Estimation du petit décalage horaire entre deux séries chronologiques
j'ai deux séries chronologiques, et je soupçonne qu'il y a un décalage horaire entre eux, et je veux estimer ce décalage horaire.
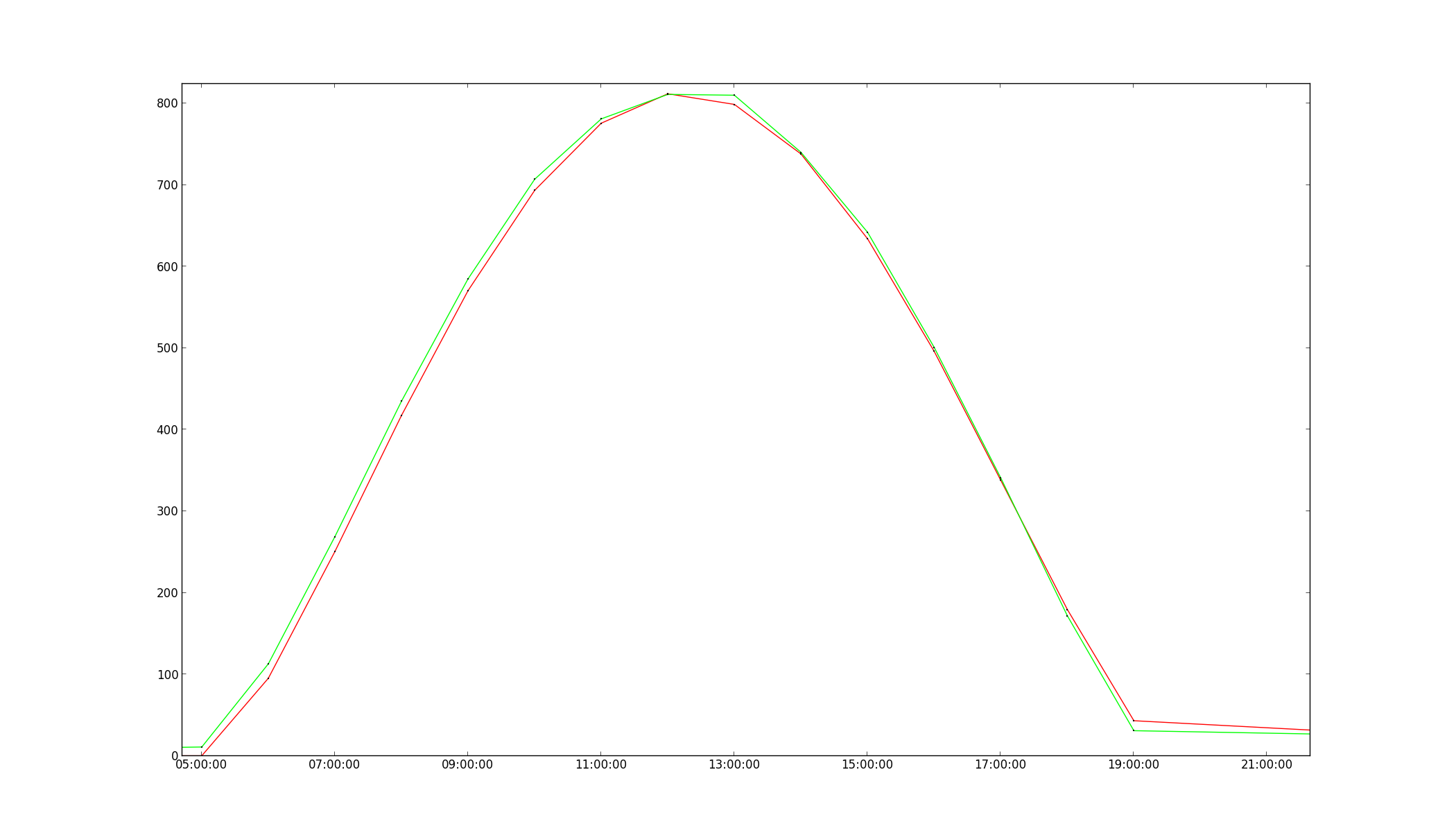
cette question a déjà été posée en: Trouver la différence de phase entre les deux (inharmoniques) des ondes et trouver le temps de décalage entre les deux formes d'onde mais dans mon cas, le décalage est plus petite que la résolution des données. par exemple, les données sont disponibles à une résolution horaire, et le le décalage horaire n'est que de quelques minutes(voir image).
la cause de cela est que le datalogger utilisé pour mesurer l'une des séries a quelques minutes de décalage dans son temps.
y a-t-il des algorithmes là-bas qui puissent estimer ce décalage, de préférence sans recourir à l'interpolation?
