De bonnes façons de visualiser les données longitudinales catégoriques en R
[mise à Jour: bien que j'ai accepté une réponse, s'il vous plaît ajouter une autre réponse si vous avez des idées de visualisation supplémentaires (que ce soit en R ou dans une autre langue/programme). Les textes sur l'analyse des données catégoriques ne semblent pas en dire grand-chose sur la visualisation des données longitudinales, tandis que les textes sur l'analyse des données longitudinales ne semblent pas en dire grand-chose sur la visualisation des changements au sein du sujet au fil du temps dans l'appartenance à la catégorie. Avoir plus de réponses à cette question permettra de faire une meilleure ressource sur une question ça n'est pas très couvert dans les références standard.]
un collègue vient de me donner un ensemble de données catégoriques longitudinales à examiner et j'essaie de comprendre comment capturer l'aspect longitudinal dans une visualisation. Je poste ici, parce que j'aimerais le faire en R, mais s'il vous plaît, faites-moi savoir si cela a du sens de faire aussi du cross-post à du Cross-Validated, puisque le cross-posting est généralement déconseillé.
Rapide de fond: Les données de suivre les résultats scolaires de terme à terme pour les étudiants qui ont suivi un programme de conseil académique. Les données sont en format long et de cinq variables: "id", "cohorte", "terme", "debout", et "termGPA". Les deux premiers identifient l'étudiant et le terme dans lequel ils étaient dans le programme de conseil. Les trois derniers termes sont ceux qui correspondent à la Note académique de l'étudiant et à L'AMP. J'ai collé quelques données d'échantillon ci-dessous en utilisant dput.
j'ai créé un graphique en mosaïque (voir ci-dessous) qui regroupe les étudiants par cohorte, debout, et de la durée. Cela montre quelle fraction des étudiants étaient dans chaque catégorie académique dans chaque terme. Mais cela ne rend pas compte de l'aspect longitudinal, c'est-à-dire du fait que chaque élève est suivi au fil du temps. J'aimerais suivre le chemin que des groupes d'étudiants avec un niveau académique prendre plus de temps.
par exemple: parmi les étudiants ayant obtenu la mention "Pa" (probation académique) à L'automne 2009 ("F09"), quelle fraction était encore PA dans les Termes futurs, et quelle fraction s'est déplacée dans autres catégories (p. ex., GS, "bonne réputation")? Y a-t-il des différences entre les cohortes en ce qui concerne l'évolution entre les catégories depuis l'entrée dans le programme de conseil?
Je n'ai pas tout à fait réussi à saisir cet aspect longitudinal dans un graphique R. vcd paquet a des facilités pour visualiser les données catégoriques, mais ne semble pas adresser longitudinale données catégorielles. Existe-t-il des méthodes "standard" pour visualiser les données longitudinales catégoriques? R a-t-il des paquets conçus pour cela? Est long format approprié pour ce type de données ou serais-je mieux avec le grand format?
j'apprécierais des suggestions pour résoudre ce problème particulier et aussi des suggestions pour des articles, des livres, etc. pour en savoir plus sur la visualisation de données longitudinales catégoriques.
voici le code que j'ai utilisé pour faire le tracé de la mosaïque. Le code utilise les données listées ci-dessous avec dput.
