Texte flou (phrases/titres) correspondance en C#
Hey, j'utilise Levenshteins algorithme pour obtenir la distance entre la chaîne de la source et de la cible.
j'ai aussi la méthode qui retourne la valeur de 0 à 1:
/// <summary>
/// Gets the similarity between two strings.
/// All relation scores are in the [0, 1] range,
/// which means that if the score gets a maximum value (equal to 1)
/// then the two string are absolutely similar
/// </summary>
/// <param name="string1">The string1.</param>
/// <param name="string2">The string2.</param>
/// <returns></returns>
public static float CalculateSimilarity(String s1, String s2)
{
if ((s1 == null) || (s2 == null)) return 0.0f;
float dis = LevenshteinDistance.Compute(s1, s2);
float maxLen = s1.Length;
if (maxLen < s2.Length)
maxLen = s2.Length;
if (maxLen == 0.0F)
return 1.0F;
else return 1.0F - dis / maxLen;
}
mais cela ne me suffit pas. Parce que j'ai besoin d'un moyen plus complexe pour faire correspondre deux phrases.
par exemple, je veux étiqueter automatiquement certaines musiques, j'ai des noms de chansons originales, et j'ai des chansons avec trash, comme super, qualité, années comme 2007, 2008, etc..etc.. aussi certains fichiers ont juste http://trash..thash..song_name_mp3.mp3 , les autres sont normaux. Je veux créer un algorithme qui fonctionneront plus parfait que le mien maintenant.. Peut-être que quelqu'un peut m'aider?
voici mon algo actuel:
/// <summary>
/// if we need to ignore this target.
/// </summary>
/// <param name="targetString">The target string.</param>
/// <returns></returns>
private bool doIgnore(String targetString)
{
if ((targetString != null) && (targetString != String.Empty))
{
for (int i = 0; i < ignoreWordsList.Length; ++i)
{
//* if we found ignore word or target string matching some some special cases like years (Regex).
if (targetString == ignoreWordsList[i] || (isMatchInSpecialCases(targetString))) return true;
}
}
return false;
}
/// <summary>
/// Removes the duplicates.
/// </summary>
/// <param name="list">The list.</param>
private void removeDuplicates(List<String> list)
{
if ((list != null) && (list.Count > 0))
{
for (int i = 0; i < list.Count - 1; ++i)
{
if (list[i] == list[i + 1])
{
list.RemoveAt(i);
--i;
}
}
}
}
/// <summary>
/// Does the fuzzy match.
/// </summary>
/// <param name="targetTitle">The target title.</param>
/// <returns></returns>
private TitleMatchResult doFuzzyMatch(String targetTitle)
{
TitleMatchResult matchResult = null;
if (targetTitle != null && targetTitle != String.Empty)
{
try
{
//* change target title (string) to lower case.
targetTitle = targetTitle.ToLower();
//* scores, we will select higher score at the end.
Dictionary<Title, float> scores = new Dictionary<Title, float>();
//* do split special chars: '-', ' ', '.', ',', '?', '/', ':', ';', '%', '(', ')', '#', '"', ''', '!', '|', '^', '*', '[', ']', '{', '}', '=', '!', '+', '_'
List<String> targetKeywords = new List<string>(targetTitle.Split(ignoreCharsList, StringSplitOptions.RemoveEmptyEntries));
//* remove all trash from keywords, like super, quality, etc..
targetKeywords.RemoveAll(delegate(String x) { return doIgnore(x); });
//* sort keywords.
targetKeywords.Sort();
//* remove some duplicates.
removeDuplicates(targetKeywords);
//* go through all original titles.
foreach (Title sourceTitle in titles)
{
float tempScore = 0f;
//* split orig. title to keywords list.
