Est-ce que les sessions violent vraiment le repos?
est-ce que l'utilisation de sessions dans une API RESTful viole réellement RESTfulness? J'ai vu beaucoup d'opinions allant dans l'une ou l'autre direction, mais je ne suis pas convaincu que les sessions sont agité . De mon point de vue:
- l'authentification n'est pas interdite pour le repos (sinon il y aurait peu d'utilisation dans les services Reposful)
- l'authentification se fait par l'envoi d'un jeton d'authentification dans la demande, généralement de l'en-tête
- ce jeton d'authentification doit être obtenue en quelque sorte et peut être révoquée, auquel cas il doit être renouvelé
- le token d'authentification doit être validé par le serveur (sinon ce ne serait pas une authentification)
alors comment les sessions violent-elles cela?
- côté client, les sessions sont réalisées en utilisant des cookies
- les cookies sont simplement un en-tête HTTP supplémentaire
- un cookie de session peut être obtenu et révoqué à tout moment
- les cookies de session peuvent avoir une durée de vie infinie si besoin est
- l'id de session (token d'authentification) est validé côté serveur
en tant que tel, pour le client, un cookie de session est exactement le même que tout autre mécanisme D'authentification basé sur L'en-tête HTTP, sauf qu'il utilise l'en-tête Cookie au lieu du Authorization ou certains autre en-tête propriétaire. S'il n'y avait pas de session liée à la valeur du cookie côté serveur, pourquoi cela ferait-il une différence? L'implémentation côté serveur n'a pas besoin de concerner le client tant que le serveur se comporte RESTful. En tant que tels , les cookies en eux-mêmes ne devraient pas faire une API agité , et les sessions sont tout simplement des cookies pour le client.
mes suppositions sont-elles fausses? Ce qui rend les cookies de session agité ?
6 réponses
d'abord, définissons quelques termes:
- "151900920 de" repos:
on peut caractériser les demandes conformes aux contraintes de repos décrit dans cette section comme "reposant".[15] si un service enfreint parmi les contraintes requises, elle ne peut être considérée comme reposante.
selon wikipedia .
-
apatrides contrainte:
nous ajoutons ensuite une contrainte à l'interaction client-serveur: la communication doit être de nature apatride, comme dans client-stateless-server (CSS) style de la Section 3.4.3 (Figure 5-3)), de telle sorte que chaque requête du client au serveur doit contenir toutes les informations nécessaires pour comprendre la demande, et ne peut pas prendre avantage de toute stockées contexte sur le serveur. L'état de la Session est donc gardé entièrement sur la client.
, selon le Fielding thèse .
ainsi les sessions côté serveur violent la contrainte apatride du repos, et donc du repos non plus.
en tant que tel, pour le client, un cookie de session est exactement le même que tout autre mécanisme D'authentification basé sur L'en-tête HTTP, sauf qu'il utilise l'en-tête du Cookie au lieu de L'autorisation ou certains autres propriétaire d'en-tête.
par cookies de session vous enregistrez l'état du client sur le serveur et donc votre demande a un contexte. Essayons d'ajouter un équilibreur de charge et une autre instance de service à votre système. Dans ce cas, vous devez partager les sessions entre les instances du service. Il est difficile de maintenir et d'étendre un tel système, alors qu'il évolue mal...
à mon avis, il n'y a rien de mal à utiliser des cookies. La technologie des cookies est mécanisme de stockage côté client dans lequel les données stockées est attaché automatiquement aux en-têtes de cookie par chaque demande. Je ne connais pas de contrainte de repos qui pose problème avec ce genre de technologie. Il n'y a donc aucun problème avec la technologie elle-même, le problème réside dans son utilisation. Fielding a écrit une sous-section sur les raisons pour lesquelles il pense que les cookies HTTP sont mauvais.
