Trouver tous les cycles dans un graphique dirigé
Comment puis-je trouver (itérer sur) tous les cycles dans un graphique dirigé depuis/vers un noeud donné?
par exemple, je veux quelque chose comme ceci:
A->B->A
A->B->C->A
mais non: B - > C - > B
17 réponses
j'ai trouvé cette page dans ma recherche et comme les cycles ne sont pas les mêmes que les composants fortement connectés, j'ai continué à chercher et finalement, j'ai trouvé un algorithme efficace qui liste tous les cycles (élémentaires) d'un graphe dirigé. Il est de Donald B. Johnson et le papier peut être trouvé dans le lien suivant:
http://www.cs.tufts.edu/comp/150GA/homeworks/hw1/Johnson%2075.PDF
une implémentation java peut être trouvée dans:
http://normalisiert.de/code/java/elementaryCycles.zip
A Mathematica démonstration de L'algorithme de Johnson peut être trouvé ici , la mise en œuvre peut être téléchargée à partir de la droite ( " Download author code " ).
Note: En fait, il existe de nombreux algorithmes pour ce problème. Certains d'entre eux sont répertoriés dans cet article:
http://dx.doi.org/10.1137/0205007
selon L'article, L'algorithme de Johnson est le plus rapide.
profondeur la première recherche avec traçage devrait fonctionner ici. Gardez un tableau de valeurs booléennes pour garder une trace de si vous avez visité un noeud avant. Si vous êtes à court de nouveaux noeuds (sans frapper un noeud que vous avez déjà été), alors revenez en arrière et essayez une autre branche.
la DFS est facile à mettre en œuvre si vous avez une liste de contiguïté pour représenter le graphe. Par exemple adj[A] = {B, C} indique que B et C sont les enfants de A.
Par exemple, le pseudo-code ci-dessous. "démarrer" est le nœud de départ.
dfs(adj,node,visited):
if (visited[node]):
if (node == start):
"found a path"
return;
visited[node]=YES;
for child in adj[node]:
dfs(adj,child,visited)
visited[node]=NO;
appeler la fonction ci-dessus avec le noeud de départ:
visited = {}
dfs(adj,start,visited)
tout d'abord - vous ne voulez pas vraiment essayer de trouver littéralement tous les cycles parce que s'il ya 1 alors il ya un nombre infini de ceux-ci. Par exemple A-B-A, A-B-A-B-A etc. Ou il peut être possible de réunir 2 cycles en un cycle de type 8, etc., etc... L'approche significative consiste à rechercher tous les cycles dits simples - ceux qui ne se croisent que dans le point de départ/fin. Ensuite, si vous le souhaitez, vous pouvez générer des combinaisons de cycles simples.
One des algorithmes de base pour trouver tous les cycles simples dans un graphique dirigé est celui-ci: faire une profondeur-première traversée de tous les chemins simples (ceux qui ne se croisent pas) dans le graphique. Chaque fois que le noeud courant a un successeur sur la pile, un cycle simple est découvert. Il se compose des éléments de la pile commençant par le successeur identifié et se terminant par le haut de la pile. Profondeur première traversée de tous les chemins simples est similaire à la profondeur première recherche, mais vous ne marquez pas/n'enregistrez pas les noeuds visités autres que ceux actuellement sur la pile comme points d'arrêt.
l'algorithme de la force brute ci-dessus est terriblement inefficace et en plus de cela génère plusieurs copies des cycles. Il est toutefois le point de départ de multiples algorithmes pratiques qui appliquent diverses améliorations afin d'améliorer les performances et d'éviter la duplication des cycles. J'ai été surpris d'apprendre il y a quelque temps que ces algorithmes ne sont pas facilement disponibles dans les manuels et sur le web. J'ai donc fait quelques recherches et mis en œuvre 4 algorithmes de ce type et 1 algorithme pour les cycles dans des graphiques non dirigés dans une bibliothèque Java open source ici: http://code.google.com/p/niographs / .
