Division efficace en virgule flottante avec des diviseurs entiers constants
a recent question , si les compilateurs sont autorisés à remplacer la division à virgule flottante par la multiplication à virgule flottante, m'a inspiré à poser cette question.
selon l'exigence stricte, que les résultats après transformation du code doivent être identiques en bits à l'opération de division réelle,
il est trivial de voir que pour l'IEEE-754 arithmétique binaire, cela est possible pour les diviseurs qui sont une puissance de deux. Tant que le réciproque
de le diviseur est représentable, en multipliant par l'inverse du diviseur donne des résultats identiques à la division. Par exemple, la multiplication par 0.5 peut remplacer la division par 2.0 .
on se demande alors pour quels autres diviseurs de tels remplacements fonctionnent, en supposant que nous permettons n'importe quelle séquence d'instruction courte qui remplace la division mais fonctionne beaucoup plus rapidement, tout en livrant des résultats bit-identiques. En particulier permettre Fusionné Multiplier-Ajouter opérations en plus de la simple multiplication. Dans mes observations, j'ai attiré l'attention sur le document pertinent suivant:
Nicolas Brisebarre, Jean-Michel Muller, et Saurabh Kumar Raina. L'accélération arrondie division flottante lorsque le diviseur est connu à l'avance. IEEE Transactions on Computers, Vol. 53, No.8, August 2004, pp.
La technique préconisée par les auteurs de l'article précalcule les réciproque de la division y comme un normalisée tête-à-queue paire z h :z l comme suit: z h = 1 / y, z l = fma (y, z h , 1) / y . Plus tard, la division q = x /y est alors calculée comme q = fma (z h , x, z l * x) . L'article dérive diverses conditions que le diviseur y doit satisfaire pour cet algorithme de travailler. Comme on l'observe facilement, cet algorithme a des problèmes avec les infinités et zéro lorsque les signes de la tête et de la queue diffèrent. Plus important encore, il ne fournira pas de résultats corrects pour les dividendes x qui sont de très faible ampleur, parce que le calcul de la queue du quotient, z l * x , souffre de sous-débit.
Le papier fait aussi le passage d'une référence à un autre FMA-division basée sur l'algorithme, mis au point par Peter Markstein, quand il était à IBM. La référence pertinente est:
P. W. Markstein. Calcul des fonctions élémentaires sur le processeur IBM RISC System / 6000. IBM Journal de Recherche & Développement, Vol. 34, N ° 1, janvier 1990, pp. 111-119
In L'algorithme de Markstein, on calcule d'abord un réciproque rc , à partir duquel un quotient initial q = x * rc est formé. Ensuite, le reste de la division est calculé avec précision avec un FMA comme r = fma (-y, q , x) , et un quotient amélioré et plus précis est finalement calculé comme q = FMA (r, rc, q) .
cet algorithme a aussi des problèmes pour x qui sont des zéros ou des infinités (facilement travaillés autour avec l'exécution conditionnelle appropriée), mais des tests exhaustifs utilisant IEEE-754 simple-précision float données montre qu'il délivre le quotient correct à travers tous les dividendes possibles x pour de nombreux diviseurs y , parmi ces nombreux petits entiers. Ce code C le met en œuvre:
/* precompute reciprocal */
rc = 1.0f / y;
/* compute quotient q=x/y */
q = x * rc;
if ((x != 0) && (!isinf(x))) {
r = fmaf (-y, q, x);
q = fmaf (r, rc, q);
}
sur la plupart des architectures de processeurs, cela devrait se traduire par un sans branchement séquence d'instructions, en utilisant soit la prédication, les mouvements conditionnels, ou des instructions de type select. Pour donner un exemple concret: pour la division par 3.0f , le compilateur nvcc de CUDA 7.5 génère le code machine suivant pour un GPU de la classe Kepler:
LDG.E R5, [R2]; // load x
FSETP.NEU.AND P0, PT, |R5|, +INF , PT; // pred0 = fabsf(x) != INF