List<String> sourceKeywords = new List<string>(sourceTitle.Name.Split(ignoreCharsList, StringSplitOptions.RemoveEmptyEntries));
sourceKeywords.Sort();
removeDuplicates(sourceKeywords);
//* go through all source ttl keywords.
foreach (String keyw1 in sourceKeywords)
{
float max = float.MinValue;
foreach (String keyw2 in targetKeywords)
{
float currentScore = StringMatching.StringMatching.CalculateSimilarity(keyw1.ToLower(), keyw2);
if (currentScore > max)
{
max = currentScore;
}
}
tempScore += max;
}
//* calculate average score.
float averageScore = (tempScore / Math.Max(targetKeywords.Count, sourceKeywords.Count));
//* if average score is bigger than minimal score and target title is not in this source title ignore list.
if (averageScore >= minimalScore && !sourceTitle.doIgnore(targetTitle))
{
//* add score.
scores.Add(sourceTitle, averageScore);
}
}
//* choose biggest score.
float maxi = float.MinValue;
foreach (KeyValuePair<Title, float> kvp in scores)
{
if (kvp.Value > maxi)
{
maxi = kvp.Value;
matchResult = new TitleMatchResult(maxi, kvp.Key, MatchTechnique.FuzzyLogic);
}
}
}
catch { }
}
//* return result.
return matchResult;
}
Cela fonctionne normalement, mais seulement dans certains cas, beaucoup de titres qui devraient correspondre aux, ne correspond pas... Je je pense que j'ai besoin d'une sorte de formule pour jouer avec les poids et etc, mais je ne peux pas penser à un..
idées? Des Suggestions? Algos?
par ailleurs je connais déjà ce sujet (mon collègue l'a déjà posté mais nous ne pouvons pas venir avec une solution appropriée pour ce problème.): Approximative de la chaîne des algorithmes d'appariement
4 réponses
votre problème ici peut être la distinction entre les mots de bruit et les données utiles:
- Rolling_Stones.Best_of_2003.Wild_Horses.mp3
- Super.Qualité.Wild_Horses.mp3
- Tori_Amos.Wild_Horses.mp3
Vous devrez peut-être produire un dictionnaire de bruit de mots à ignorer. Cela semble grotesque, mais je ne suis pas sûr qu'il y ait un algorithme qui puisse faire la distinction entre les noms de groupes/albums et le bruit.
un peu vieux, mais il pourrait être utile pour les futurs visiteurs. Si vous utilisez déjà L'algorithme de Levenshtein et que vous avez besoin d'aller un peu mieux, je décris quelques heuristiques très efficaces dans cette solution:
obtenir la chaîne la plus proche correspondance
la clé est que vous venez avec 3 ou 4 (ou plus ) méthodes de jauger la similitude entre vos phrases (la distance Levenshtein est juste un méthode) - et puis en utilisant des exemples réels de chaînes que vous voulez faire correspondre comme similaire, vous ajustez les pondérations et les combinaisons de ces heuristiques jusqu'à ce que vous obtenez quelque chose qui maximise le nombre de correspondances positives. Ensuite, vous utilisez cette formule pour tous les matchs à venir et vous devriez voir de grands résultats.
si un utilisateur est impliqué dans le processus, il est également préférable si vous fournissez une interface qui permet à l'utilisateur de voir des correspondances supplémentaires qui se classent fortement dans la similitude au cas où ils en désaccord avec le premier choix.
voici un extrait de la réponse liée. Si vous finissez par vouloir utiliser n'importe quel de ce code tel quel, Je m'excuse à l'avance d'avoir à convertir VBA en C#.
