Moyen le plus rapide de vérifier si une valeur existe dans une liste
je cherche la façon la plus rapide de savoir si une valeur existe dans une liste (une liste avec des millions de valeurs) et quel est son index? Je sais que toutes les valeurs de la liste sont uniques comme mon exemple.
la première méthode que j'essaie est (3.8 sec dans mon code réel):
a = [4,2,3,1,5,6]
if a.count(7) == 1:
b=a.index(7)
"Do something with variable b"
la seconde méthode que j'essaie est (2X plus rapide:1,9 sec sur mon code réel):
a = [4,2,3,1,5,6]
try:
b=a.index(7)
except ValueError:
"Do nothing"
else:
"Do something with variable b"
proposition de méthodes de Stackoverflow utilisateur (2.74 sec sur mon vrai code):
a = [4,2,3,1,5,6]
if 7 in a:
a.index(7)
dans mon code réel, la première méthode prend 3,81 sec et la seconde 1,88 sec. C'est une bonne amélioration mais:
je suis un débutant avec Python / scripting et je veux savoir s'il existe un moyen le plus rapide de faire les mêmes choses et d'économiser plus de temps de processus?
explication plus spécifique pour ma demande:
dans L'API de blender a peut accéder à une liste de particules:
particles = [1,2,3,4...etc.]
de là, je peux accéder à son emplacement:
particles[x].location = [x,y,z]
et je teste pour chaque particule si un voisin existe en cherchant dans l'emplacement de chaque particule comme:
if [x+1,y,z] in particles.location
"find the identity of this neighbour particles in x:the index
of the particles array"
particles.index([x+1,y,z])
11 réponses
7 in a
la façon la plus claire et la plus rapide de le faire.
vous pouvez également envisager d'utiliser un set , mais construire cet ensemble à partir de votre liste peut prendre plus de temps que des tests d'adhésion plus rapides économiseront. La seule façon d'en être certain est de référence. (cela dépend également de quelles opérations vous avez besoin)
comme d'autres l'ont dit, in peut être très lent pour les grandes listes. Voici quelques comparaisons des performances pour in , set et bisect . Remarque le temps (en seconde) est en échelle logarithmique.
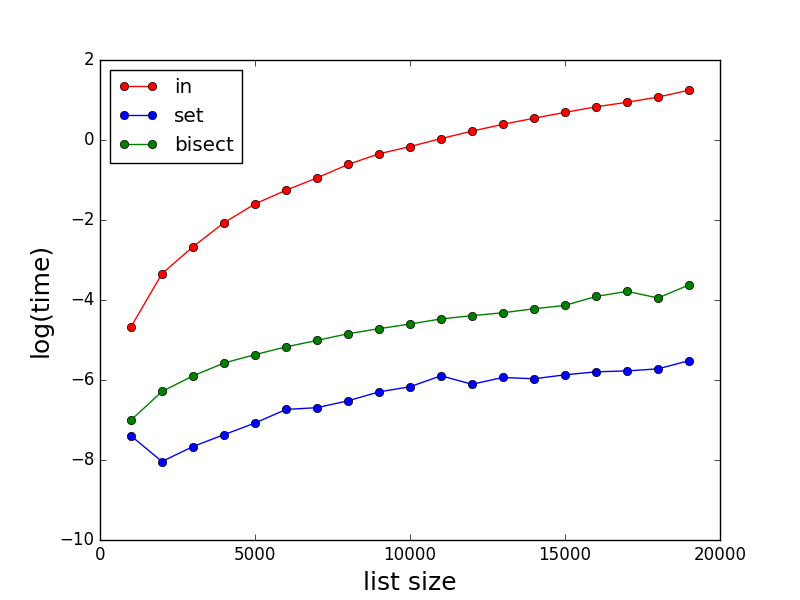
Code pour les essais:
import random
import bisect
import matplotlib.pyplot as plt
import math
import time
def method_in(a,b,c):
start_time = time.time()
for i,x in enumerate(a):
if x in b:
c[i] = 1
return(time.time()-start_time)
def method_set_in(a,b,c):
start_time = time.time()
s = set(b)
for i,x in enumerate(a):
if x in s:
c[i] = 1
return(time.time()-start_time)
def method_bisect(a,b,c):
start_time = time.time()
b.sort()
for i,x in enumerate(a):
index = bisect.bisect_left(b,x)
if index < len(a):
if x == b[index]:
c[i] = 1
return(time.time()-start_time)
def profile():
time_method_in = []
time_method_set_in = []
time_method_bisect = []
Nls = [x for x in range(1000,20000,1000)]
for N in Nls:
a = [x for x in range(0,N)]
random.shuffle(a)
b = [x for x in range(0,N)]
random.shuffle(b)
c = [0 for x in range(0,N)]
time_method_in.append(math.log(method_in(a,b,c)))
time_method_set_in.append(math.log(method_set_in(a,b,c)))
time_method_bisect.append(math.log(method_bisect(a,b,c)))
plt.plot(Nls,time_method_in,marker='o',color='r',linestyle='-',label='in')
plt.plot(Nls,time_method_set_in,marker='o',color='b',linestyle='-',label='set')
plt.plot(Nls,time_method_bisect,marker='o',color='g',linestyle='-',label='bisect')
plt.xlabel('list size', fontsize=18)
plt.ylabel('log(time)', fontsize=18)
plt.legend(loc = 'upper left')
plt.show()
def check_availability(element, collection: iter):
return element in collection
Utilisation
check_availability('a', [1,2,3,4,'a','b','c'])
je crois que c'est la façon la plus rapide de savoir si une valeur choisie est dans un tableau.