FMUL32I R2, R5, 0.3333333432674408; // q = x * (1.0f/3.0f)
FSETP.NEU.AND P0, PT, R5, RZ, P0; // pred0 = (x != 0.0f) && (fabsf(x) != INF)
FMA R5, R2, -3, R5; // r = fmaf (q, -3.0f, x);
MOV R4, R2 // q
@P0 FFMA R4, R5, c[0x2][0x0], R2; // if (pred0) q = fmaf (r, (1.0f/3.0f), q)
ST.E [R6], R4; // store q
pour mes expériences, j'ai écrit le programme de test minuscule C montré ci-dessous que les étapes à travers les diviseurs entiers dans l'ordre croissant et pour chacun d'eux teste exhaustivement la séquence de code ci-dessus contre le bonne division. Il imprime une liste des diviseurs que passé ce test exhaustif. La sortie partielle ressemble à ce qui suit:
PASS: 1, 2, 3, 4, 5, 7, 8, 9, 11, 13, 15, 16, 17, 19, 21, 23, 25, 27, 29, 31, 32, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 64, 65, 67, 69,
pour incorporer l'algorithme de remplacement dans un compilateur comme une optimisation, une liste blanche de diviseurs à laquelle la transformation de code ci-dessus peut être appliquée en toute sécurité est impraticable. La sortie du programme jusqu'à présent (à un taux d'environ un résultat par minute) suggère que le jeûne code fonctionne correctement dans tous les encodages possibles de x pour les diviseurs y qui sont des entiers impairs ou sont des pouvoirs de deux. Les preuves anecdotiques, pas une preuve, bien sûr.
quel ensemble de conditions mathématiques peut déterminer a priori si la transformation de la division dans la séquence de code ci-dessus est sûre? Répond peut supposer que toutes les opérations à virgule flottante sont effectuées dans le mode d'arrondi par défaut de "tour la plus proche, ou encore".
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
int main (void)
{
float r, q, x, y, rc;
volatile union {
float f;
unsigned int i;
} arg, res, ref;
int err;
y = 1.0f;
printf ("PASS: ");
while (1) {
/* precompute reciprocal */
rc = 1.0f / y;
arg.i = 0x80000000;
err = 0;
do {
/* do the division, fast */
x = arg.f;
q = x * rc;
if ((x != 0) && (!isinf(x))) {
r = fmaf (-y, q, x);
q = fmaf (r, rc, q);
}
res.f = q;
/* compute the reference, slowly */
ref.f = x / y;
if (res.i != ref.i) {
err = 1;
break;
}
arg.i--;
} while (arg.i != 0x80000000);
if (!err) printf ("%g, ", y);
y += 1.0f;
}
return EXIT_SUCCESS;
}
4 réponses
laissez-moi recommencer pour la troisième fois. Nous essayons d'accélérer
q = x / y
où y est une constante entière, et q , x , et y sont toutes IEEE 754-2008 binary32 valeurs à virgule flottante. Ci-dessous, fmaf(a,b,c) indique un ajout multiple fusionné a * b + c en utilisant les valeurs binary32.
l'algorithme naïf est via un réciproque précalculé,
C = 1.0f / y
de sorte qu'à l'exécution une multiplication (beaucoup plus rapide) suffit:
q = x * C
l'accélération Brisebarre-Muller-Raina utilise deux constantes prédéfinies,
zh = 1.0f / y
zl = -fmaf(zh, y, -1.0f) / y
de sorte qu'à l'exécution, une multiplication et une fusion de Multiplier-Ajouter suffisent:
q = fmaf(x, zh, x * zl)
l'algorithme de Markstein combine l'approche naïve avec deux additions multiples fusionnées qui donne le résultat correct si la naïve l'approche donne un résultat à l'intérieur d'une unité à l'endroit le moins significatif, en précalculant
C1 = 1.0f / y
C2 = -y
de sorte que le divison peut être approximé en utilisant
t1 = x * C1
t2 = fmaf(C1, t1, x)
q = fmaf(C2, t2, t1)
L'approche naïve fonctionne pour tous les pouvoirs de deux y , mais autrement il est assez mauvais. Par exemple, pour les diviseurs 7, 14, 15, 28, et 30, il donne un résultat incorrect pour plus de la moitié de tout possible x .
l'approche Brisebarre-Muller-Raina échoue de la même façon pour presque toute la non-puissance de deux y , mais beaucoup moins x donner le résultat incorrect (moins d'un demi-pour cent de tout possible x , varie en fonction de y ).
l'article de Brisebarre-Muller-Raina montre que l'erreur maximale dans l'approche naïve est de ±1,5 ULPs.