BTW, puisque j'ai mentionné des graphiques non dirigés : l'algorithme pour ceux-là est différent. Construire un arbre recouvrant et puis chaque bord, ce qui n'est pas partie de l'arbre forme un cycle simple avec quelques arêtes de l'arbre. Les cycles trouvés de cette façon forment un soi-disant cycle base. Tous les cycles simples peuvent alors être trouvés en combinant deux ou plusieurs cycles de base distincts. Pour plus de détails, voir par exemple: http://dspace.mit.edu/bitstream/handle/1721.1/68106/FTL_R_1982_07.pdf .
le choix le plus simple que j'ai trouvé pour résoudre ce problème était d'utiliser la lib python appelé networkx .
il met en œuvre l'algorithme de Johnson mentionné dans la meilleure réponse de cette question, mais il rend assez simple à exécuter.
en bref, vous avez besoin de ce qui suit:
import networkx as nx
import matplotlib.pyplot as plt
# Create Directed Graph
G=nx.DiGraph()
# Add a list of nodes:
G.add_nodes_from(["a","b","c","d","e"])
# Add a list of edges:
G.add_edges_from([("a","b"),("b","c"), ("c","a"), ("b","d"), ("d","e"), ("e","a")])
#Return a list of cycles described as a list o nodes
list(nx.simple_cycles(G))
Réponse: [['a', 'b', 'd', 'e'], ['a', 'b', 'c']]
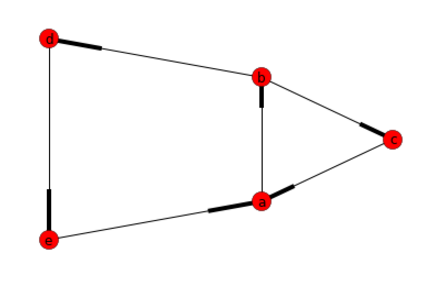
pour clarifier:
-
" les composantes fortement reliées trouveront tous les sousgraphes qui ont au moins un cycle en eux, pas tous les cycles possibles dans le graphique. par exemple, si vous prenez tous les composants fortement connectés et s'effondrer/grouper/fusionner chacun d'eux dans un noeud (i.e. un noeud par composant), vous obtiendrez un arbre sans cycles (un DAG en fait). Chaque composant (qui est essentiellement un sous-paragraphe avec au moins un cycle en elle) peut contenir beaucoup plus cycles possibles à l'interne, donc SCC ne trouvera pas tous les cycles possibles, il trouvera tous les groupes possibles qui ont au moins un cycle, et si vous les groupez, alors le graphique n'aura pas de cycles.
-
pour trouver tous cycles simples dans un graphique, comme d'autres l'ont mentionné, l'algorithme de Johnson est un candidat.
on m'a posé cette question une fois, je soupçonne que cela vous est arrivé et vous venez ici pour de l'aide. Divisez le problème en trois questions et cela devient plus facile.
- comment déterminer la prochaine validité route
- comment déterminer si un point A
- Comment éviter de traverser le même point encore
Problème 1) Utiliser l'itérateur modèle pour fournir une façon d'itérer les résultats de route. Un bon endroit pour mettre la logique pour obtenir la prochaine route est probablement le "moveNext" de votre iterator. Pour trouver une route valide, cela dépend de votre structure de données. Pour moi, c'était une table sql plein de valable route possibilités donc j'ai dû construire une requête pour obtenir l'valide destinations donné une source.
problème 2) Pousser chaque nœud que vous trouvez dans une collection que vous obtenez, ce qui signifie que vous pouvez voir si vous êtes doubler " retour" sur un point très facilement en s'interrogeant sur la collection en cours de création à la volée.
problème 3) Si à un moment donné vous voyez que vous doublez en arrière, vous pouvez pop choses hors de la collection et "back up". Puis, à partir de ce point, essayez de "progresser" à nouveau.
Hack: si vous utilisez Sql Server 2008, il y a de nouvelles choses de "hiérarchie" que vous pouvez utiliser pour résoudre rapidement ceci si vous structurez vos données dans un arbre.
il y a deux étapes (algorithmes) impliquées dans la recherche de tous les cycles dans un DAG.
la première étape consiste à utiliser L'algorithme de Tarjan pour trouver l'ensemble des composants fortement connectés.
- commencent à partir de n'importe quel vertex arbitraire.
- DFS de ce vertex. Pour chaque noeud x, gardez deux numéros, DFS[X] et DFS[lowval [x]. dfs_index[x] stocke lorsque ce noeud est visité, alors que dfs_lowval[x] = min (dfs_low[k]) où k est tout les enfants de x qui n'est pas le parent direct de x dans l'arbre DFS-spanning.
