erreurs elasticsearch / kibana " données trop importantes, les données pour [@timestamp] seraient supérieures à la limite
sur mon faisceau D'élan d'essai, je rencontre l'erreur suivante en essayant de voir les données de la semaine dernière.
Data too large, data for [@timestamp] would be larger than limit
la mise en garde contre la défaillance des fragments semble être trompeuse parce que les outils de suivi elasticsearch kopf et head montrer que tous les éclats fonctionnent correctement, et que le faisceau élastique est vert.
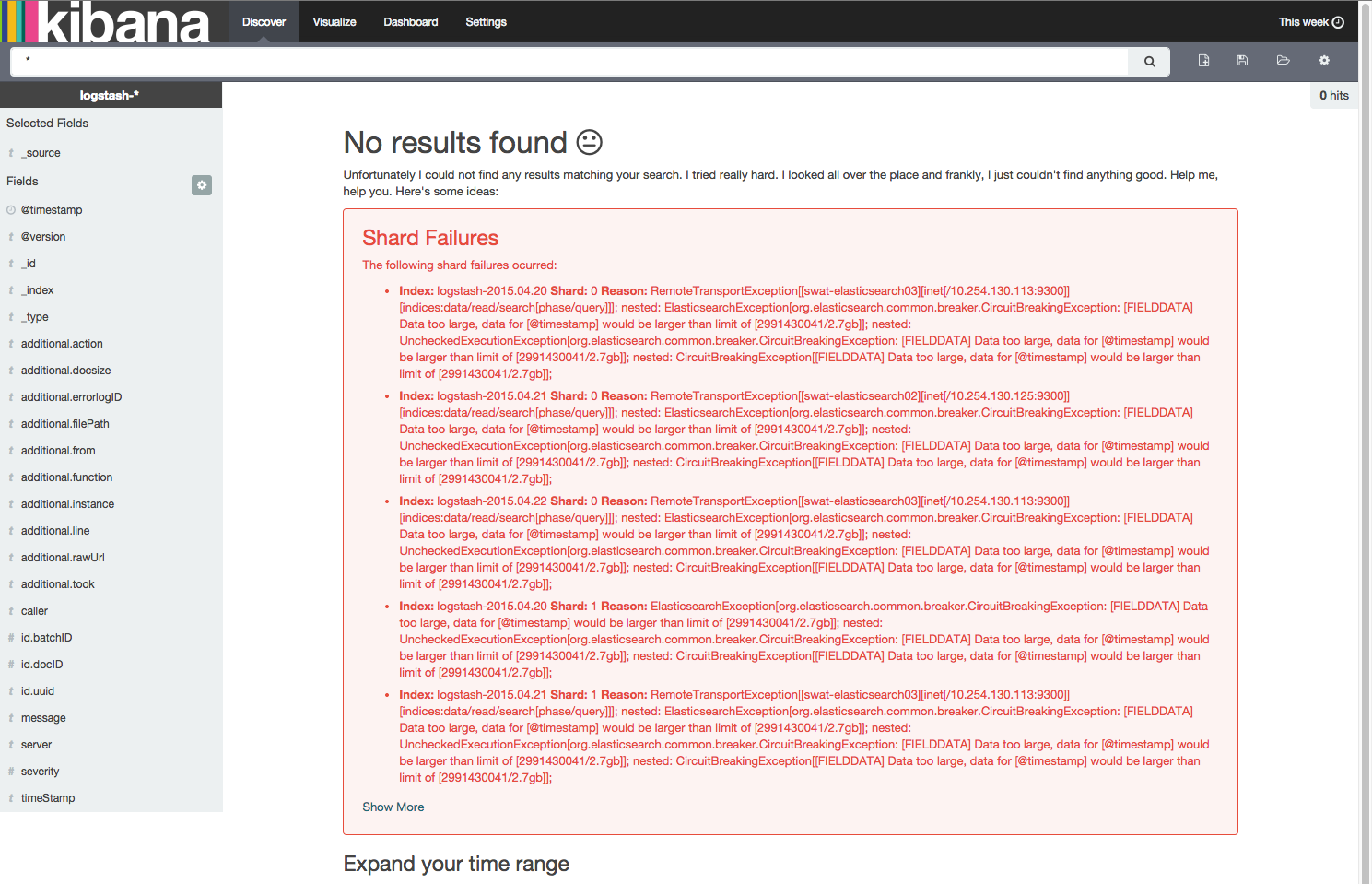
un utilisateur du groupe google pour elasticsearch a suggéré d'augmenter la ram. J'ai augmenté mes 3 noeuds à 8 Go chacun avec un tas de 4,7 Go, mais le problème persiste. Je génère environ 5 Go à 25 Go de données par jour, avec une rétention de 30 jours.
2 réponses
le nettoyage de la cache atténue les symptômes pour l'instant.
http://www.elastic.co/guide/en/elasticsearch/reference/current/indices-clearcache.html
effacer un seul index
curl -XPOST 'http://localhost:9200/twitter/_cache/clear'
Effacer plusieurs indicies
curl -XPOST 'http://localhost:9200/kimchy,elasticsearch/_cache/clear'
curl -XPOST 'http://localhost:9200/_cache/clear'
Ou comme suggéré par un utilisateur dans l'IRC. Celui-ci semble le meilleur travail.
curl -XPOST 'http://localhost:9200/_cache/clear' -d '{ "fielddata": "true" }'
Le nettoyage de la cache n'a pas fonctionné pour notre cluster. Lors de la vérification des différents noeuds en utilisant l'un donnait l'erreur ci-dessus et les autres avaient des erreurs de pointeur invalides. J' redémarré le service élastique sur celui donnant la limite de taux/données trop grande erreur. Quand il est revenu en ligne il y avait quelques fragments non assignés, que j'ai corrigé en laissant tomber le nombre de réplication à un nombre inférieur (seulement besoin de faire cela sur l'un des les nœuds de modifier les paramètres d'indexation pour le cluster):
IFS=$'\n'
for line in $(curl -s 'elastic-search.example.com:9200/_cat/shards' | fgrep UNASSIGNED); do
INDEX=$(echo $line | (awk '{print }'))
echo start $INDEX
curl -XPUT "elastic-search.example.com:9200/$INDEX/_settings" -d '{
"index" : {
"number_of_replicas" : 1
}
}
'
done
# Check shard/cluster status (may take some time to rebalance):
# http://elastic-search.example.com:9200/_cat/shards?v&s=index:desc
# http://elastic-search.example.com:9200/_cluster/health?pretty
aussi https://discuss.elastic.co/t/data-too-large/32141 semble mentionner qu'il peut s'agir d'un problème avec la taille du tas JVM.