Vous pourriez mettre vos articles dans un set . Les recherches de configuration sont très efficaces.
, Essayez:
s = set(a)
if 7 in s:
# do stuff
modifier Dans un commentaire vous dites que vous aimeriez obtenir l'index de l'élément. Malheureusement, les ensembles n'ont aucune notion de la position de l'élément. Une alternative est de pré-trier votre liste et ensuite utiliser recherche binaire chaque fois que vous avez besoin de trouver un élément.
a = [4,2,3,1,5,6]
index = dict((y,x) for x,y in enumerate(a))
try:
a_index = index[7]
except KeyError:
print "Not found"
else:
print "found"
ce ne sera une bonne idée que si a ne change pas et donc nous pouvons faire la partie DCT() une fois et ensuite l'utiliser à plusieurs reprises. Si une modification, veuillez fournir plus de détails sur ce que vous faites.
il semble que votre application pourrait tirer avantage de l'utilisation d'une structure de données de filtre de fleur.
en bref, une recherche de filtre de fleur peut vous dire très rapidement si une valeur est certainement pas présent dans un ensemble. Sinon, vous pouvez faire une recherche plus lente pour obtenir l'index d'une valeur qui pourrait éventuellement être dans la liste. Donc si votre application tend à obtenir le résultat "not found" beaucoup plus souvent que le résultat "found", vous pourriez voir une accélération en ajoutant une fleur Filtrer.
pour plus de détails, Wikipedia fournit un bon aperçu du fonctionnement des filtres Bloom, et une recherche sur le web pour" Python bloom filter library " fournira au moins quelques implémentations utiles.
soyez conscient que l'opérateur in teste non seulement l'égalité ( == ) mais aussi l'identité ( is ), la logique in pour list s est à peu près équivalent à ce qui suit (il est en fait écrit en C et pas en Python cependant, au moins en CPython):
for element in s: if element is target: # fast check for identity implies equality return True if element == target: # slower check for actual equality return True return False
dans la plupart des circonstances ce détail n'est pas pertinent, mais dans certaines circonstances il pourrait laisser un novice de Python surpris, par exemple, numpy.NAN a la propriété inhabituelle d'être n'étant pas égal à lui-même :
>>> import numpy
>>> numpy.NAN == numpy.NAN
False
>>> numpy.NAN is numpy.NAN
True
>>> numpy.NAN in [numpy.NAN]
True
pour distinguer entre ces cas inhabituels, vous pouvez utiliser any() comme:
>>> lst = [numpy.NAN, 1 , 2]
>>> any(element == numpy.NAN for element in lst)
False
>>> any(element is numpy.NAN for element in lst)
True
Note la "logique 151940920" pour list s avec any() serait:
any(element is target or element == target for element in lst)
cependant, je dois souligner qu'il s'agit d'un cas extrême, et pour la grande majorité des cas l'opérateur in est très optimisé et exactement ce que vous voulez bien sûr (soit avec un list ou avec un set ).
ce n'est pas le code, mais l'algorithme pour une recherche très rapide""
si votre liste et la valeur que vous recherchez sont tous les nombres, c'est assez simple, si les chaînes: regardez au bas:
- - que " n "soit la longueur de votre liste
- - étape facultative: si vous avez besoin de l'index de l'élément: Ajouter une deuxième colonne à la liste avec l'index courant des éléments (0 à n-1) - Voir plus loin
- commandez votre liste ou une copie de celle-ci (.sort())
- boucle à travers:
- comparez votre nombre avec le N / 2ème élément de la liste
- si plus grand, boucle à nouveau entre les index n / 2-n
- si petit, la boucle est à nouveau entre les indices 0-n/2
- si le même: vous l'avez trouvé
- comparez votre nombre avec le N / 2ème élément de la liste
- continuez à rétrécir la liste jusqu'à ce que vous l'ayez trouvée. ou seulement à 2 chiffres (en dessous et au-dessus de la personne que vous cherchez)
- cela trouvera n'importe quel élément dans au plus 19 étapes pour une liste de 1.000.000 (log(2)n pour être précis)
si vous avez aussi besoin de la position originale de votre numéro, cherchez-la dans la deuxième colonne, index
si votre liste n'est pas faite de chiffres, la méthode fonctionne toujours et sera la plus rapide, mais vous devrez peut-être définir une fonction qui peuvent comparer / commander des chaînes
bien sûr, cela nécessite l'investissement de la méthode tried (), mais si vous continuez à réutiliser la même liste pour vérifier, cela peut valoir la peine
Pour moi, c'était 0.030 s(réel), 0.026 s(utilisateur) et 0.004 s(sys).
try:
print("Started")
x = ["a", "b", "c", "d", "e", "f"]
i = 0
while i < len(x):
i += 1
if x[i] == "e":
print("Found")
except IndexError:
pass
present = False
searchItem = 'd'
myList = ['a', 'b', 'c', 'd', 'e']
if searchItem in myList:
present = True
print('present = ', present)
else:
print('present = ', present)
pour vérifier si deux éléments existent dans un tableau dont le produit est égal à K.
n=len(arr1)
for i in arr1:
if k%i==0 :
print(i)