6 réponses
C'est un problème intéressant. Voici une tentative de solution partielle en utilisant des transformées de fourier. Cela suppose que les données soient modérément périodiques. Je ne suis pas sûr que cela fonctionnera avec vos données (où les dérivés Aux points terminaux ne semblent pas correspondre).
import numpy as np
X = np.linspace(0,2*np.pi,30) #some X values
def yvals(x):
return np.sin(x)+np.sin(2*x)+np.sin(3*x)
Y1 = yvals(X)
Y2 = yvals(X-0.1) #shifted y values
#fourier transform both series
FT1 = np.fft.fft(Y1)
FT2 = np.fft.fft(Y2)
#You can show that analyically, a phase shift in the coefficients leads to a
#multiplicative factor of `exp(-1.j * N * T_d)`
#can't take the 0'th element because that's a division by 0. Analytically,
#the division by 0 is OK by L'hopital's<sp?> rule, but computers don't know calculus :)
print np.log(FT2[1:]/FT1[1:])/(-1.j*np.arange(1,len(X)))
une inspection rapide de la sortie imprimée montre que les fréquences avec le plus puissance (N = 1, N = 2) donnent des estimations raisonnables, N = 3 fait OK aussi si vous regardez valeur absolue (np.absolute), bien que je ne sois pas en mesure d'expliquer pourquoi.
peut-être que quelqu'un de plus familier avec les maths peut s'en servir pour donner une meilleure réponse...
un des liens que vous avez fourni a la bonne idée (en fait je fais à peu près la même chose ici)
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import correlate
a,b, N = 0, 10, 1000 #Boundaries, datapoints
shift = -3 #Shift, note 3/10 of L = b-a
x = np.linspace(a,b,N)
x1 = 1*x + shift
time = np.arange(1-N,N) #Theoritical definition, time is centered at 0
y1 = sum([np.sin(2*np.pi*i*x/b) for i in range(1,5)])
y2 = sum([np.sin(2*np.pi*i*x1/b) for i in range(1,5)])
#Really only helps with large irregular data, try it
# y1 -= y1.mean()
# y2 -= y2.mean()
# y1 /= y1.std()
# y2 /= y2.std()
cross_correlation = correlate(y1,y2)
shift_calculated = time[cross_correlation.argmax()] *1.0* b/N
y3 = sum([np.sin(2*np.pi*i*(x1-shift_calculated)/b) for i in range(1,5)])
print "Preset shift: ", shift, "\nCalculated shift: ", shift_calculated
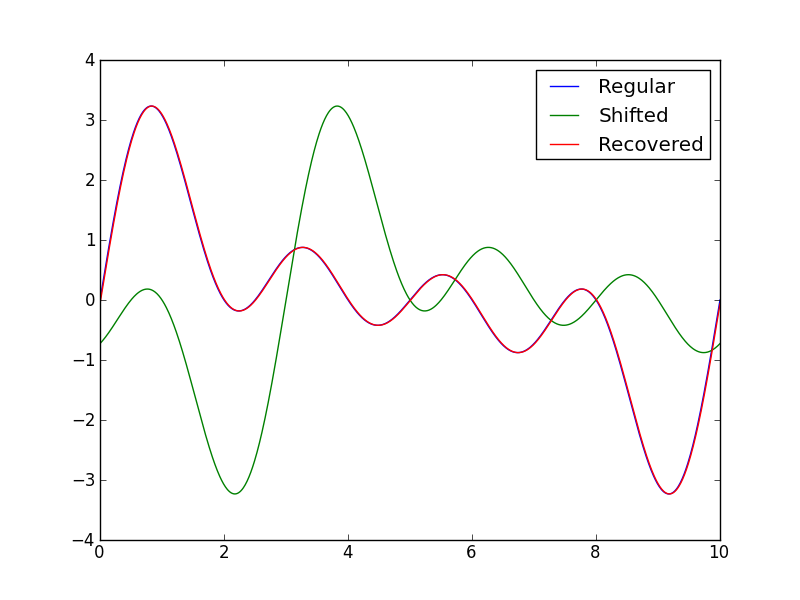
plt.plot(x,y1)
plt.plot(x,y2)
plt.plot(x,y3)
plt.legend(("Regular", "Shifted", "Recovered"))
plt.savefig("SO_timeshift.png")
plt.show()
la sortie est la suivante:
Preset shift: -3
Calculated shift: -2.99
il pourrait être nécessaire de vérifier
Notez que argmax() de la corrélation indique la position de l'alignement, il doit être multipliée par la longueur de la b-a = 10-0 = 10 et N pour obtenir la valeur réelle.