de mon point de vue:
- l'authentification n'est pas interdite pour le repos (sinon, il y aurait peu d'utilisation dans les services de repos)
- l'authentification se fait par l'envoi d'un token d'authentification dans la requête, généralement l'en-tête
- ce jeton d'authentification doit être obtenue en quelque sorte et peut être révoquée, auquel cas il doit être renouvelé
- le token d'authentification doit être validé par le serveur (sinon ce ne serait pas une authentification)
Votre point de vue était assez solide. Le seul problème était avec le concept de créer un token d'authentification sur le serveur. Vous n'avez pas besoin de cette partie. Ce que vous avez besoin est de stocker le nom d'utilisateur et le mot de passe sur le client et l'envoyer avec chaque demande. Vous n'avez pas besoin de plus pour ce faire que de HTTP basic auth et d'une connexion cryptée:
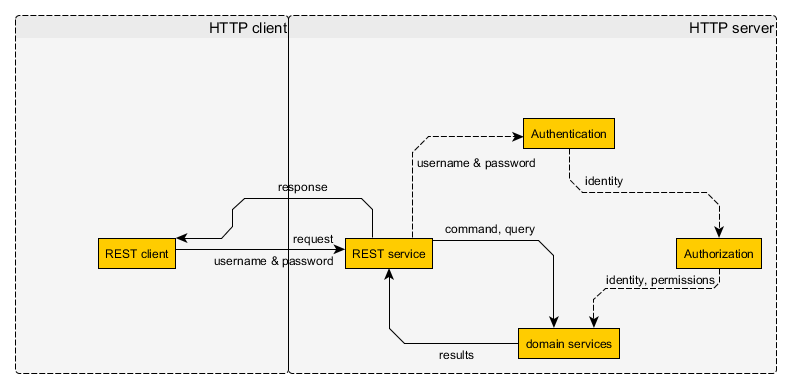
- Figure 1. - Authentification apatride par des clients de confiance
vous avez probablement besoin d'un cache auth en mémoire du côté du serveur pour rendre les choses plus rapides, puisque vous devez authentifier chaque requête.
maintenant cela fonctionne assez bien par des clients de confiance écrit par vous, mais qu'en est-il des clients tiers? Ils ne peuvent pas avoir le nom d'utilisateur et le mot de passe et toutes les permissions des utilisateurs. Vous devez donc stocker séparément les permissions d'un tiers client peut avoir par un utilisateur spécifique. Ainsi, les développeurs clients peuvent enregistrer leurs clients tiers, et obtenir une clé API unique et les utilisateurs peuvent permettre aux clients tiers d'accéder à une partie de leurs permissions. Comme lire le nom et l'adresse e-mail, ou la liste de leurs amis, etc... Après avoir autorisé un client tiers, le serveur générera un token d'accès. Ce token d'accès peut être utilisé par le client tiers pour accéder aux permissions accordées par l'utilisateur, comme suit:
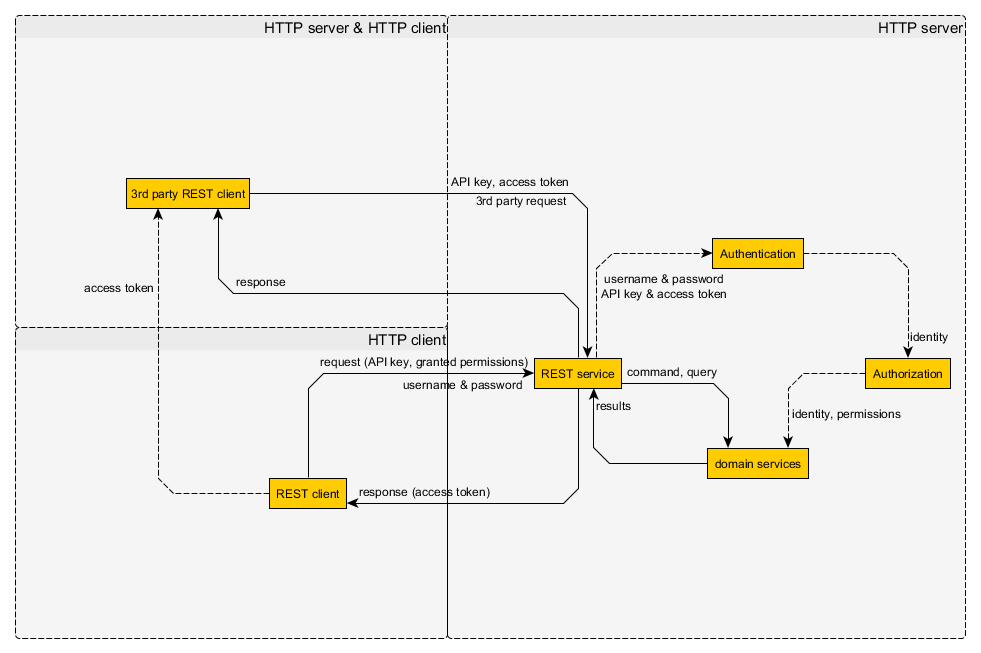
- de la Figure 2. - Authentification apatride par des clients tiers
ainsi le client tiers peut obtenir le token d'accès d'un client de confiance (ou directement de l'utilisateur). Après cela, il peut envoyer une requête valide avec la clé API et le token d'accès. Il s'agit du mécanisme d'autorisation le plus basique pour les tiers. Vous pouvez lire plus sur les détails de mise en œuvre dans la documentation de chaque Système d'autorisation par une tierce partie, par exemple OAuth. Bien sûr, cela peut être plus complexe et plus sûr, par exemple, vous pouvez signer les détails de chaque requête du côté du serveur et envoyer la signature avec la requête, et ainsi de suite... La solution actuelle dépend du besoin de votre application.