L'approche de Markstein donne des résultats corrects pour des puissances de deux y , et aussi pour Impair entier y . (Je n'ai pas trouvé de diviseur d'entier impair défaillant pour L'approche de Markstein.)
pour L'approche de Markstein, j'ai analysé les diviseurs 1 - 19700 ( données brutes ici ).
traçant le nombre de cas de défaillance (diviseur dans l'axe horizontal, le nombre de valeurs de x où L'approche de Markstein échoue pour ledit diviseur), nous pouvons voir un le modèle simple de se produire:
Markstein cas d'insuffisance http://www.nominal-animal.net/answers/markstein.png
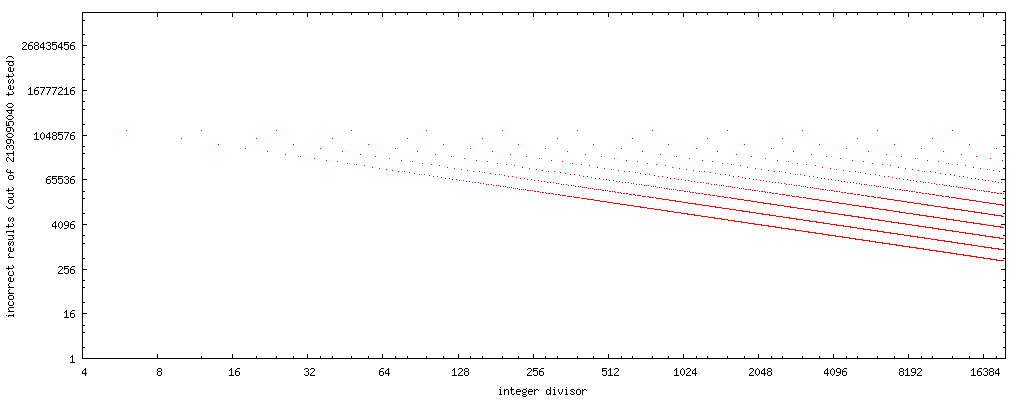{kind=link}
noter que ces tracés ont des axes à la fois horizontaux et verticaux logarithmique. Il n'y a pas de points pour les diviseurs impairs, car l'approche donne des résultats corrects pour tous les diviseurs impairs que j'ai testés.
si nous changeons l'axe des x en bit inverse (chiffres binaires dans l'ordre inverse, i.e. 0b11101101 → 0b10110111, données ) des diviseurs, nous avons un patron très clair: Markstein cas d'insuffisance, le bit inverse du diviseur http://www.nominal-animal.net/answers/markstein-failures.png
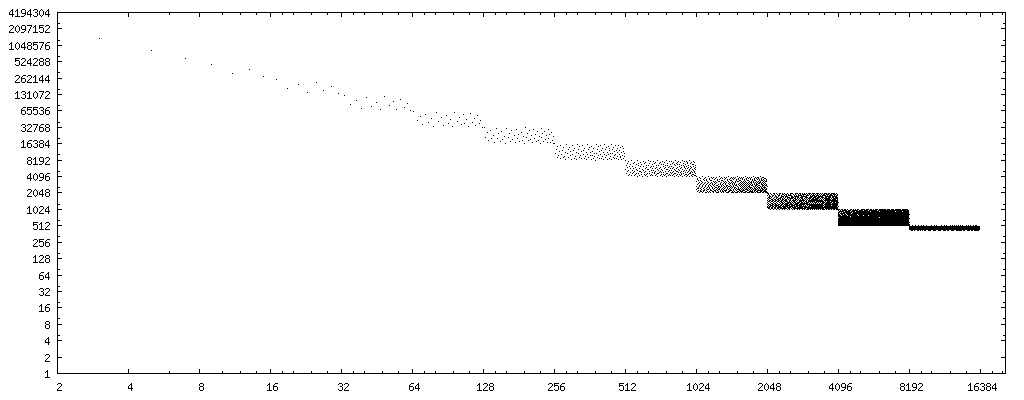{kind=link}
si nous traçons une ligne droite à travers le centre des ensembles de points, nous obtenons la courbe 4194304/x . (Rappelez-vous, l'intrigue ne considère que la moitié des flotteurs possibles, donc en considérant tous les flotteurs possibles, doublez-le.)