Vérification de la source de corrélation Source il n'est pas évident que la fonction importée à partir d'sigtools se comporte. Pour les grands ensembles de données, la corrélation circulaire (via les transformées de Fourier rapides) est beaucoup plus rapide que la méthode simple. Je suppose que c' est ce qui est mis en œuvre dans sigtools mais je ne peux pas le dire avec certitude. Une recherche du fichier dans mon python2.7 folder n'a retourné que le fichier COPY compilé.
C'est un problème intéressant. À l'origine, j'allais Suggérer une solution basée sur une corrélation croisée similaire à celle de l'utilisateur 948652. Toutefois, d'après votre Description du problème, il y a deux problèmes avec cette solution:
- la résolution des données est plus grande que le décalage horaire, et
- certains jours, la valeur prédite et les valeurs mesurées ont une très faible corrélation l'une avec l'autre
Comme un résultat de ces deux questions, je pense que l'Application directe de la solution de corrélation croisée est susceptible d'augmenter votre décalage horaire, en particulier les jours où les valeurs prédites et mesurées ont une corrélation très faible les unes par rapport aux autres.
dans mon commentaire ci-dessus, j'ai demandé si vous aviez des événements qui se produisent dans les deux séries chronologiques, et vous avez dit que vous ne le faites pas. Cependant, d'après votre domaine, je pense que vous en avez deux:
- Lever de soleil
- Coucher de soleil
même si le reste du signal est faiblement corrélé, le lever et le coucher du soleil devraient être quelque peu corrélés, puisqu'ils augmenteront ou diminueront de façon monotone par rapport à la base de nuit. Voici donc une solution potentielle, basée sur ces deux événements, qui devrait à la fois minimiser l'interpolation nécessaire, et ne pas dépendre de la corrélation croisée de signaux mal corrélés.
1. Find approximatif Sunrise / Sunset
cela devrait être assez facile, il suffit de prendre le premier et le dernier point de données qui sont plus élevés que la ligne plate de temps de nuit, et étiqueter ceux-ci le lever et le coucher du soleil approximatifs. Ensuite, je me concentrerai sur ces données, ainsi que sur les points immédiatement de chaque côté, à savoir:
width=1
sunrise_index = get_sunrise()
sunset_index = get_sunset()
# set the data to zero, except for the sunrise/sunset events.
bitmap = zeros(data.shape)
bitmap[sunrise_index - width : sunrise_index + width] = 1
bitmap[sunset_index - width : sunset_index + width] = 1
sunrise_sunset = data * bitmap
il y a plusieurs façons de mettre en œuvre get_sunrise() et get_sunset() en fonction de combien de rigueur vous besoin de votre analyse. J'utiliserais numpy.diff , le seuil à une valeur spécifique, et prendre le premier et le dernier point au-dessus de cette valeur. Vous pouvez également lire les données de nuit dans à partir d'un grand nombre de fichiers, calculer la moyenne et l'écart-type, et chercher les premiers et les derniers points de données qui dépassent, disons, 0.5 * st_dev des données de nuit. Vous pouvez également faire une sorte de correspondance de modèle basée sur les clusters, en particulier si différentes classes de jour (i.e., ensoleillé vs. partiellement nuageux vs. très nuageux) présentent des épisodes très stéréotypés de lever et de coucher du soleil.
2. Rééchantillonnage Des Données
Je ne pense pas qu'il y ait un moyen de résoudre ce problème sans une certaine interpolation. Je voudrais rééchantillonner les données à un taux d'échantillonnage plus élevé que le changement. Si le décalage est à l'échelle des minutes, passez à 1 minute ou 30 secondes.
num_samples = new_sample_rate * sunrise_sunset.shape[0]
sunrise_sunset = scipy.signal.resample(sunrise_sunset, num_samples)
alternativement, nous pourrions utilisez une spline cubique pour interpoler les données (voir ici ).