library(RColorBrewer)
# create a table object for plotting
df1.tab = table(df1$cohort, df1$term, df1$standing,
dnn=c("CohortnAcademic Standing", "Term", "Standing"))
# create a mosaic plot
plot(df1.tab, las=1, dir=c("h","v","h"),
col=brewer.pal(8,"Dark2"),
main="Fall 2009 and Fall 2010 Cohorts")
voici le tracé de la mosaïque (question subsidiaire: y a-t-il un moyen de faire asseoir les colonnes de la cohorte F10 directement en dessous et d'avoir la même largeur que les colonnes de la cohorte F09, même s'il n'y a pas de données pour certains termes dans la cohorte F10?):
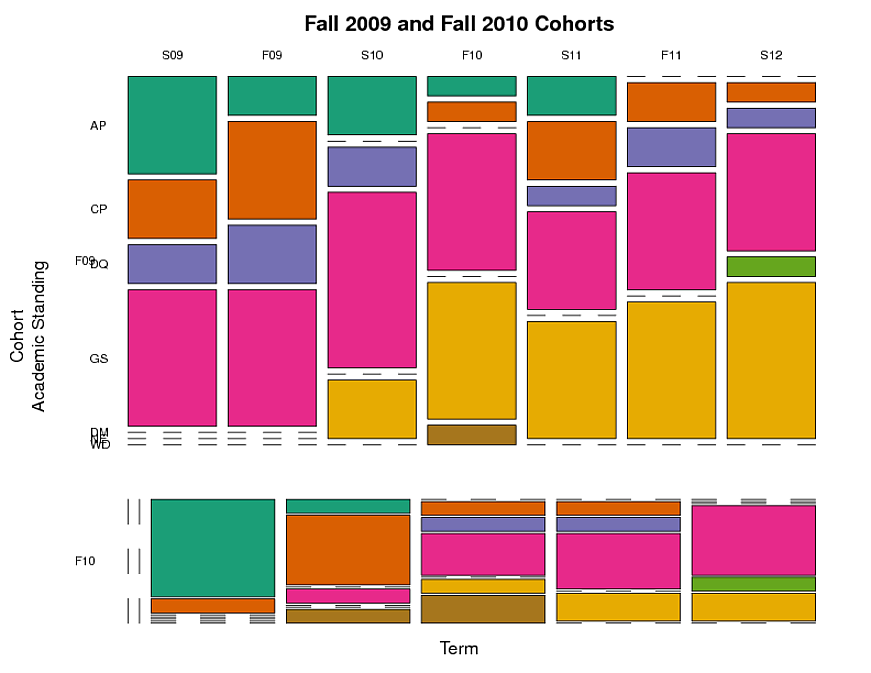
Et voici les données utilisées pour créer la table et de la parcelle:
df1 =
structure(list(id = c(101L, 102L, 103L, 104L, 105L, 106L, 107L,
108L, 109L, 110L, 111L, 112L, 113L, 114L, 115L, 116L, 117L, 118L,
119L, 120L, 121L, 122L, 123L, 124L, 125L, 101L, 102L, 103L, 104L,
105L, 106L, 107L, 108L, 109L, 110L, 111L, 112L, 113L, 114L, 115L,
116L, 117L, 118L, 119L, 120L, 121L, 122L, 123L, 124L, 125L, 101L,
102L, 103L, 104L, 105L, 106L, 107L, 108L, 109L, 110L, 111L, 112L,
113L, 114L, 115L, 116L, 117L, 118L, 119L, 120L, 121L, 122L, 123L,
124L, 125L, 101L, 102L, 103L, 104L, 105L, 106L, 107L, 108L, 109L,
110L, 111L, 112L, 113L, 114L, 115L, 116L, 117L, 118L, 119L, 120L,
121L, 122L, 123L, 124L, 125L, 101L, 102L, 103L, 104L, 105L, 106L,
107L, 108L, 109L, 110L, 111L, 112L, 113L, 114L, 115L, 116L, 117L,
118L, 119L, 120L, 121L, 122L, 123L, 124L, 125L, 101L, 102L, 103L,
104L, 105L, 106L, 107L, 108L, 109L, 110L, 111L, 112L, 113L, 114L,
115L, 116L, 117L, 118L, 119L, 120L, 121L, 122L, 123L, 124L, 125L,
101L, 102L, 103L, 104L, 105L, 106L, 107L, 108L, 109L, 110L, 111L,
112L, 113L, 114L, 115L, 116L, 117L, 118L, 119L, 120L, 121L, 122L,
123L, 124L, 125L), cohort = structure(c(1L, 1L, 1L, 1L, 2L, 1L,
1L, 2L, 2L, 2L, 2L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 1L, 1L,
1L, 1L, 2L, 1L, 1L, 1L, 1L, 2L, 1L, 1L, 2L, 2L, 2L, 2L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 2L, 2L, 1L, 1L, 1L, 1L, 2L, 1L, 1L, 1L, 1L,
2L, 1L, 1L, 2L, 2L, 2L, 2L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L,
1L, 1L, 1L, 1L, 2L, 1L, 1L, 1L, 1L, 2L, 1L, 1L, 2L, 2L, 2L, 2L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 1L, 1L, 1L, 1L, 2L, 1L, 1L,
1L, 1L, 2L, 1L, 1L, 2L, 2L, 2L, 2L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
2L, 2L, 1L, 1L, 1L, 1L, 2L, 1L, 1L, 1L, 1L, 2L, 1L, 1L, 2L, 2L,
2L, 2L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 1L, 1L, 1L, 1L, 2L,
1L, 1L, 1L, 1L, 2L, 1L, 1L, 2L, 2L, 2L, 2L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 2L, 2L, 1L, 1L, 1L, 1L, 2L), .Label = c("F09", "F10"), class = c("ordered",