8388608/x et 2097152/x bracket le motif d'erreur entier complètement.
ainsi, si nous utilisons rev(y) pour calculer le bit inverse du diviseur y , alors 8388608/rev(y) est une bonne approximation de premier ordre du nombre de cas (de tous les flotteurs possibles) où L'approche de Markstein donne un résultat incorrect pour un diviseur pair, non-puissance-de-deux y . (Ou, 16777216/rev(x) pour la limite supérieure.)
ajouté le 2016-02-28: j'ai trouvé une approximation pour le nombre de cas d'erreur utilisant L'approche de Markstein, compte tenu de tout diviseur integer (binary32). Ici, c'est comme un pseudo:
function markstein_failure_estimate(divisor):
if (divisor is zero)
return no estimate
if (divisor is not an integer)
return no estimate
if (divisor is negative)
negate divisor
# Consider, for avoiding underflow cases,
if (divisor is very large, say 1e+30 or larger)
return no estimate - do as division
while (divisor > 16777216)
divisor = divisor / 2
if (divisor is a power of two)
return 0
if (divisor is odd)
return 0
while (divisor is not odd)
divisor = divisor / 2
# Use return (1 + 83833608 / divisor) / 2
# if only nonnegative finite float divisors are counted!
return 1 + 8388608 / divisor
cela donne une estimation correcte de l'erreur à ±1 près sur les cas D'échec de Markstein que j'ai testés (mais je n'ai pas encore testé correctement les diviseurs supérieurs à 8388608). La division finale doit être telle qu'elle ne rapporte pas de faux zéros, mais je ne peux pas la garantir (encore). Il ne tient pas compte des diviseurs de très grande taille (disons 0x1p100, ou 1e + 30, et plus grand dans la grandeur) qui ont des problèmes de sous-flux -- Je voudrais certainement exclure de tels diviseurs de l'accélération de toute façon.
dans les essais préliminaires, l'estimation semble étrangement exacte. Je n'ai pas Tracé de graphique comparant les estimations et les erreurs réelles pour les diviseurs 1 à 20000, parce que tous les points coïncident exactement dans les graphiques. (Dans cette gamme, l'estimation est exacte, ou un trop grand.) Essentiellement, les estimations reproduisent la première parcelle de cette réponse exactement.
le schéma des échecs pour L'approche de Markstein est régulier, et très intéressant. L'approche fonctionne pour toute la puissance de deux diviseurs, et tous les diviseurs entiers impairs.
pour les diviseurs supérieurs à 16777216, je vois toujours les mêmes erreurs que pour un diviseur qui est divisé par la plus petite puissance de deux pour produire une valeur inférieure à 16777216. Par exemple, 0x1.3cdfa4p+23 et 0x1.3cdfa4p+41, 0x1.d8874p+23 et 0 x 1.d8874p+32, 0x1.cf84f8p+23 et 0x1.cf84f8p+34, 0x1.e4a7fp+23 et 0x1.e4a7fp+37. (Dans chaque paire, le mantissa est le même, et seulement le pouvoir de deux varie.)
en supposant que mon banc d'essai n'est pas dans l'erreur, cela signifie que L'approche de Markstein fonctionne aussi diviseurs plus grand que 16777216 en grandeur (mais plus petit que, disons, 1e+30), si le diviseur est tel que lorsqu'il est divisé par la plus petite puissance de deux qui donne un quotient de moins de 16777216 en grandeur, et le le quotient est étrange.
cette question demande un moyen d'identifier les valeurs de la constante Y qui permettent de transformer en toute sécurité x / Y en un calcul moins coûteux en utilisant FMA pour toutes les valeurs possibles de x . Une autre approche consiste à utiliser l'analyse statique pour déterminer une sur-approximation des valeurs x peut prendre, de sorte que la transformation généralement malsaine peut être appliquée en sachant que les valeurs pour lesquelles le code transformé diffère de la division originale ne ne pas se produire.