3. Convolution Gaussienne
Puisqu'il y a une interpolation, alors nous ne savons pas avec quelle précision le lever et le coucher du soleil ont été prédits. Donc, nous pouvons résoudre le signal avec un gaussien, pour représenter cette incertitude.
gaussian_window = scipy.signal.gaussian(M, std)
sunrise_sunset_g = scipy.signal.convolve(sunrise_sunset, gaussian_window)
4. Corrélation Croisée
utilisez la méthode de corrélation croisée dans la réponse de l'utilisateur 948652 pour obtenir le décalage horaire.
il y a beaucoup de questions sans réponse dans cette méthode qui nécessiteraient l'examen et l'expérimentation des données pour plus spécifiquement clouer vers le bas, comme ce qui est la meilleure méthode pour identifier le lever/coucher du soleil, la largeur de la fenêtre gaussienne devrait être, etc. Mais c'est comme ça que je commencerais à attaquer le problème. Bonne chance!
en effet, problème intéressant, mais pas de réponse satisfaisante encore. Essayons de changer cela...
vous dites que vous préférez ne pas utiliser l'interpolation, mais, comme je comprends de votre commentaire, ce que vous voulez vraiment dire, c'est que vous voulez éviter de remonter à une résolution plus élevée. Une solution de base utilise un ajustement des moindres carrés avec une fonction d'interpolation linéaire, mais sans upsampling à une résolution plus élevée:
import numpy as np
from scipy.interpolate import interp1d
from scipy.optimize import leastsq
def yvals(x):
return np.sin(x)+np.sin(2*x)+np.sin(3*x)
dx = .1
X = np.arange(0,2*np.pi,dx)
Y = yvals(X)
unknown_shift = np.random.random() * dx
Y_shifted = yvals(X + unknown_shift)
def err_func(p):
return interp1d(X,Y)(X[1:-1]+p[0]) - Y_shifted[1:-1]
p0 = [0,] # Inital guess of no shift
found_shift = leastsq(err_func,p0)[0][0]
print "Unknown shift: ", unknown_shift
print "Found shift: ", found_shift
Un exemple d'exécution donne une solution assez précise:
Unknown shift: 0.0695701123582
Found shift: 0.0696105501967
si l'on inclut le bruit dans le Y décalé:
Y_shifted += .1*np.random.normal(size=X.shape)
on obtient des résultats un peu moins précis:
Unknown shift: 0.0695701123582
Found shift: 0.0746643381744
la précision en présence de bruit s'améliore lorsque davantage de données sont disponibles, p.ex. avec:
X = np.arange(0,200*np.pi,dx)
un résultat typique est:
Unknown shift: 0.0695701123582
Found shift: 0.0698527939193
j'ai utilisé avec succès (dans le canal awgn) l'approche de filtre apparié, qui donne l'énergie de crête m[n] à l'indice n; puis ajuster un polynôme de 2ème degré f(n) à m[n-1], m[n], m[n+1] et trouver le minimum en réglant f'(n)==0.
La réponse n'est pas nécessairement absolument linéaire, surtout si l'autocorrélation du signal n'est pas s'évanouir à m[n-1], m[n+1].
Optimiser pour la meilleure solution
pour les contraintes données, à savoir que la solution est décalée d'une faible quantité par rapport à la méthode d'échantillonnage, un algorithme simple de downhill simplex fonctionne bien. J'ai modifié le problème d'échantillon de @mgilson pour montrer comment faire cela. Notez que cette solution est robuste, en ce qu'elle peut gérer le bruit.
fonction D'erreur : il peut y avoir des choses plus optimales à optimiser, mais cela fonctionne étonnamment bien:
np.sqrt((X1-X2+delta_x)**2+(Y1-Y2)**2).sum()
, c'est-à-dire réduire au minimum la distance euclidienne entre les deux courbes en n'ajustant que l'axe des abscisses (phase).
import numpy as np
def yvals(x):
return np.sin(x)+np.sin(2*x)+np.sin(3*x)
dx = .1
unknown_shift = .03 * np.random.random() * dx
X1 = np.arange(0,2*np.pi,dx) #some X values
X2 = X1 + unknown_shift
Y1 = yvals(X1)
Y2 = yvals(X2) # shifted Y
Y2 += .1*np.random.normal(size=X1.shape) # now with noise
def err_func(p):
return np.sqrt((X1-X2+p[0])**2+(Y1-Y2)**2).sum()
from scipy.optimize import fmin
p0 = [0,] # Inital guess of no shift
found_shift = fmin(err_func, p0)[0]
print "Unknown shift: ", unknown_shift
print "Found shift: ", found_shift
print "Percent error: ", abs((unknown_shift-found_shift)/unknown_shift)
un essai d'échantillon donne:
Optimization terminated successfully.
Current function value: 4.804268
Iterations: 6
Function evaluations: 12
Unknown shift: 0.00134765446268
Found shift: 0.001375
Percent error: -0.0202912082305