"factor")), term = structure(c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 5L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L,
6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 7L, 7L,
7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L,
7L, 7L, 7L, 7L, 7L, 7L, 7L), .Label = c("S09", "F09", "S10",
"F10", "S11", "F11", "S12"), class = c("ordered", "factor")),
standing = structure(c(2L, 4L, 1L, 4L, NA, 4L, 1L, NA, NA,
NA, NA, 2L, 2L, 1L, 4L, 4L, 1L, 3L, NA, NA, 4L, 3L, 1L, 4L,
NA, 2L, 1L, 3L, 3L, NA, 1L, 2L, NA, NA, NA, NA, 2L, 4L, 3L,
4L, 4L, 4L, 2L, NA, NA, 4L, 2L, 4L, 4L, NA, 3L, 4L, 6L, 6L,
1L, 4L, 4L, 1L, 1L, 1L, 1L, 1L, 4L, 6L, 4L, 4L, 1L, 4L, 1L,
2L, 4L, 3L, 1L, 4L, 1L, 6L, 1L, 6L, 6L, 7L, 4L, 4L, 2L, 2L,
4L, 2L, 6L, 4L, 6L, 7L, 4L, 2L, 4L, 1L, 2L, 4L, 6L, 6L, 4L,
2L, 2L, 3L, 6L, 6L, 7L, 4L, 4L, 3L, 4L, 4L, 6L, 2L, 1L, 6L,
6L, 4L, 2L, 1L, 7L, 2L, 4L, 6L, 6L, 4L, 4L, 3L, 6L, 4L, 6L,
2L, 4L, 4L, 6L, 4L, 4L, 6L, 3L, 2L, 6L, 6L, 4L, 2L, 6L, 3L,
4L, 4L, 6L, 6L, 4L, 4L, 5L, 6L, 4L, 6L, 4L, 4L, 4L, 5L, 4L,
4L, 6L, 6L, 2L, 6L, 6L, 4L, 3L, 6L, 6L, 4L, 4L, 6L, 6L, 4L,
4L), .Label = c("AP", "CP", "DQ", "GS", "DM", "NE", "WD"), class = "factor"),
termGPA = c(1.433, 1.925, 1, 1.68, NA, 1.579, 1.233, NA,
NA, NA, NA, 2.009, 1.675, 0, 1.5, 1.86, 0.5, 0.94, NA, NA,
1.777, 1.1, 1.133, 1.675, NA, 2, 1.25, 1.66, 0, NA, 1.525,
2.25, NA, NA, NA, NA, 1.66, 2.325, 0, 2.308, 1.6, 1.825,
2.33, NA, NA, 2.65, 2.65, 2.85, 3.233, NA, 1.25, 1.575, NA,
NA, 1, 2.385, 3.133, 0, 0, 1.729, 1.075, 0, 4, NA, 2.74,
0, 1.369, 2.53, 0, 2.65, 2.75, 0, 0.333, 3.367, 1, NA, 0.1,
NA, NA, 1, 2.2, 2.18, 2.31, 1.75, 3.073, 0.7, NA, 1.425,
NA, 2.74, 2.9, 0.692, 2, 0.75, 1.675, 2.4, NA, NA, 3.829,
2.33, 2.3, 1.5, NA, NA, NA, 2.69, 1.52, 0.838, 2.35, 1.55,
NA, 1.35, 0.66, NA, NA, 1.35, 1.9, 1.04, NA, 1.464, 2.94,
NA, NA, 3.72, 2.867, 1.467, NA, 3.133, NA, 1, 2.458, 1.214,
NA, 3.325, 2.315, NA, 1, 2.233, NA, NA, 2.567, 1, NA, 0,
3.325, 2.077, NA, NA, 3.85, 2.718, 1.385, NA, 2.333, NA,
2.675, 1.267, 1.6, 1.388, 3.433, 0.838, NA, NA, 0, NA, NA,
2.6, 0, NA, NA, 1, 2.825, NA, NA, 3.838, 2.883)), .Names = c("id",
"cohort", "term", "standing", "termGPA"), row.names = c("101.F09.s09",
"102.F09.s09", "103.F09.s09", "104.F09.s09", "105.F10.s09", "106.F09.s09",
"107.F09.s09", "108.F10.s09", "109.F10.s09", "110.F10.s09", "111.F10.s09",
"112.F09.s09", "113.F09.s09", "114.F09.s09", "115.F09.s09", "116.F09.s09",
"117.F09.s09", "118.F09.s09", "119.F10.s09", "120.F10.s09", "121.F09.s09",
"122.F09.s09", "123.F09.s09", "124.F09.s09", "125.F10.s09", "101.F09.f09",
"102.F09.f09", "103.F09.f09", "104.F09.f09", "105.F10.f09", "106.F09.f09",
