HashMap mise en œuvre en Java. Comment fonctionne le calcul de l'indice bucket?
4 réponses
ce n'est pas calculer le hash, il calcule le seau.
h & (length-1) est-un peu-sage ANDh en utilisant length-1, qui est comme un masque de bits, pour retourner Seulement les bits deh, faisant ainsi une variante super-rapide de h % length.
le hash lui-même est calculé par le hashCode() méthode de l'objet que vous essayez de magasin.
ce que vous voyez ici est le calcul du "seau" pour stocker l'objet basé sur le hash h. Idéalement, pour éviter les collisions, vous auriez le même nombre de seaux que la valeur maximale réalisable de
Si h est dire, 1000, mais vous avez seulement 512 seaux dans votre sous-jacente de tableau, vous devez savoir où placer l'objet. Généralement, un mod opération h serait suffisant, mais c'est trop lent. Compte tenu de la propriété interne de HashMap sous-jacent tableau toujours a un nombre de seaux égal à 2^n, les ingénieurs du Soleil pourraient utiliser l'idée de h & (length-1), une bit à bit ET avec un nombre composé de tous 1's, lit pratiquement seulement le n plus bas les bits de la table de hachage (qui est le même que le fait de faire h mod 2^n, seulement beaucoup le plus rapide).
Exemple:
hash h: 11 1110 1000 -- (1000 in decimal)
length l: 10 0000 0000 -- ( 512 in decimal)
(l-1): 01 1111 1111 -- ( 511 in decimal - it will always be all ONEs)
h AND (l-1): 01 1110 1000 -- ( 488 in decimal which is a result of 1000 mod 512)
il s'agit de calculer le seau de la carte de hachage où l'entrée (paire clé-valeur) sera stockée. L'ID du seau est hashvalue/buckets length.
une carte de hachage se compose de seaux; les objets seront placés dans ces seaux en fonction de l'id du seau.
n'Importe quel nombre d'objets peuvent tomber dans le même compartiment basé sur leur hash code / buckets length valeur. Cela s'appelle une "collision".
si beaucoup d'objets tombent dans le même seau, lors de la recherche de leurs égaux () la méthode sera appelée à lever l'ambiguïté.
le nombre de collisions est indirectement proportionnel à la longueur du godet.
La réponse ci-dessus est très bonne, mais je tiens à expliquer pourquoi Java peut utiliser indexFor pour créer l'index
Exemple, j'ai un HashMap comme ceci (ce test est sur Java7, je vois Java8 changement HashMap beaucoup, mais je pense que cette logique du toujours très bon)
// Default length of "budget" (table.length) after create is 16 (HashMap#DEFAULT_INITIAL_CAPACITY)
HashMap<String, Integer> hashMap = new HashMap<>();
hashMap.put("A",1); // hash("A")=69, indexFor(hash,table.length)=69&(16-1) = 5
hashMap.put("B",2); // hash("B")=70, indexFor(hash,table.length)=70&(16-1) = 6
hashMap.put("P",3); // hash("P")=85, indexFor(hash,table.length)=85&(16-1) = 5
hashMap.put("A",4); // hash("A")=69, indexFor(hash,table.length)=69&(16-1) = 5
hashMap.put("r", 4);// hash("r")=117, indexFor(hash,table.length)=117&(16-1) = 5
vous pouvez voir l'index d'entrée avec la touche "A" et l'objet avec la touche "P" et l'objet avec la touche "r" ont le même indice ( = 5). Et voici le résultat du débogage après avoir exécuté le code ci-dessus
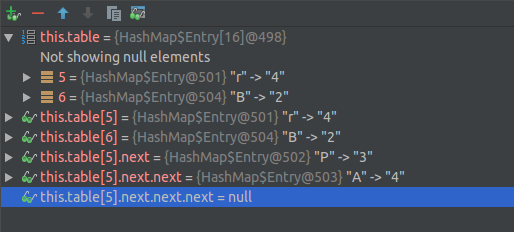
Tableau de l'image est ici
public class HashMap<K, V> extends AbstractMap<K, V> implements Map<K, V>, Cloneable, Serializable {
transient HashMap.Entry<K, V>[] table;
...
}
=> je vois
Si les indices sont , une nouvelle entrée sera ajouter à la table
Si l'indice est et hash, la nouvelle valeur sera mise à jour
Si l'indice est et hash, une nouvelle entrée sera point à l'ancienne entrée (comme LinkedList). Alors, vous savez pourquoi Map.Entry champ next
static class Entry<K, V> implements java.util.Map.Entry<K, V> {
...
HashMap.Entry<K, V> next;
}
Vous pouvez vérifier à nouveau par lire le code dans HashMap.
maintenant, vous pouvez penser que HashMapjamais besoin de changer la taille (16) parce que indexFor() toujours retourner la valeur < = 15 mais elle correct.
Si vous regardez HashMap code
if (this.size >= this.threshold ...) {
this.resize(2 * this.table.length);
HashMap va redimensionner la table (double longueur de la table) quand size > = threadhold
qu'est-Ce que threadhold? threadhold est calculé ci-dessous
static final int DEFAULT_INITIAL_CAPACITY = 16;
static final float DEFAULT_LOAD_FACTOR = 0.75F;
...
this.threshold = (int)Math.min((float)capacity * this.loadFactor, 1.07374182E9F); // if capacity(table.length) = 16 => threadhold = 12
qu'est-Ce que le size? size est calculé ci-dessous.
Bien sûr, size ici n'est pastable.length .
Chaque fois que vous mettez la nouvelle entrée à HashMap et HashMap besoin de créer une nouvelle entrée (notez que HashMap ne créez pas de nouvelle entrée lorsque la clé est la même, elle remplace simplement la nouvelle valeur pour l'entrée existée) puis size++
void createEntry(int hash, K key, V value, int bucketIndex) {
...
++this.size;
}
j'Espère il aide