- tous les noeuds avec le même dfs_lowval[x] sont dans le même composant fortement connecté.
la deuxième étape consiste à trouver des cycles (chemins) à l'intérieur des composants connectés. Je suggère d'utiliser une version modifiée de L'algorithme de Hierholzer.
l'idée est:
- choisissez un vertex V de départ, et suivez un sentier des bords de vertex jusqu'à ce que vous revenez à v. Il n'est pas possible de se coincer à n'importe quel sommet autre que v, parce que le degré Pair de tous les sommets assure que, quand la piste entre dans un autre sommet w, il doit y avoir un bord inutilisé laissant w. Le tour formé de cette façon est un tour fermé, mais ne peut pas couvrir tous les sommets et les bords du graphe initial.
- aussi longtemps qu'il existe un vertex v qui appartient au tour en cours mais qui a des bords adjacents ne faisant pas partie de le tour, commencer un autre sentier à partir de v, en suivant les bords non utilisés jusqu'à ce que vous reveniez à v, et rejoindre le tour formé de cette façon à la tournée précédente.
voici le lien vers une implémentation Java avec un test case:
http://stones333.blogspot.com/2013/12/find-cycles-in-directed-graph-dag.html
dans le cas de undirected graph, un article récemment publié ( Optimal listing of cycles and st-paths in undirected graphs ) offre une solution asymptotiquement optimale. Vous pouvez le lire ici http://arxiv.org/abs/1205.2766 ou ici http://dl.acm.org/citation.cfm?id=2627951 Je sais que cela ne répond pas à votre question, mais puisque le titre de votre question ne mentionne pas la direction, il pourrait toujours être utile pour la recherche Google
commencer par le noeud X et vérifier tous les noeuds enfant (les noeuds parent et enfant sont équivalents s'ils ne sont pas dirigés). Marquez ces noeuds enfants comme étant des enfants de X. À partir d'un tel noeud enfant A, marquez-le comme étant des enfants de A, X', où X' est marqué comme étant à 2 pas.). Si vous frappez plus tard X et marquez comme étant un enfant de X", cela signifie que X est dans un cycle de 3 noeuds. Il est facile de retracer son parent (tel quel, l'algorithme n'a aucun support pour cela, vous trouverez donc le parent qui a X').
Note: si le graphe n'est pas dirigé ou a des bords bidirectionnels, cet algorithme devient plus compliqué, en supposant que vous ne voulez pas traverser le même bord deux fois pour un cycle.
si ce que vous voulez est de trouver tous les circuits élémentaires dans un graphique, vous pouvez utiliser L'algorithme EC, de JAMES C. TIERNAN, trouvé sur un papier depuis 1970.
Le très original algorithme de CE que j'ai réussi à le mettre en œuvre en php (j'espère qu'il ya pas d'erreurs est illustré ci-dessous). Il peut trouver des boucles aussi s'il y en a. Les circuits de cette implémentation (qui tente de cloner l'original) sont les éléments non-zéros. Zéro ici signifie la non-existence. (null comme nous le savons).
en dehors de celui ci-dessous suit une autre implémentation qui donne à l'algorithme plus d'indépendance, cela signifie que les noeuds peuvent partir de n'importe où, même à partir de nombres négatifs, E. g -4,-3, -2,.. etc.
Dans les deux cas, il est nécessaire que les nœuds sont séquentielles.