en utilisant des représentations d'ensembles de valeurs à virgule flottante qui sont bien adaptées aux problèmes des calculs à virgule flottante, même une analyse prospective à partir du début de la fonction peut produire des informations utiles. Par exemple:
float f(float z) {
float x = 1.0f + z;
float r = x / Y;
return r;
}
en supposant le mode par défaut (*), dans la fonction ci-dessus x peut seulement être NaN (si l'entrée est NaN), +0.0 f, ou un nombre plus grand que 2 -24 en magnitude, mais pas -0,0 f ou quelque chose de plus proche de zéro que 2 -24 . Cela justifie la transformation en l'une des deux formes indiquées dans la question pour de nombreuses valeurs de la constante Y .
( * ) hypothèse sans laquelle de nombreuses optimisations sont impossibles et que les compilateurs C font déjà à moins que le programme n'utilise explicitement #pragma STDC FENV_ACCESS ON
avant l'analyse statique qui prédit l'information pour x ci-dessus peut être basé sur une représentation des ensembles de valeurs flottantes une expression peut prendre comme un tuple de:
- une représentation pour les ensembles de valeurs possibles de NaN (puisque les comportements de NaN sont sous-spécifiés, un choix est d'utiliser seulement un booléen, avec
truesignifiant que certains NaNs peuvent être présents, etfalseindiquant qu'aucun nan n'est présent.), - quatre drapeaux booléens indiquant respectivement la présence de +inf, -inf, +0.0, -0.0,
- inclusif intervalle de négatif finis les valeurs à virgule flottante, et
- inclusif intervalle de positif finis les valeurs à virgule flottante.
pour suivre cette approche, toutes les opérations à virgule flottante qui peuvent se produire dans un programme C doivent être comprises par l'analyseur statique. Pour illustrer, l'addition entre les ensembles de valeurs U et V, à utiliser pour gérer + dans le code analysé, peut être mis en œuvre comme:
- Si NaN est présent dans l'un des opérandes, ou si les opérandes peuvent être infinis de signes opposés, NaN est présent dans le résultat.
- Si 0 ne peut être le résultat de l'addition d'une valeur de U et D'une valeur de V, utiliser l'arithmétique d'intervalle standard. La limite supérieure du résultat est obtenue pour l'addition arrondie à la plus proche de la plus grande valeur en U et de la plus grande valeur dans V, donc ces limites doivent être calculées avec rond-à-plus proche.
- Si 0 peut être le résultat de L'addition D'une valeur positive de U et d'une valeur négative de V, alors que M soit la plus petite valeur positive en U telle que-M soit présent en V.
- si succ(M) est présent en U, alors cette paire de valeurs contribue succ(M) - M aux valeurs positives du résultat.
- si-succ( M) est présent en V, alors cette paire de valeurs contribue la valeur négative m-succ (M) aux valeurs négatives du résultat.
- si pred(M) est présent en U, alors cette paire de valeurs contribue la valeur négative pred (M) - M aux valeurs négatives du résultat.
- si-pred(M) est présent en V, alors cette paire de valeurs apporte la valeur M - pred (M) aux valeurs positives du résultat.
- faire le même travail si 0 peut être le résultat de l'addition d'une valeur négative de U et d'une valeur positive de V. 1519410920"
Reconnaissance: ce qui précède emprunte des idées de" Improving the Floating Point Addition and soustraction Constraints", Bruno Marre & Claude Michel
exemple: compilation de la fonction f ci-dessous:
float f(float z, float t) {
float x = 1.0f + z;
if (x + t == 0.0f) {
float r = x / 6.0f;
return r;
}
return 0.0f;
}
l'approche dans la question refuse de transformer la division en fonction f en un forme alternative, parce que 6 n'est pas une de la valeur pour laquelle la division peut être transformée inconditionnellement. Au lieu de cela, ce que je suggère est d'appliquer une simple analyse de valeur à partir du début de la fonction qui, dans ce cas, détermine que x est un flotteur fini soit +0.0f ou au moins 2 -24 en grandeur, et d'utiliser cette information pour appliquer la transformation de Brisebarre et al, confiant dans la connaissance que x * C2 ne dépassement de capacité.