"107.F09.f09", "108.F10.f09", "109.F10.f09", "110.F10.f09", "111.F10.f09",
"112.F09.f09", "113.F09.f09", "114.F09.f09", "115.F09.f09", "116.F09.f09",
"117.F09.f09", "118.F09.f09", "119.F10.f09", "120.F10.f09", "121.F09.f09",
"122.F09.f09", "123.F09.f09", "124.F09.f09", "125.F10.f09", "101.F09.s10",
"102.F09.s10", "103.F09.s10", "104.F09.s10", "105.F10.s10", "106.F09.s10",
"107.F09.s10", "108.F10.s10", "109.F10.s10", "110.F10.s10", "111.F10.s10",
"112.F09.s10", "113.F09.s10", "114.F09.s10", "115.F09.s10", "116.F09.s10",
"117.F09.s10", "118.F09.s10", "119.F10.s10", "120.F10.s10", "121.F09.s10",
"122.F09.s10", "123.F09.s10", "124.F09.s10", "125.F10.s10", "101.F09.f10",
"102.F09.f10", "103.F09.f10", "104.F09.f10", "105.F10.f10", "106.F09.f10",
"107.F09.f10", "108.F10.f10", "109.F10.f10", "110.F10.f10", "111.F10.f10",
"112.F09.f10", "113.F09.f10", "114.F09.f10", "115.F09.f10", "116.F09.f10",
"117.F09.f10", "118.F09.f10", "119.F10.f10", "120.F10.f10", "121.F09.f10",
"122.F09.f10", "123.F09.f10", "124.F09.f10", "125.F10.f10", "101.F09.s11",
"102.F09.s11", "103.F09.s11", "104.F09.s11", "105.F10.s11", "106.F09.s11",
"107.F09.s11", "108.F10.s11", "109.F10.s11", "110.F10.s11", "111.F10.s11",
"112.F09.s11", "113.F09.s11", "114.F09.s11", "115.F09.s11", "116.F09.s11",
"117.F09.s11", "118.F09.s11", "119.F10.s11", "120.F10.s11", "121.F09.s11",
"122.F09.s11", "123.F09.s11", "124.F09.s11", "125.F10.s11", "101.F09.f11",
"102.F09.f11", "103.F09.f11", "104.F09.f11", "105.F10.f11", "106.F09.f11",
"107.F09.f11", "108.F10.f11", "109.F10.f11", "110.F10.f11", "111.F10.f11",
"112.F09.f11", "113.F09.f11", "114.F09.f11", "115.F09.f11", "116.F09.f11",
"117.F09.f11", "118.F09.f11", "119.F10.f11", "120.F10.f11", "121.F09.f11",
"122.F09.f11", "123.F09.f11", "124.F09.f11", "125.F10.f11", "101.F09.s12",
"102.F09.s12", "103.F09.s12", "104.F09.s12", "105.F10.s12", "106.F09.s12",
"107.F09.s12", "108.F10.s12", "109.F10.s12", "110.F10.s12", "111.F10.s12",
"112.F09.s12", "113.F09.s12", "114.F09.s12", "115.F09.s12", "116.F09.s12",
"117.F09.s12", "118.F09.s12", "119.F10.s12", "120.F10.s12", "121.F09.s12",
"122.F09.s12", "123.F09.s12", "124.F09.s12", "125.F10.s12"), reshapeLong = structure(list(
varying = list(c("s09as", "f09as", "s10as", "f10as", "s11as",
"f11as", "s12as"), c("s09termGPA", "f09termGPA", "s10termGPA",
"f10termGPA", "s11termGPA", "f11termGPA", "s12termGPA")),
v.names = c("standing", "termGPA"), idvar = c("id", "cohort"
), timevar = "term"), .Names = c("varying", "v.names", "idvar",
"timevar")), class = "data.frame")
3 réponses
voici quelques idées pour tracer vos données. J'ai utilisé ggplot2, et j'ai reformaté les données un peu par endroits.