vous pourriez avoir besoin d'étudier le papier original, James C. Tiernan Elementary Circuit Algorithm
<?php
echo "<pre><br><br>";
$G = array(
1=>array(1,2,3),
2=>array(1,2,3),
3=>array(1,2,3)
);
define('N',key(array_slice($G, -1, 1, true)));
$P = array(1=>0,2=>0,3=>0,4=>0,5=>0);
$H = array(1=>$P, 2=>$P, 3=>$P, 4=>$P, 5=>$P );
$k = 1;
$P[$k] = key($G);
$Circ = array();
#[Path Extension]
EC2_Path_Extension:
foreach($G[$P[$k]] as $j => $child ){
if( $child>$P[1] and in_array($child, $P)===false and in_array($child, $H[$P[$k]])===false ){
$k++;
$P[$k] = $child;
goto EC2_Path_Extension;
} }
#[EC3 Circuit Confirmation]
if( in_array($P[1], $G[$P[$k]])===true ){//if PATH[1] is not child of PATH[current] then don't have a cycle
$Circ[] = $P;
}
#[EC4 Vertex Closure]
if($k===1){
goto EC5_Advance_Initial_Vertex;
}
//afou den ksana theoreitai einai asfales na svisoume
for( $m=1; $m<=N; $m++){//H[P[k], m] <- O, m = 1, 2, . . . , N
if( $H[$P[$k-1]][$m]===0 ){
$H[$P[$k-1]][$m]=$P[$k];
break(1);
}
}
for( $m=1; $m<=N; $m++ ){//H[P[k], m] <- O, m = 1, 2, . . . , N
$H[$P[$k]][$m]=0;
}
$P[$k]=0;
$k--;
goto EC2_Path_Extension;
#[EC5 Advance Initial Vertex]
EC5_Advance_Initial_Vertex:
if($P[1] === N){
goto EC6_Terminate;
}
$P[1]++;
$k=1;
$H=array(
1=>array(1=>0,2=>0,3=>0,4=>0,5=>0),
2=>array(1=>0,2=>0,3=>0,4=>0,5=>0),
3=>array(1=>0,2=>0,3=>0,4=>0,5=>0),
4=>array(1=>0,2=>0,3=>0,4=>0,5=>0),
5=>array(1=>0,2=>0,3=>0,4=>0,5=>0)
);
goto EC2_Path_Extension;
#[EC5 Advance Initial Vertex]
EC6_Terminate:
print_r($Circ);
?>
alors c'est l'autre implémentation, plus indépendante du graphe, sans goto et sans valeurs de tableau, à la place elle utilise les clés de tableau, le chemin, le graphe et les circuits sont stockés comme des clés de tableau (utilisez des valeurs de tableau si vous voulez, changez juste les lignes nécessaires). Le graphique de l'exemple commence à partir de -4 pour montrer son indépendance.
<?php
$G = array(
-4=>array(-4=>true,-3=>true,-2=>true),
-3=>array(-4=>true,-3=>true,-2=>true),
-2=>array(-4=>true,-3=>true,-2=>true)
);
$C = array();
EC($G,$C);
echo "<pre>";
print_r($C);
function EC($G, &$C){
$CNST_not_closed = false; // this flag indicates no closure
$CNST_closed = true; // this flag indicates closure
// define the state where there is no closures for some node
$tmp_first_node = key($G); // first node = first key
$tmp_last_node = $tmp_first_node-1+count($G); // last node = last key
$CNST_closure_reset = array();
for($k=$tmp_first_node; $k<=$tmp_last_node; $k++){
$CNST_closure_reset[$k] = $CNST_not_closed;
}
// define the state where there is no closure for all nodes
for($k=$tmp_first_node; $k<=$tmp_last_node; $k++){
$H[$k] = $CNST_closure_reset; // Key in the closure arrays represent nodes
}
unset($tmp_first_node);
unset($tmp_last_node);
# Start algorithm
foreach($G as $init_node => $children){#[Jump to initial node set]
#[Initial Node Set]
$P = array(); // declare at starup, remove the old $init_node from path on loop
$P[$init_node]=true; // the first key in P is always the new initial node
$k=$init_node; // update the current node
// On loop H[old_init_node] is not cleared cause is never checked again
do{#Path 1,3,7,4 jump here to extend father 7
do{#Path from 1,3,8,5 became 2,4,8,5,6 jump here to extend child 6
$new_expansion = false;
foreach( $G[$k] as $child => $foo ){#Consider each child of 7 or 6
if( $child>$init_node and isset($P[$child])===false and $H[$k][$child]===$CNST_not_closed ){
$P[$child]=true; // add this child to the path
$k = $child; // update the current node
$new_expansion=true;// set the flag for expanding the child of k
break(1); // we are done, one child at a time
} } }while(($new_expansion===true));// Do while a new child has been added to the path
# If the first node is child of the last we have a circuit
if( isset($G[$k][$init_node])===true ){
$C[] = $P; // Leaving this out of closure will catch loops to
}
# Closure
if($k>$init_node){ //if k>init_node then alwaya count(P)>1, so proceed to closure
$new_expansion=true; // $new_expansion is never true, set true to expand father of k
unset($P[$k]); // remove k from path
end($P); $k_father = key($P); // get father of k
$H[$k_father][$k]=$CNST_closed; // mark k as closed
$H[$k] = $CNST_closure_reset; // reset k closure
$k = $k_father; // update k
} } while($new_expansion===true);//if we don't wnter the if block m has the old k$k_father_old = $k;
// Advance Initial Vertex Context
}//foreach initial
}//function
?>
j'ai analysé et documenté la CE mais malheureusement la documentation est en grec.
