Hadoop entrée split size vs taille de bloc
je passe en revue hadoop guide définitif, où il explique clairement sur les divisions d'entrée. Il va comme
les séparations D'entrée ne contiennent pas les données réelles, mais plutôt le stockage les emplacements de données sur HDFS
et
habituellement, la taille de la division D'entrée est la même que la taille du bloc
1) disons qu'un bloc de 64 Mo est sur le noeud A et répliqué parmi 2 autres noeuds(B,C), et la taille de division d'entrée pour le programme map-reduce est de 64 Mo, est-ce que cette division aura juste l'emplacement pour le noeud A? Ou aura-t-il des emplacements pour les trois noeuds A,b,C?
2) puisque les données sont locales à tous les trois noeuds comment le framework décide (sélectionne) un maptask à exécuter sur un noeud particulier?
3) comment est-il traité si la taille de la Division D'entrée est supérieure ou inférieure à la taille du bloc?
7 réponses
La réponse par @user1668782 est une bonne explication pour la question et je vais essayer de donner une représentation graphique.
Supposons que nous avons un fichier de 400MB avec se compose de 4 notices (e.g: fichier csv de 400 Mo et il a 4 lignes, 100 Mo chacun)
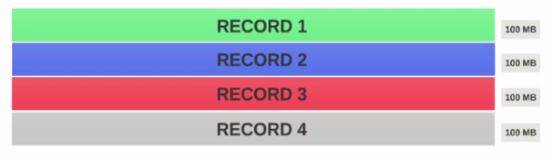
- si le HDFS Taille Du Bloc est configuré 128MB, alors les 4 disques ne seront pas distribués uniformément parmi les blocs. Il ressemble à ceci.
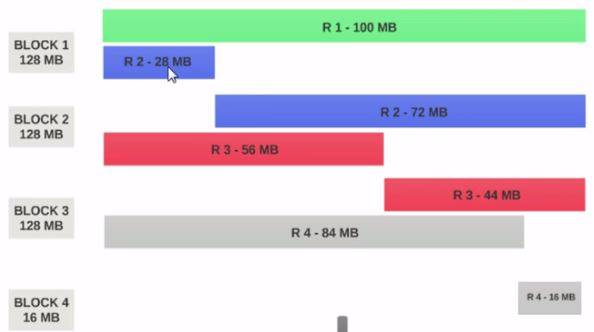
- Bloc 1 contient la totalité du premier disque et un morceau de 28 Mo du second disque.
- Si un mappeur est à exécuter sur Bloc 1, le mapper ne peut pas traiter car il n'aura pas tout le second disque.
C'est le problème exact que entrée divise résoudre. Entrée divise respecte les limites logiques des enregistrements.
supposons le entrée split taille 200 MO
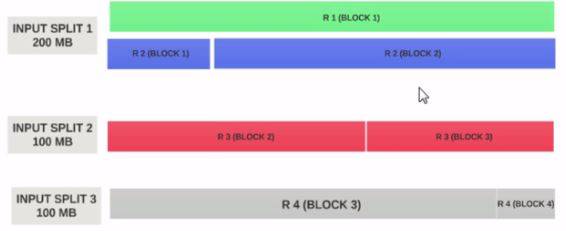
D'où le entrée split 1 devrait avoir à la fois le dossier 1 et dossier 2. Et la division d'entrée 2 ne commencera pas avec l'enregistrement 2 puisque l'enregistrement 2 a été assigné à la division d'entrée 1. L'entrée split 2 commencera avec l'enregistrement 3.
C'est pourquoi un split input n'est qu'un logique morceau de données. Il indique les emplacements de départ et de fin avec dans les blocs.
J'espère que cela vous aidera.
Bloc est la représentation physique des données. Split est la représentation logique des données présentes dans le Bloc.
la taille du bloc et du split peut être changée dans les propriétés.