Simple, rapide, et très utile métrique. En utilisant ceci, j'ai créé deux mesures séparées pour évaluer la similarité de deux chaînes. Un que j'appelle "valuePhrase" et un que j'appelle "valueWords". valuePhrase est juste la distance Levenshtein entre les deux phrases, et valueWords divise la chaîne en mots individuels, basés sur des délimiteurs tels que des espaces, des tirets, et tout ce que vous voulez, et compare chaque mot à l'autre mot, résumant la plus courte distance Levenshtein reliant deux mots. Essentiellement, il évalue si les informations 'phrase' est vraiment dans un autre, tout comme un mot de permutation. J'ai passé quelques jours en tant que projet parallèle à trouver la manière la plus efficace possible de diviser un chaîne basée sur les délimiteurs.
valueWords, valuePhrase, et la fonction de répartition:
Public Function valuePhrase#(ByRef S1$, ByRef S2$)
valuePhrase = LevenshteinDistance(S1, S2)
End Function
Public Function valueWords#(ByRef S1$, ByRef S2$)
Dim wordsS1$(), wordsS2$()
wordsS1 = SplitMultiDelims(S1, " _-")
wordsS2 = SplitMultiDelims(S2, " _-")
Dim word1%, word2%, thisD#, wordbest#
Dim wordsTotal#
For word1 = LBound(wordsS1) To UBound(wordsS1)
wordbest = Len(S2)
For word2 = LBound(wordsS2) To UBound(wordsS2)
thisD = LevenshteinDistance(wordsS1(word1), wordsS2(word2))
If thisD < wordbest Then wordbest = thisD
If thisD = 0 Then GoTo foundbest
Next word2
foundbest:
wordsTotal = wordsTotal + wordbest
Next word1
valueWords = wordsTotal
End Function
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
' SplitMultiDelims
' This function splits Text into an array of substrings, each substring
' delimited by any character in DelimChars. Only a single character
' may be a delimiter between two substrings, but DelimChars may
' contain any number of delimiter characters. It returns a single element
' array containing all of text if DelimChars is empty, or a 1 or greater
' element array if the Text is successfully split into substrings.
' If IgnoreConsecutiveDelimiters is true, empty array elements will not occur.
' If Limit greater than 0, the function will only split Text into 'Limit'
' array elements or less. The last element will contain the rest of Text.
''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
Function SplitMultiDelims(ByRef Text As String, ByRef DelimChars As String, _
Optional ByVal IgnoreConsecutiveDelimiters As Boolean = False, _
Optional ByVal Limit As Long = -1) As String()
Dim ElemStart As Long, N As Long, M As Long, Elements As Long
Dim lDelims As Long, lText As Long
Dim Arr() As String
lText = Len(Text)
lDelims = Len(DelimChars)
If lDelims = 0 Or lText = 0 Or Limit = 1 Then
ReDim Arr(0 To 0)
Arr(0) = Text
SplitMultiDelims = Arr
Exit Function
End If
ReDim Arr(0 To IIf(Limit = -1, lText - 1, Limit))
Elements = 0: ElemStart = 1
For N = 1 To lText
If InStr(DelimChars, Mid(Text, N, 1)) Then
Arr(Elements) = Mid(Text, ElemStart, N - ElemStart)
If IgnoreConsecutiveDelimiters Then
If Len(Arr(Elements)) > 0 Then Elements = Elements + 1
Else
Elements = Elements + 1
End If
ElemStart = N + 1
If Elements + 1 = Limit Then Exit For
End If
Next N
'Get the last token terminated by the end of the string into the array
If ElemStart <= lText Then Arr(Elements) = Mid(Text, ElemStart)
'Since the end of string counts as the terminating delimiter, if the last character
'was also a delimiter, we treat the two as consecutive, and so ignore the last elemnent
If IgnoreConsecutiveDelimiters Then If Len(Arr(Elements)) = 0 Then Elements = Elements - 1
ReDim Preserve Arr(0 To Elements) 'Chop off unused array elements
SplitMultiDelims = Arr
End Function
mesures de similitude
en utilisant ces deux mesures, et une troisième qui calcule simplement la distance entre deux chaînes, j'ai une série de variables que je peux exécuter un algorithme d'optimisation pour obtenir le plus grand nombre de correspondances. La correspondance des cordes floues est, elle - même, une science floue, et donc en créant des mesures linéairement indépendantes pour mesurer la similarité des cordes, et ayant un ensemble connu de cordes que nous voulons faire correspondre les uns aux autres, nous pouvons trouver les paramètres qui, pour nos styles spécifiques de cordes, donnent les meilleurs résultats de correspondance floue.