pour être explicite, je suggère d'utiliser un algorithme comme celui ci-dessous pour décider s'il faut ou non transformer la division en quelque chose de plus simple:
- Est
Yl'une des valeurs qui peuvent être transformés à l'aide Brisebarre et al de la méthode en fonction de leur algorithme? - do C1 et C2 de leur méthode ont le même signe, ou est-il possible d'exclure la possibilité que le dividende soit infini?
- est-ce que C1 et C2 de leur méthode ont le même signe, ou peut
xprendre seulement une des deux représentations de 0? Si dans le cas où C1 et C2 ont des signes différents etxne peut être qu'une représentation de zéro, n'oubliez pas de bidouiller(**) avec les signes du calcul basé sur FMA pour le faire produire le zéro correct quandxest zéro. - L'importance du dividende peut-elle être suffisamment importante pour exclure la possibilité que
x * C2soit sous-payé?
si la réponse aux quatre questions est "oui", alors la division peut être transformée en multiplication et en FMA dans le contexte de la fonction compilée. L'analyse statique décrite ci-dessus sert à répondre aux questions 2., 3. et 4.
( * * ) "jouer avec les signaux" signifie utiliser -FMA (- C1, x, (- C2)*x) au lieu de FMA (C1, x, C2*x) lorsque cela est nécessaire pour rendre résultat sorti correctement lorsque x ne peut être qu'un des deux zéros signés
Le résultat d'une division à virgule flottante est:
- un signe indicateur
- un significande
- un exposant
- un ensemble d'indicateurs (dépassement de, dépassement de capacité, inexactes, etc - voir
fenv())
obtenir les 3 premières pièces correctes (mais le jeu de drapeaux incorrect) n'est pas suffisant. Sans autre connaissance (par exemple, quelles parties du résultat comptent réellement), les valeurs possibles du dividende, etc) je supposerais que le remplacement de la division par une constante avec multiplication par une constante (et/ou un désordre FMA alambiqué) est presque jamais sûr.
de plus; pour les CPU modernes, Je ne dirais pas non plus que le remplacement d'une division par deux Scfg est toujours une amélioration. Par exemple, si le goulot d'étranglement est l'instruction fetch/decode, cette "optimisation" aggraverait les performances. Pour un autre exemple, si les instructions suivantes ne dépend du résultat (le CPU peut faire beaucoup d'autres instructions en parallèle en attendant le résultat) la version FMA peut introduire des décrochages de dépendances multiples et aggraver les performances. Pour un troisième exemple, si tous les registres sont utilisés, la version FMA (qui nécessite des variables "live" supplémentaires) peut augmenter le "débordement" et aggraver les performances.
il faut Noter que, dans de nombreux cas mais pas tous) de la division ou la multiplication par une constante de multiples de 2 peut être fait avec addition seule (spécifiquement, en ajoutant un nombre de décalage à l'exposant).
j'aime @Pascal 'S réponse mais en optimisation, il est souvent préférable d'avoir un sous-ensemble simple et bien compris de transformations plutôt que d'une solution parfaite.
tous les formats flottants historiques courants et communs avaient une chose en commun: un mantissa binaire.
par conséquent, toutes les fractions étaient des nombres rationnels de la forme:
x / 2 n
ceci est en contraste avec les constantes dans le programme (et toutes les fractions de base possibles-10) qui sont des nombres rationnels de la forme:
x / (2 n * 5 m )
ainsi, une optimisation testerait simplement l'entrée et la réciproque pour m = = 0, puisque ces nombres sont représentés exactement dans le format FP et les opérations doivent produire des données exactes dans le format.
ainsi, par exemple, à l'intérieur de la fourchette (décimale à deux chiffres) de .01 à 0.99 en divisant ou en multipliant par les nombres suivants serait optimisé:
.25 .50 .75
et tout le reste ne le ferait pas. (Je pense, ne tester d'abord, lol.)