND m.shop_id = t.shop_id
) AS manager_resolved
FROM tickets t;
DROP TABLE magic;
Longue Explication
Maintenant, je vais vous expliquer pourquoi cela fonctionne, et mon processus relatif et les étapes pour arriver ici.
Tout d'abord, je savais que la requête que j'essayais souffrait à cause de l'énorme table dérivée, et les jointures ultérieures sur ceci. Je prenais ma table de tickets bien indexée et je joignais toutes les données shift_times, puis je laissais MySQL mâche cela pendant qu'il tente de rejoindre la table shifts et shift_positions. Ce mastodonte dérivé serait jusqu'à un désordre non indexé de 2 millions de lignes.
Maintenant, je savais que cela se produisait. La raison pour laquelle j'allais dans cette voie était que la façon "correcte" de le faire, en utilisant strictement les jointures, prenait encore plus de temps. Cela est dû au peu méchant de chaos nécessaire pour déterminer qui est le gestionnaire d'un quart de travail donné. Je dois rejoindre shift_times pour savoir ce que le le décalage correct est même, tout en se joignant simultanément à shift_positions pour comprendre le niveau de l'utilisateur. Je ne pense pas que L'optimiseur MySQL gère très bien cela, et finit par créer une énorme monstruosité d'une table temporaire des jointures, puis filtrer ce qui ne s'applique pas.
Donc, comme la table dérivée semblait être la "voie à suivre", j'ai obstinément persisté pendant un moment. J'ai essayé de le lancer dans une clause de jointure, aucune amélioration. J'ai essayé de créer une table temporaire avec le table dérivée, mais encore une fois c'était trop lent car la table temporaire n'était pas indexée.
Je me suis rendu compte que je devais gérer ce calcul de décalage, temps, positions sanely. Je pensais, peut-être une vue serait la voie à suivre. Que faire si j'ai créé une vue contenant ces informations: (shop_id, shift_id, dow, start, end, manager_id). Ensuite, je devrais simplement rejoindre la table des tickets par shop_id et tout le calcul DAYOFWEEK/TIME, et je serais en affaires. Bien sûr, je n'ai pas réussi à rappelez-vous que MySQL gère les vues plutôt assily. Il ne les matérialise pas du tout, il exécute simplement la requête que vous auriez utilisée pour obtenir la vue pour vous. Donc, en joignant des tickets à cela, j'exécutais essentiellement ma requête originale-aucune amélioration.
Donc, au lieu d'une vue, j'ai décidé d'utiliser une TABLE temporaire. Cela a bien fonctionné si Je ne récupérais qu'un des gestionnaires (créés ou résolus) à la fois, mais c'était encore assez lent. En outre, j'ai découvert qu'avec MySQL vous ne pouvez pas vous référer à la même chose table deux fois dans la même requête (je devrais rejoindre ma table temporaire deux fois pour pouvoir différencier manager_created et manager_resolved). C'est un grand WTF, car je peux le faire tant que je ne spécifie pas "temporaire" - c'est là que le CREATE TABLE Magic ENGINE=MEMORY est entré en jeu.
Avec cette table pseudo temporaire en main, j'ai essayé ma JOIN for just manager_created à nouveau. Il a bien fonctionné, mais encore assez lent. Pourtant, quand je me suis joint à nouveau pour obtenir manager_resolved dans le même requête le temps de requête coché dans la stratosphère. En regardant L'explication a montré l'analyse complète de la table des tickets (lignes ~2mln), comme prévu, et les jointures sur la table magique à ~2,087 chacun. Encore une fois, je semblais courir en échec.
J'ai maintenant commencé à réfléchir à la façon d'éviter complètement les jointures et c'est à ce moment-là que j'ai trouvé un ancien message obscur où quelqu'un a suggéré d'utiliser des sous-sélections (Je ne trouve pas le lien dans mon histoire). C'est ce qui a conduit à la deuxième requête SELECT montré ci-dessus (la création tickets_extra un). Dans le cas de la sélection d'un seul champ de gestionnaire, il a bien fonctionné, mais encore une fois avec les deux c'était de la merde. J'ai regardé L'explication et j'ai vu ceci:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: t
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 2. row ***************************
id: 3
select_type: DEPENDENT SUBQUERY
table: m
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2037
Extra: Using where
*************************** 3. row ***************************
id: 2
select_type: DEPENDENT SUBQUERY
table: m
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 2037
Extra: Using where
3 rows in set (0.00 sec)
Ack, la sous-requête dépendante redoutée. Il est souvent suggéré de les éviter, car MySQL Les exécutera généralement de manière externe, en exécutant la requête interne pour chaque ligne de l'externe. J'ai ignoré cela, et je me suis demandé: "Eh bien... et si j'indexais cette stupide table magique?". Ainsi, l' Ajouter index (shop_id, dow) est né.
Vérifiez ceci:
mysql> CREATE TABLE magic ENGINE=MEMORY
<snip>
Query OK, 3220 rows affected (0.40 sec)
mysql> ALTER TABLE magic ADD INDEX (shop_id, dow);
Query OK, 3220 rows affected (0.02 sec)
mysql> CREATE TABLE tickets_extra ENGINE=MyISAM
<snip>
Query OK, 1933769 rows affected (24.18 sec)
mysql> drop table magic;
Query OK, 0 rows affected (0.00 sec)
Maintenant C'est de quoi je parle!