initialement, le but de la métrique était d'avoir une faible valeur de recherche pour une correspondance exacte, et d'augmenter les valeurs de recherche pour des mesures de plus en plus permutées. Dans irréaliste cas, c'était assez facile à définir à l'aide d'un ensemble bien défini les permutations, et l'ingénierie de la formule finale de sorte qu'ils ont eu des résultats de recherche de valeurs croissantes comme souhaité.
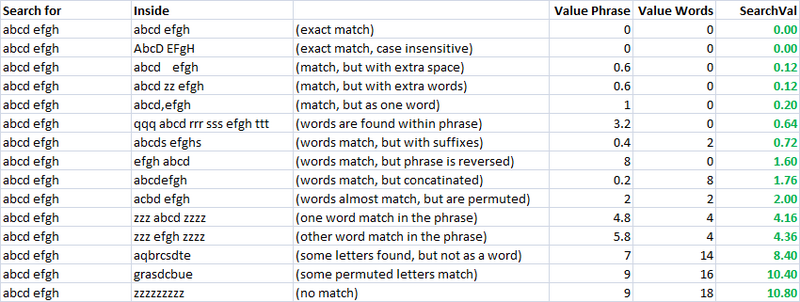
comme vous pouvez le voir, les deux dernières mesures, qui sont des mesures de chaîne floues correspondant, ont déjà une tendance naturelle à donner de faibles scores aux chaînes qui sont destinées à correspondre (en bas de la diagonale). C'est très bien.
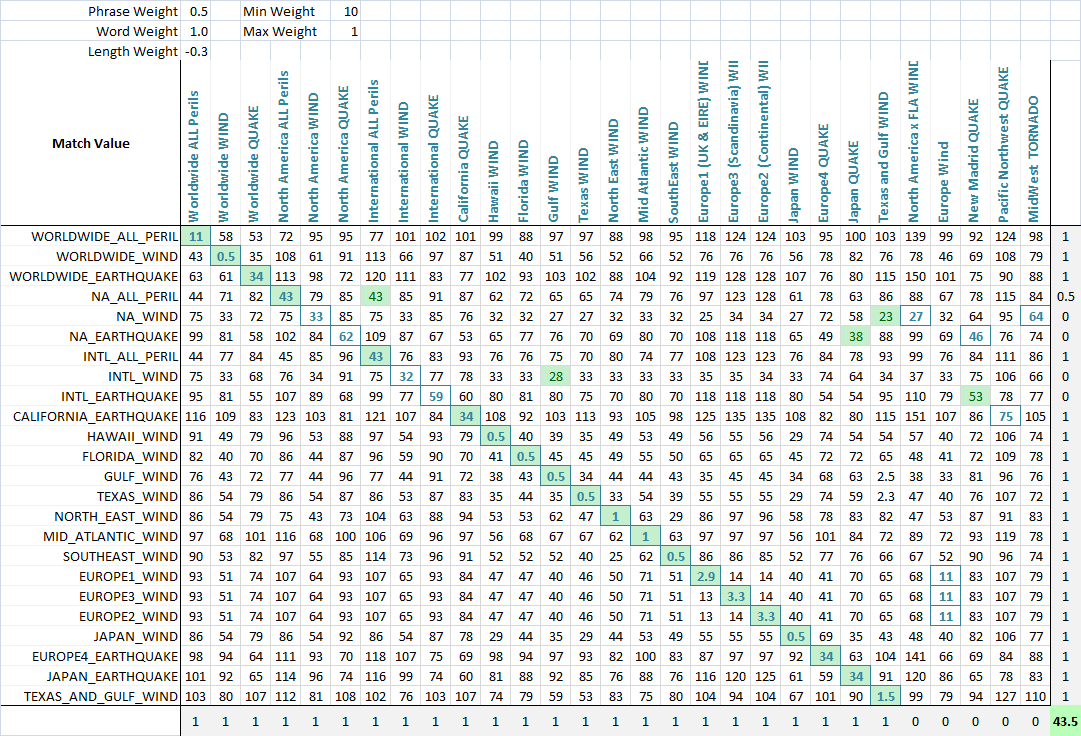
Application Pour permettre l'optimisation de correspondance floue, je pèse chaque métrique. En tant que tel, chaque application de correspondance floue de chaîne peut peser les paramètres différemment. La formule qui définit le score final est une simple combinaison des mesures et de leurs poids:
value = Min(phraseWeight*phraseValue, wordsWeight*wordsValue)*minWeight +
Max(phraseWeight*phraseValue, wordsWeight*wordsValue)*maxWeight + lengthWeight*lengthValue
à l'aide d'un algorithme d'optimisation (le réseau neuronal est le meilleur ici parce qu'il s'agit d'un problème discret et multidimensionnel), le but est maintenant de maximiser le nombre de correspondances. J'ai créé une fonction qui détecte le nombre de bon matchs de chaque jeu à l'autre, comme peut être vu dans cette capture d'écran finale. Une colonne ou une rangée obtient un point si le score le plus bas est assigné à la chaîne qui était destinée à être appariée, et des points partiels sont donnés s'il y a une égalité pour le score le plus bas, et la correspondance correcte est parmi les chaînes liées appariées. J'ai ensuite optimisé. Vous pouvez voir qu'une cellule verte est la colonne qui correspond le mieux à la rangée actuelle, et un carré bleu autour de la cellule est la rangée qui correspond le mieux à la colonne actuelle. Le score en le coin en bas est à peu près le nombre de matchs et c'est ce que nous disons à notre problème d'optimisation pour maximiser.