Figure 1
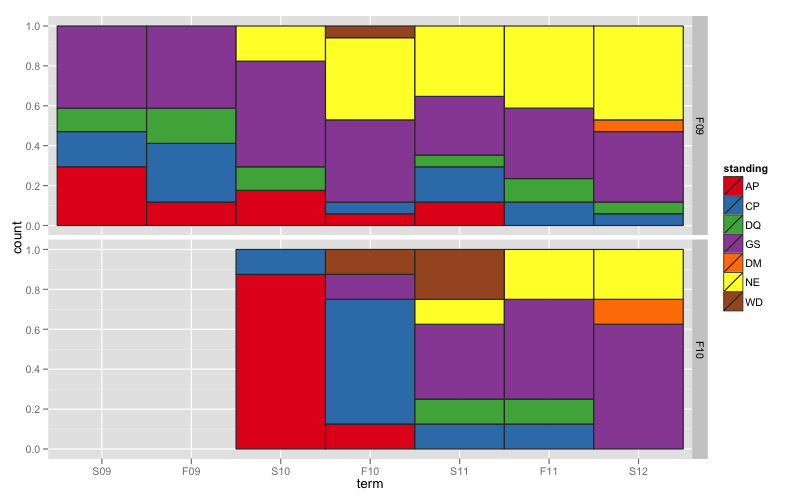 J'ai utilisé un barplot empilé pour imiter ta mosaïque et résoudre le problème d'alignement.
J'ai utilisé un barplot empilé pour imiter ta mosaïque et résoudre le problème d'alignement.
Figure 2
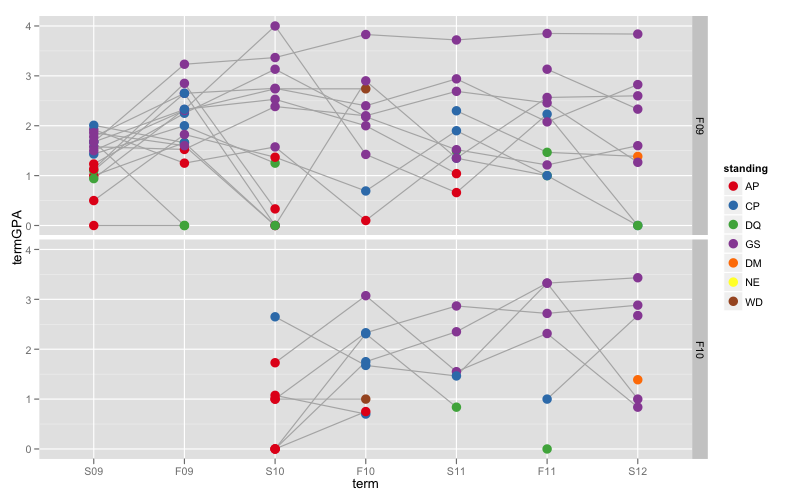 Les points de données de chaque élève sont reliés par une ligne grise, ce qui fait penser à un tracé de coordonnées parallèles. La coloration des points montre la position catégorique. L'utilisation de GPA sur l'axe des y permet d'étaler les points pour réduire les surcharges, et montre la corrélation de la position debout et GPA. Un problème majeur est que beaucoup de VALIDE
Les points de données de chaque élève sont reliés par une ligne grise, ce qui fait penser à un tracé de coordonnées parallèles. La coloration des points montre la position catégorique. L'utilisation de GPA sur l'axe des y permet d'étaler les points pour réduire les surcharges, et montre la corrélation de la position debout et GPA. Un problème majeur est que beaucoup de VALIDE standing les points de données sont exclus parce qu'ils n'ont pas de valeur termGPA correspondante.
Figure 3
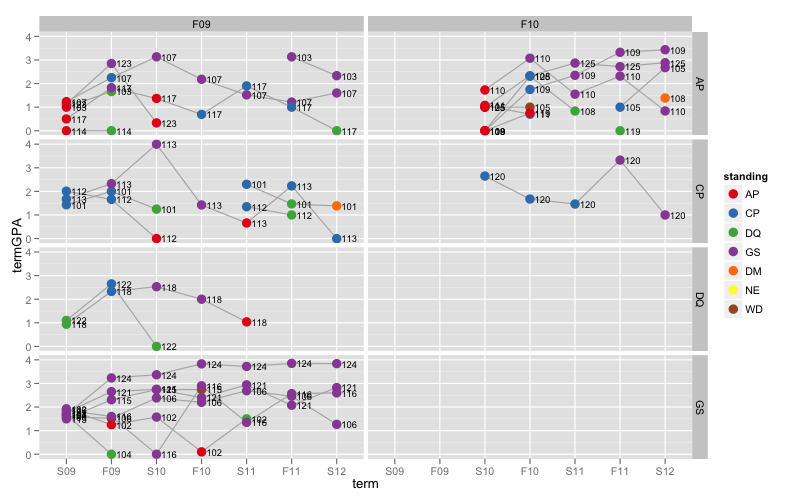 Ici, j'ai créé une nouvelle variable appelée initial_standing à utiliser pour facetting. Chaque panel contient des étudiants qui correspondent à la fois dans la cohorte et dans la compréhension initiale. Tracer l'id comme texte rend cette figure un peu encombré, mais pourrait être utile dans certains cas.