je suis tombé sur l'algorithme suivant qui semble être plus efficace que l'algorithme de Johnson (au moins pour les grands graphes). Je ne suis toutefois pas sûr de sa performance par rapport à L'algorithme de Tarjan.
De plus, Je ne l'ai vérifié que pour les triangles jusqu'à présent. Si vous êtes intéressé, veuillez consulter "Arboricity and Subgraph Listing Algorithms" par Norishige Chiba et Takao Nishizeki ( http://dx.doi.org/10.1137/0214017 )
ne pouvez-vous pas faire une petite fonction récursive pour traverser les noeuds?
readDiGraph( string pathSoFar, Node x)
{
if(NoChildren) MasterList.add( pathsofar + Node.name ) ;
foreach( child )
{
readDiGraph( pathsofar + "->" + this.name, child)
}
}
si vous avez une tonne de noeuds, vous allez manquer de stack
Javascript solution à l'aide disjoints de définir des listes liées. Peut être mis à niveau pour séparer les forêts pour des temps d'exécution plus rapides.
var input = '5\nYYNNN\nYYYNN\nNYYNN\nNNNYN\nNNNNY'
console.log(input);
//above solution should be 3 because the components are
//{0,1,2}, because {0,1} and {1,2} therefore {0,1,2}
//{3}
//{4}
//MIT license, authored by Ling Qing Meng
//'4\nYYNN\nYYYN\nNYYN\nNNNY'
//Read Input, preformatting
var reformat = input.split(/\n/);
var N = reformat[0];
var adjMatrix = [];
for (var i = 1; i < reformat.length; i++) {
adjMatrix.push(reformat[i]);
}
//for (each person x from 1 to N) CREATE-SET(x)
var sets = [];
for (var i = 0; i < N; i++) {
var s = new LinkedList();
s.add(i);
sets.push(s);
}
//populate friend potentials using combinatorics, then filters
var people = [];
var friends = [];
for (var i = 0; i < N; i++) {
people.push(i);
}
var potentialFriends = k_combinations(people,2);
for (var i = 0; i < potentialFriends.length; i++){
if (isFriend(adjMatrix,potentialFriends[i]) === 'Y'){
friends.push(potentialFriends[i]);
}
}
//for (each pair of friends (x y) ) if (FIND-SET(x) != FIND-SET(y)) MERGE-SETS(x, y)
for (var i = 0; i < friends.length; i++) {
var x = friends[i][0];
var y = friends[i][1];
if (FindSet(x) != FindSet(y)) {
sets.push(MergeSet(x,y));
}
}
for (var i = 0; i < sets.length; i++) {
//sets[i].traverse();
}
console.log('How many distinct connected components?',sets.length);
//Linked List data structures neccesary for above to work
function Node(){
this.data = null;
this.next = null;
}
function LinkedList(){
this.head = null;
this.tail = null;
this.size = 0;
// Add node to the end
this.add = function(data){
var node = new Node();
node.data = data;
if (this.head == null){
this.head = node;
this.tail = node;
} else {
this.tail.next = node;
this.tail = node;
}
this.size++;
};
this.contains = function(data) {
if (this.head.data === data)
return this;
var next = this.head.next;
while (next !== null) {
if (next.data === data) {
return this;
}
next = next.next;
}
return null;
};
this.traverse = function() {
var current = this.head;
var toPrint = '';
while (current !== null) {
//callback.call(this, current); put callback as an argument to top function
toPrint += current.data.toString() + ' ';
current = current.next;
}
console.log('list data: ',toPrint);
}
this.merge = function(list) {
var current = this.head;
var next = current.next;
while (next !== null) {
current = next;
next = next.next;
}
current.next = list.head;
this.size += list.size;