Conclusion
C'est certainement la première fois que j'ai créé une table non temporaire à la volée, et que je L'ai indexée à la volée, simplement pour faire une seule requête efficacement. Je suppose que j'ai toujours supposé que l'ajout d'un index à la volée est une opération prohibitive. (L'ajout d'un index sur ma table de tickets de lignes 2mln peut prendre plus d'une heure). Pourtant, pour une simple 3 000 lignes c'est une promenade.
N'ayez pas peur des sous-requêtes dépendantes, de la création de tables temporaires qui ne le sont vraiment pas, de l'indexation à la volée ou des extraterrestres. Ils peuvent tous être de bonnes choses dans la bonne situation.
Merci pour toute L'aide StackOverflow. :- D
Vous auriez dû utiliser Postgres, lol. Une requête simple comme celle-ci ne devrait pas prendre plus de quelques dizaines de secondes à condition que vous ayez suffisamment de RAM pour éviter les battements de disque.
Bref.
=> le problème est-il dans la sélection ou L'insertion ?
(exécutez la sélection seule sur un serveur de test et chronométrez-la).
= > votre disque de requête est-il lié ou lié au processeur ?
Lancez-le sur un serveur de test et vérifiez la sortie vmstat. Si elle est liée au processeur, ignorez ceci. S'il est lié au disque, vérifiez le fonctionnement taille de l'ensemble (c'est à dire la taille de votre base de données). Si l'ensemble de travail est plus petit que votre RAM, il ne doit pas être lié au disque. Vous pouvez forcer le chargement d'une table dans le cache du système d'exploitation avant d'exécuter une requête en lançant une sélection factice comme Select sum( some column ) FROM table. Cela peut être utile si une requête sélectionne plusieurs lignes dans un ordre aléatoire à partir d'une table qui n'est pas mise en cache dans la RAM... vous déclenchez une analyse séquentielle de la table, qui la charge dans le cache, puis l'accès aléatoire est beaucoup plus rapide. Avec un peu de ruse vous peut également mettre en cache des index (ou simplement tar votre répertoire de base de données à >/dev/null, lol).
Bien sûr, ajouter plus de RAM pourrait aider (mais vous devez vérifier si la requête tue le disque ou le CPU en premier). Ou dire à MySQL d'utiliser plus de votre RAM dans la configuration (key_buffer, etc.).
Si vous faites des millions de HDD aléatoire cherche Vous êtes dans la douleur.
=> OK maintenant la requête
Tout d'abord, analysez vos tables.
LEFT JOIN SHIFT_POSITIONS ON la ligue.shift_position_id = shift_positions.id Où shift_positions.niveau = 1
Pourquoi avez-vous quitté JOIN puis ajoutez un WHERE dessus ? La GAUCHE n'a pas de sens. S'il n'y a pas de ligne dans shift_positions, LEFT JOIN générera une valeur NULL et WHERE la rejettera.
Solution: utilisez JOIN au lieu de LEFT JOIN and move (level=1) dans la condition JOIN ON ().
Pendant que vous y êtes, débarrassez-vous également de L'autre JOIN LEFT (remplacer par JOIN) sauf si vous êtes vraiment intéressé par tous les valeurs Null ? (Je suppose que vous n'êtes pas).
Maintenant, vous pouvez probablement vous débarrasser de la sous-sélection.
Suivant.
Où le temps (t. créé) entre shift_times.démarrer et shift_times.fin)
Ce n'est pas indexable, car vous avez une fonction TIME () dans la condition (utilisez Postgres, lol). Regardons-le:
Rejoindre shift_times sur (shifts.id = shift_times.shift_id Et shift_times.dow = DAYOFWEEK(t.créé) ET le TEMPS(t.créé) ENTRE shift_times.démarrer et shift_times.fin)
Idéalement, vous aimeriez avoir un index multicolumn sur shift_times(shift_id, DAYOFWEEK(T. created),TIME (t. created)) afin que cette jointure puisse être indexée.
Solution: ajouter des colonnes 'day',' time ' à shift_times, contenant DAYOFWEEK (T. created), TIME (t. created), remplies de valeurs correctes à l'aide d'un déclencheur lors de L'insertion ou de la mise à jour.
Maintenant créer des index multicolonne sur (shift_id,jour,heure)
Cela vous permettra d'avoir un accès en lecture seule pour la durée des modifications:
create table_new (new schema);
insert into table_new select * from table order by primary_key_column;
rename table to table_old;
rename table_new to table;
-- recreate triggers if necessary
Lors de l'insertion de données dans des tables InnoDB, il est crucial de le faire dans l'ordre de la clé primaire (sinon, avec de grands ensembles de données, il est plus lent de quelques ordres de grandeur).
Environ entre
SELECT * FROM a WHERE a.column BETWEEN x AND y
- est indexable et correspond à une recherche de plage sur l'index A. column (si vous en avez un)
- est 100% équivalent à
a.column >= x AND a.column <= y
Alors que ceci:
SELECT * FROM a WHERE somevalue BETWEEN a.column1 AND a.column2
- est 100% équivalent à
somevalue >= a.column1 AND somevalue <= a.column2 - est une chose très différente de la première ci-dessus
- n'est pas indexable par une recherche de plage (il n'y a pas de plage, vous avez 2 colonnes ici)
- conduit généralement à des performances de requête horribles
Je pense qu'il y avait confusion à ce sujet dans le débat sur "entre" ci-dessus.
OP a le premier type, donc pas de souci.