Ici, j'ai créé une nouvelle variable appelée initial_standing à utiliser pour facetting. Chaque panel contient des étudiants qui correspondent à la fois dans la cohorte et dans la compréhension initiale. Tracer l'id comme texte rend cette figure un peu encombré, mais pourrait être utile dans certains cas.
Figure 4
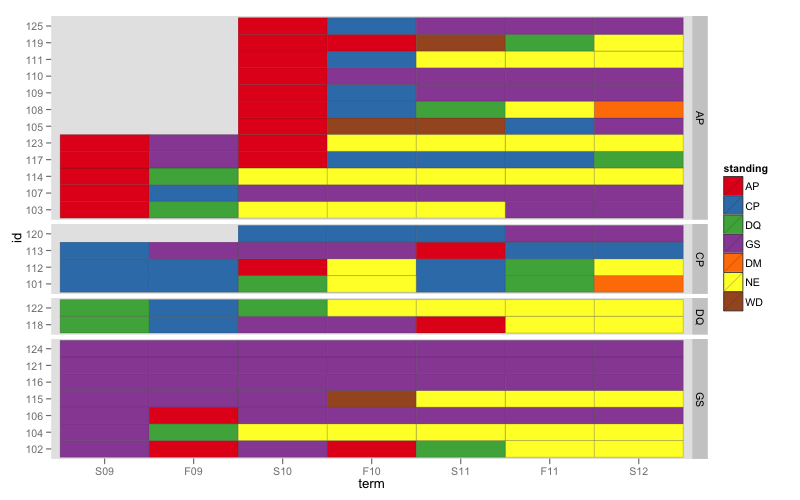 Cette parcelle est comme une heatmap où chaque ligne est un étudiant. J'ai contrôlé l'ordre de l'
Cette parcelle est comme une heatmap où chaque ligne est un étudiant. J'ai contrôlé l'ordre de l' id l'axe de la force initial_standing et de la cohorte des groupements de rester ensemble. Si vous avez beaucoup plus de lignes, vous pouvez envisager de tri des lignes par un certain type de clustering.
library(ggplot2)
# Create new data frame for determining initial standing.
standing_data = data.frame(id=unique(df1$id), initial_standing=NA, cohort=NA)
for (i in 1:nrow(standing_data)) {
id = standing_data$id[i]
subdat = df1[df1$id == id, ]
subdat = subdat[complete.cases(subdat), ]
initial_standing = subdat$standing[which.min(subdat$term)]
standing_data[i, "initial_standing"] = as.character(initial_standing)
standing_data[i, "cohort"] = as.character(subdat$cohort[1])
}
standing_data$cohort = factor(standing_data$cohort, levels=levels(df1$cohort))
standing_data$initial_standing = factor(standing_data$initial_standing,
levels=levels(df1$standing))
# Add the new column (initial_standing) to df1.
df1 = merge(df1, standing_data[, c("id", "initial_standing")], by="id")
# Remove rows where standing is missing. Make some plots tidier.
df1 = df1[!is.na(df1$standing), ]
# Create id factor, controlling the sort order of the levels.
id_order = order(standing_data$initial_standing, standing_data$cohort)
df1$id = factor(df1$id, levels=as.character(standing_data$id)[id_order])
p1 = ggplot(df1, aes(x=term, fill=standing)) +
geom_bar(position="fill", colour="grey20", size=0.5, width=1.0) +
facet_grid(cohort ~ .) +
scale_fill_brewer(palette="Set1")
p2 = ggplot(df1, aes(x=term, y=termGPA, group=id)) +
geom_line(colour="grey70") +
geom_point(aes(colour=standing), size=4) +
facet_grid(cohort ~ .) +
scale_colour_brewer(palette="Set1")
p3 = ggplot(df1, aes(x=term, y=termGPA, group=id)) +
geom_line(colour="grey70") +
geom_point(aes(colour=standing), size=4) +
geom_text(aes(label=id), hjust=-0.30, size=3) +
facet_grid(initial_standing ~ cohort) +
scale_colour_brewer(palette="Set1")
p4 = ggplot(df1, aes(x=term, y=id, fill=standing)) +
geom_tile(colour="grey20") +
facet_grid(initial_standing ~ ., space="free_y", scales="free_y") +
scale_fill_brewer(palette="Set1") +
opts(panel.grid.major=theme_blank()) +
opts(panel.grid.minor=theme_blank())
ggsave("plot_1.png", p1, width=10, height=6.25, dpi=80)
ggsave("plot_2.png", p2, width=10, height=6.25, dpi=80)
ggsave("plot_3.png", p3, width=10, height=6.25, dpi=80)
ggsave("plot_4.png", p4, width=10, height=6.25, dpi=80)
en cherchant ma question, j'ai trouvé quelques autres options que je vais énumérer ici.
un certain nombre de paquets R relativement nouveaux sont conçus pour visualiser et analyser les données du "cycle de vie" ou de la "séquence multi-états". L'idée est qu'au fil du temps, les gens (ou les objets) entrent et sortent de diverses catégories--par exemple, les changements de carrière, le mariage et le divorce, la santé et la maladie, ou, dans mon cas, les catégories de la réussite scolaire au collège.