return this;
};
this.reverse = function() {
if (this.head == null)
return;
if (this.head.next == null)
return;
var currentNode = this.head;
var nextNode = this.head.next;
var prevNode = this.head;
this.head.next = null;
while (nextNode != null) {
currentNode = nextNode;
nextNode = currentNode.next;
currentNode.next = prevNode;
prevNode = currentNode;
}
this.head = currentNode;
return this;
}
}
/**
* GENERAL HELPER FUNCTIONS
*/
function FindSet(x) {
for (var i = 0; i < sets.length; i++){
if (sets[i].contains(x) != null) {
return sets[i].contains(x);
}
}
return null;
}
function MergeSet(x,y) {
var listA,listB;
for (var i = 0; i < sets.length; i++){
if (sets[i].contains(x) != null) {
listA = sets[i].contains(x);
sets.splice(i,1);
}
}
for (var i = 0; i < sets.length; i++) {
if (sets[i].contains(y) != null) {
listB = sets[i].contains(y);
sets.splice(i,1);
}
}
var res = MergeLists(listA,listB);
return res;
}
function MergeLists(listA, listB) {
var listC = new LinkedList();
listA.merge(listB);
listC = listA;
return listC;
}
//access matrix by i,j -> returns 'Y' or 'N'
function isFriend(matrix, pair){
return matrix[pair[0]].charAt(pair[1]);
}
function k_combinations(set, k) {
var i, j, combs, head, tailcombs;
if (k > set.length || k <= 0) {
return [];
}
if (k == set.length) {
return [set];
}
if (k == 1) {
combs = [];
for (i = 0; i < set.length; i++) {
combs.push([set[i]]);
}
return combs;
}
// Assert {1 < k < set.length}
combs = [];
for (i = 0; i < set.length - k + 1; i++) {
head = set.slice(i, i+1);
tailcombs = k_combinations(set.slice(i + 1), k - 1);
for (j = 0; j < tailcombs.length; j++) {
combs.push(head.concat(tailcombs[j]));
}
}
return combs;
}
DFS partir du nœud de départ s, de garder trace de la DFS chemin au cours de la traversée, et d'enregistrer le chemin d'accès si vous trouvez un bord de nœud v dans le chemin de la s. (v,s) est une arrière-garde dans l'arborescence DFS et indique ainsi un cycle contenant s.
concernant votre question sur le Cycle de Permutation , lire la suite ici: https://www.codechef.com/problems/PCYCLE
vous pouvez essayer ce code (entrer la taille et le nombre de chiffres):
# include<cstdio>
using namespace std;
int main()
{
int n;
scanf("%d",&n);
int num[1000];
int visited[1000]={0};
int vindex[2000];
for(int i=1;i<=n;i++)
scanf("%d",&num[i]);
int t_visited=0;
int cycles=0;
int start=0, index;
while(t_visited < n)
{
for(int i=1;i<=n;i++)
{
if(visited[i]==0)
{
vindex[start]=i;
visited[i]=1;
t_visited++;
index=start;
break;
}
}
while(true)
{
index++;
vindex[index]=num[vindex[index-1]];
if(vindex[index]==vindex[start])
break;
visited[vindex[index]]=1;
t_visited++;
}
vindex[++index]=0;
start=index+1;
cycles++;
}
printf("%d\n",cycles,vindex[0]);
for(int i=0;i<(n+2*cycles);i++)
{
if(vindex[i]==0)
printf("\n");
else
printf("%d ",vindex[i]);
}
}
les variantes basées sur DFS avec des bordures arrières trouveront effectivement des cycles, mais dans de nombreux cas il ne sera pas minimum cycles. En général DFS vous donne le drapeau qu'il y a un cycle mais il n'est pas assez bon pour réellement trouver des cycles. Par exemple, imaginez 5 cycles différents partageant deux bords. Il n'existe pas de moyen simple d'identifier les cycles en utilisant uniquement la DFS (y compris les variantes de rétrotractage).