il semble que ce que vous voulez peut être une plus longue correspondance de substrat. C'est, dans votre exemple, deux fichiers comme
trash. thash. song_name_mp3.mp3 et poubelle ... spotch ... song_name_mp3.mp3
finirait par ressembler à la même chose.
vous auriez besoin de quelques heuristiques, bien sûr. Une chose que vous pourriez essayer est de mettre la chaîne à travers un convertisseur soundex. Soundex est le "codec" utilisé pour voir si les choses "sonnent" la même chose (comme vous pourriez dire d'un opérateur téléphonique). C'est plus ou moins une translittération phonétique grossière et fausse. Il est certainement plus pauvre que la distance d'édition, mais beaucoup, beaucoup moins cher. (L'usage officiel est pour les noms, et n'utilise que trois personnages. Il n'y a aucune raison de s'arrêter là, cependant, il suffit d'utiliser le mapping pour chaque caractère dans la chaîne. Voir wikipedia pour plus de détails)
donc ma suggestion serait de soundex vos cordes, coupez chacune en quelques longueur tranches (par exemple 5, 10, 20) et puis il suffit de regarder les grappes. Dans les clusters, vous pouvez utiliser quelque chose de plus cher comme éditer la distance ou Max substring.
il y a beaucoup de travail fait sur le problème un peu connexe de l'alignement de séquence D'ADN (recherche pour" alignement de séquence locale") - algorithme classique étant" Needleman-Wunsch " et plus complexes modernes aussi facile à trouver. L'idée est - semblable à la réponse de Greg - au lieu d'identifier et de comparer des mots-clés essayer de trouver la plus longue chaîne vaguement assortie dans de longues chaînes.
qu'étant triste, si le seul but est de trier la musique, un certain nombre d'expressions régulières à couvrir les schémas de nommage possibles fonctionnerait probablement mieux que n'importe quel algorithme générique.