R paquets pour la visualisation les données sur la séquence ou le cycle biologique comprennent biograph, mentionné par @timriffe dans un commentaire ci-dessus, et TraMineR. Frans Willekens, auteur du paquet biographe, a un livre sur le paquet,Biograph. Analyse multi-Etats des cycles de vie avec R, qui sera publié par Springer cet automne. TraMineR a un manuel d'utilisation détaillé au lien ci-dessus et aussi un JSS article. JSS a aussi un numéro spécial sur les modèles multi-états dans le contexte de l'analyse des risques qui traite des paquets R supplémentaires pour la modélisation multi-états.
j'ai aussi trouvé un logiciel spécialisé conçu pour visualiser les mouvements entre les catégories au fil du temps. Parallèle est un programme simple et gratuit pour produire des visualisations de base, bien qu'il ait une flexibilité limitée. Lifeflow est plus sophistiqué. Il est également gratuit, mais vous devez envoyer un e-mail au créateur demandant un copie.
je vais ajouter plus de détails à cette réponse, une fois que j'aurai eu la chance d'essayer ces outils.
j'aurais aimé trouver la réponse de @bdemarest avant d'écrire un paquet R pour résoudre ce problème, mais puisque L'OP a demandé des mises à jour supplémentaires, je vais partager une solution de plus. Ce que bdemarest a suggéré dans la Figure 4 est ce que j'ai appelé un type de tracé de ligne horizontale.
dans le développement du longCatEDA R, Nous avons constaté que le tri des données était crucial pour créer des tracés utiles (voir example(sorter) et le rapport lié dans le commentaire ci-dessous pour les détails techniques), d'autant que la taille le problème est devenu grand. Par exemple, nous avons commencé le problème avec des données quotidiennes sur la consommation d'alcool (abstinence, consommation, abus) pour plusieurs milliers de participants sur une période de 3 ans (>1000 jours).
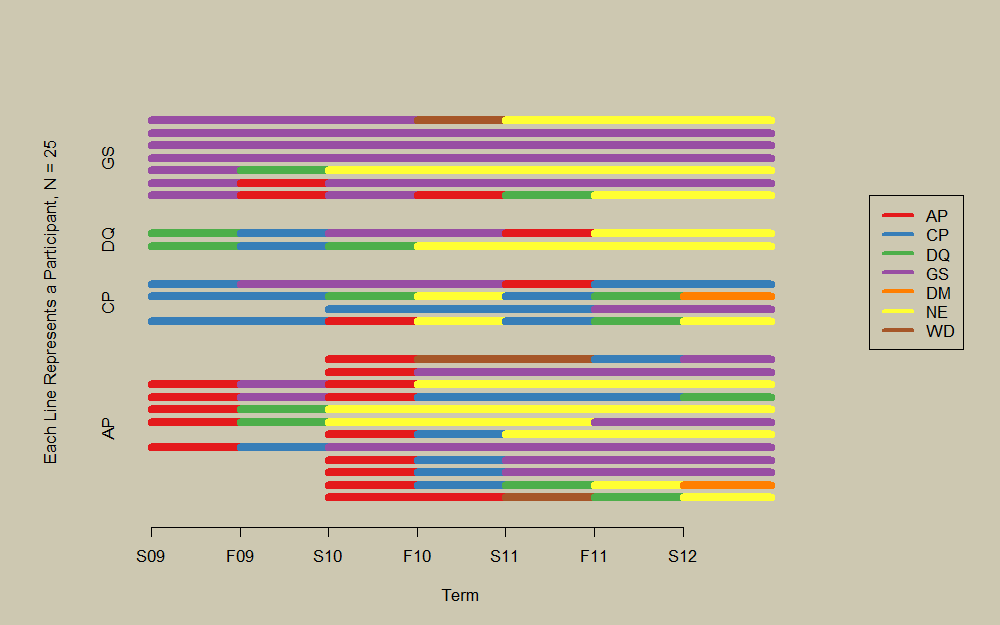
le code pour appliquer le tracé de la ligne horizontale aux données de @eipi10 est ci-dessous. La Figure 1 stratifie parterm, et la Figure 2 stratifie par Premier statut comme avec la Figure 4 de @bdemarest, bien que les résultats ne soient pas identiques en raison du tri à l'intérieur des strates.