Map lit les données à partir du bloc jusqu'aux séparations, c'est-à-dire que split agit comme un courtier entre le bloc et Mapper.
tenir compte de deux blocs:
Bloc 1
aa BB cc dd ee ff GG HH ii jj
Bloc 2
ww ee aa uu oo ii oo pp kk ll nn
maintenant la carte lit le bloc 1 jusqu'à aa à JJ et ne sait pas comment lire le bloc 2 c'est-à-dire que le bloc ne sait pas comment traiter les différents blocs d'information. Ici vient une division il formera un groupement logique de bloc 1 et bloc 2 comme Bloc simple, puis il forme l'offset (Clé) et la ligne (valeur) en utilisant inputformat et lecteur d'enregistrement et envoyer la carte pour traiter le traitement ultérieur.
Si votre ressource est limitée et que vous souhaitez limiter le nombre de cartes que vous pouvez augmenter la taille du segment. Exemple: Si nous avons 640 Mo de 10 blocs c.-à-d. chaque bloc de 64 Mo et la ressource est limitée alors vous pouvez mentionner la taille de division comme 128 Mo puis le groupement logique de 128 Mo est formé et seulement 5 cartes seront exécutées avec une taille de 128 Mo.
si nous spécifions que la taille de split est fausse, alors le fichier entier formera une split input et sera traité par une map qu'il faudra plus de temps pour traiter quand le fichier est gros.
les séparations D'entrée sont une division logique de vos enregistrements tandis que les blocs HDFS sont une division physique des données d'entrée. Il est extrêmement efficace quand ils sont les mêmes, mais dans la pratique, il n'est jamais parfaitement alignées. Les documents peuvent franchir les limites des blocs. Hadoop garantit le traitement de tous les enregistrements . Une machine qui traite une fente particulière peut récupérer un fragment d'enregistrement d'un bloc autre que son bloc "principal" et qui peut résider à distance. Le coût de la communication pour récupérer un document fragment est sans conséquence car il se produit relativement rarement.
à 1) et 2): Je ne suis pas sûr à 100%, mais si la tâche ne peut pas être accomplie - pour quelque raison que ce soit, y compris si quelque chose ne va pas avec le split input - alors il est terminé et un autre a commencé à son endroit: donc chaque maptask obtient exactement un split avec des informations de fichier (vous pouvez rapidement dire si c'est le cas en déboguant contre un cluster local pour voir quelles informations sont conservées dans l'objet input split: je semble me rappeler que c'est juste un emplacement).
à 3): si le format de fichier est splittable, alors Hadoop tentera de couper le fichier en morceaux de taille "inputSplit"; sinon, c'est une tâche par fichier, quelle que soit la taille du fichier. Si vous changez la valeur de minimum-input-split, alors vous pouvez empêcher qu'il y ait trop de tâches mapper qui sont générées si chacun de vos fichiers input est divisé en taille de bloc, mais vous ne pouvez que combiner entrées si vous faites un peu de magie avec la classe combiner (je pense que c'est ce que ça s'appelle).
Hadoop framework strength is its data locality.Ainsi, chaque fois qu'un client demande les données hdfs, framework vérifie toujours la localisation, sinon il cherche peu d'utilisation des e/s.
les séparations D'entrée sont des unités de données logiques qui alimentent chaque mapper. Les données sont divisées entre les enregistrements valides. Les séparations d'entrées contiennent les adresses des blocs et des offsets d'octets.
disons que vous avez un fichier texte qui s'étend sur 4 blocs.
Fichier:
a b c d
e F g H
i j k L
m n O P
Blocs:
bloc1: a b c d e
bloc2: f g h i j
block3: k l m n o
block4: p
Fentes:
Split1: a b C d E F H
Split2: i j k l m n O P
observez que les séparations sont en ligne avec les limites (enregistrements) du fichier. Maintenant, chaque fraction est donnée à un éventreur.
si la taille du split de saisie est inférieure à la taille du bloc, vous finirez par utiliser plus de no.de mappeurs vice versa.
j'Espère qui permet de.
la taille du bloc HDFS est un nombre exact mais la taille de la division D'entrée est basée sur notre logique de données qui peut être un peu différent avec le nombre configuré