L'algorithme de Johnson donne en effet tous les cycles simples uniques et a une bonne complexité temporelle et Spatiale.
mais si vous voulez juste trouver des cycles minimaux (ce qui signifie qu'il peut y avoir plus d'un cycle passant par n'importe quel vertex et nous sommes intéressés à trouver des cycles minimaux) et votre graphique n'est pas très grand, vous pouvez essayer d'utiliser la méthode simple ci-dessous. C'est très simple mais plutôt lent comparé à celui de Johnson.
donc, l'un des absolument la façon la plus facile de trouver des cycles minimaux est D'utiliser Floyd algorithme pour trouver des chemins minimaux entre tous les sommets en utilisant la matrice d'adjacence. Cet algorithme est loin d'être aussi optimal que celui de Johnson, mais il est si simple et sa boucle interne est si serrée que pour des graphes plus petits (<=50-100 noeuds) il est absolument logique de l'utiliser. La complexité temporelle est O (N^3), la complexité de l'espace O(N^2) Si vous utilisez le suivi parent et O(1) si vous ne le faites pas. Tout d'abord, trouvons la réponse à la question s'il y a un cycle. L'algorithme est très simple. Ci-dessous se trouve snippet à Scala.
val NO_EDGE = Integer.MAX_VALUE / 2
def shortestPath(weights: Array[Array[Int]]) = {
for (k <- weights.indices;
i <- weights.indices;
j <- weights.indices) {
val throughK = weights(i)(k) + weights(k)(j)
if (throughK < weights(i)(j)) {
weights(i)(j) = throughK
}
}
}
à l'origine cet algorithme fonctionne sur un graphe à bord pondéré pour trouver tous les chemins Les plus courts entre toutes les paires de noeuds (d'où l'argument de poids). Pour qu'il fonctionne correctement vous devez fournir 1 s'il existe une arête entre les nœuds ou NO_EDGE autrement. Après l'exécution de l'algorithme, vous pouvez vérifier la diagonale principale, s'il y a des valeurs inférieures à NO_EDGE que ce noeud participe à un cycle de longueur égale à la valeur. Tous les autres noeuds de la même cycle aura la même valeur (sur la diagonale principale).
pour reconstruire le cycle lui-même, nous avons besoin d'utiliser une version légèrement modifiée de l'algorithme avec le suivi des parents.
def shortestPath(weights: Array[Array[Int]], parents: Array[Array[Int]]) = {
for (k <- weights.indices;
i <- weights.indices;
j <- weights.indices) {
val throughK = weights(i)(k) + weights(k)(j)
if (throughK < weights(i)(j)) {
parents(i)(j) = k
weights(i)(j) = throughK
}
}
}
doit initialement contenir l'indice du sommet source dans une cellule de bord s'il y a un bord entre les sommets et -1 autrement. Après le retour de la fonction, pour chaque bord, vous aurez une référence au noeud parent dans l'arbre de chemin le plus court. Et puis il est facile de récupérer les cycles réels.
dans l'ensemble, nous avons le programme suivant pour trouver tous les cycles minimaux
val NO_EDGE = Integer.MAX_VALUE / 2;
def shortestPathWithParentTracking(
weights: Array[Array[Int]],
parents: Array[Array[Int]]) = {
for (k <- weights.indices;
i <- weights.indices;
j <- weights.indices) {
val throughK = weights(i)(k) + weights(k)(j)
if (throughK < weights(i)(j)) {
parents(i)(j) = parents(i)(k)
weights(i)(j) = throughK
}
}
}
def recoverCycles(
cycleNodes: Seq[Int],
parents: Array[Array[Int]]): Set[Seq[Int]] = {
val res = new mutable.HashSet[Seq[Int]]()
for (node <- cycleNodes) {
var cycle = new mutable.ArrayBuffer[Int]()
cycle += node
var other = parents(node)(node)
do {
cycle += other
other = parents(other)(node)
} while(other != node)
res += cycle.sorted
}
res.toSet
}
et une petite méthode principale juste pour tester le résultat
def main(args: Array[String]): Unit = {
val n = 3
val weights = Array(Array(NO_EDGE, 1, NO_EDGE), Array(NO_EDGE, NO_EDGE, 1), Array(1, NO_EDGE, NO_EDGE))
val parents = Array(Array(-1, 1, -1), Array(-1, -1, 2), Array(0, -1, -1))
shortestPathWithParentTracking(weights, parents)
val cycleNodes = parents.indices.filter(i => parents(i)(i) < NO_EDGE)
val cycles: Set[Seq[Int]] = recoverCycles(cycleNodes, parents)
println("The following minimal cycle found:")
cycles.foreach(c => println(c.mkString))
println(s"Total: ${cycles.size} cycle found")
}
et la sortie est
The following minimal cycle found:
012
Total: 1 cycle found