Figure 1
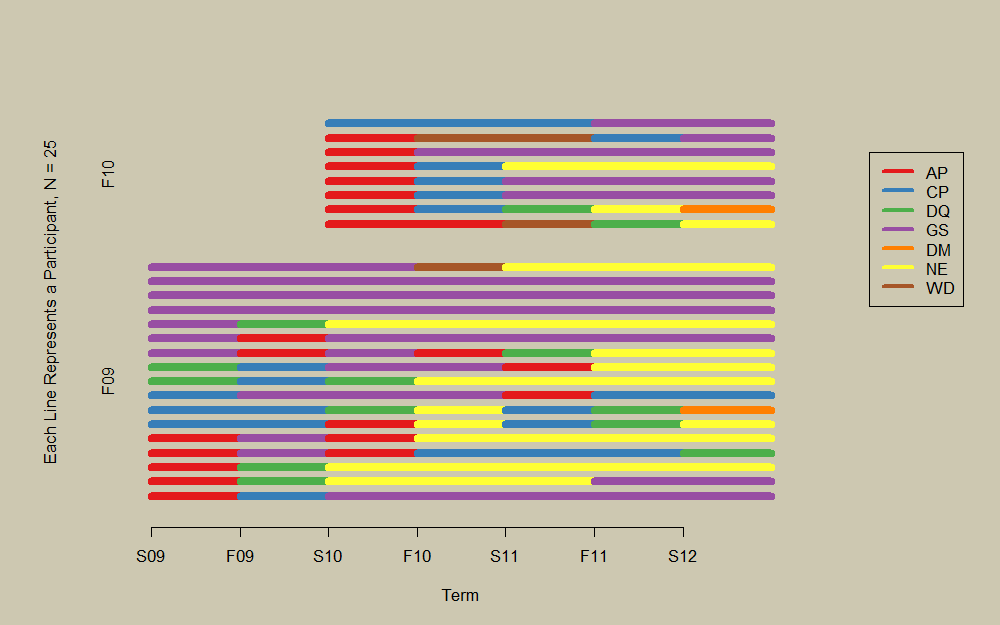
Figure 2
# libraries
install.packages('longCatEDA')
library(longCatEDA)
library(RColorBrewer)
# transform data long to wide
dfw <- reshape(df1,
timevar = 'term',
idvar = c('id', 'cohort'),
direction = 'wide')
# set up objects required by longCat()
y <- dfw[,seq(3,15,by=2)]
Labels <- levels(df1$standing)
tLabels <- levels(df1$term)
groupLabels <- levels(dfw$cohort)
# use the same colors as bdemarest
cols <- brewer.pal(7, "Set1")
# plot the longCat object
png('plot1.png', width=10, height=6.25, units='in', res=100)
par(bg='cornsilk3', mar=c(5.1, 4.1, 4.1, 8.1), xpd=TRUE)
lc <- longCat(y=y, Labels=Labels, tLabels=tLabels, id=dfw$id)
longCatPlot(lc, cols=cols, xlab='Term', lwd=8, legendBuffer=0)
legend(8.1, 25, legend=Labels, col=cols, lty=1, lwd=4)
dev.off()
# stratify by term
png('plot2.png', width=10, height=6.25, units='in', res=100)
par(bg='cornsilk3', mar=c(5.1, 4.1, 4.1, 8.1), xpd=TRUE)
lc.g <- sorter(lc, group=dfw$cohort, groupLabels=groupLabels)
longCatPlot(lc.g, cols=cols, xlab='Term', lwd=8, legendBuffer=0)
legend(8.1, 25, legend=Labels, col=cols, lty=1, lwd=4)
dev.off()
# stratify by first status, akin to Figure 4 by bdemarest
png('plot2.png', width=10, height=6.25, units='in', res=100)
par(bg='cornsilk3', mar=c(5.1, 4.1, 4.1, 8.1), xpd=TRUE)
first <- apply(!is.na(y), 1, function(x) which(x)[1])
first <- y[cbind(seq_along(first), first)]
lc.1 <- sorter(lc, group=factor(first), groupLabels = sort(unique(first)))
longCatPlot(lc.1, cols=cols, xlab='Term', lwd=8, legendBuffer=0)
legend(8.1, 25, legend=Labels, col=cols, lty=1, lwd=4)
dev.off()