tout d'abord, le repos n'est pas une religion et ne doit pas être abordé comme telle. Bien qu'il y ait des avantages à des services reposants, vous ne devriez suivre les principes du repos que dans la mesure où ils sont sensés pour votre application.
cela dit, l'authentification et l'État côté client ne violent pas les principes REST. Tandis que REST exige que les transitions d'État soient apatrides, cela se réfère au serveur lui-même. Au fond, tout le repos est une question de documents. L'idée derrière l'apatridie est que le serveur est apatride, pas les clients. Tout client émettant une demande identique (mêmes en-têtes, cookies, URI, etc.) doit être amené au même endroit dans l'application. Si le site stockait l'emplacement actuel de l'utilisateur et la navigation gérée en mettant à jour cette variable de navigation côté serveur, alors le repos serait violé. Un autre client avec des informations de requête identiques serait amené à un emplacement différent selon l'État côté serveur.
les services web de Google sont un exemple fantastique d'un système reposant. Ils nécessitent un en-tête d'authentification avec la clé d'authentification de l'utilisateur à transmettre à chaque requête. Cela viole légèrement les principes REST, car le serveur suit l'état de la clé d'authentification. L'état de cette clé doit être maintenu et elle a une sorte de date/heure d'expiration après laquelle elle n'accorde plus l'accès. Cependant, comme je l'ai mentionné au sommet de mon poste, des sacrifices doivent être faits pour permettre à une application de fonctionner réellement. Cela dit, les clés d'authentification doivent être stockées de manière à permettre à tous les clients éventuels de continuer à accorder l'accès pendant leur période de validité. Si un serveur gère l'état de la clé d'authentification au point qu'un autre serveur à charge équilibrée ne peut pas prendre en charge les requêtes de satisfaction basées sur cette clé, vous avez commencé à vraiment violer les principes de repos. Les services de Google assurent que, à tout moment, vous pouvez prendre un token d'authentification vous utilisez sur votre téléphone contre le serveur de balance de charge A et appuyez sur le serveur de balance de charge B de votre bureau et ont toujours accès au système et être dirigés vers les mêmes ressources si les demandes étaient identiques.
ce que tout cela revient à dire, c'est que vous devez vous assurer que vos jetons d'authentification sont validés par rapport à une sorte de stock de sauvegarde (base de données, cache, n'importe quoi) pour vous assurer que vous préservez autant de propriétés REST que possible.
I espérons que tout cela fait sens. Vous devriez également consulter la section contraintes du article Wikipédia sur le transfert D'État représentatif si vous ne l'avez pas déjà fait. Il est particulièrement éclairant en ce qui concerne ce que les principes du repos défendent réellement et pourquoi.
ne sont pas destinés à l'authentification. Pourquoi réinventer une roue? HTTP a des mécanismes d'authentification bien conçus. Si nous utilisons des cookies, nous tombons dans L'utilisation HTTP comme un protocole de transport seulement, nous devons donc créer notre propre "système de signalisation , par exemple, pour dire aux utilisateurs qu'ils ont fourni une authentification incorrecte (en utilisant HTTP 401 serait incorrecte car nous ne fournirions probablement Www-Authenticate à un client, comme les spécifications HTTP exigent :) ). Il convient également de noter que Set-Cookie est seulement une recommandation pour le client. Son contenu peut être ou ne pas être sauvegardé (par exemple, si les cookies sont désactivés), alors que l'en-tête Authorization est envoyé automatiquement sur chaque requête.
un autre point est que, pour obtenir un cookie d'autorisation, vous voudrez probablement fournir vos justificatifs d'identité quelque part d'abord? Si c'est le cas, ne serait-il pas agité? Exemple Simple:
- Vous essayez de
GET /asans témoin - , Vous obtenez une demande d'autorisation en quelque sorte
- vous allez et autorisez en quelque sorte comme
POST /auth - , Vous obtenez
Set-Cookie - vous essayez
GET /aavec cookie. MaisGET /ase comporte-t-il de manière indifférente dans ce cas?
pour résumer, je crois que si nous accédons à certaines ressources et que nous avons besoin de nous authentifier, alors nous devons nous authentifier sur cette même ressource , nulle part ailleurs.
en fait, la fidélité ne s'applique qu'aux ressources, comme l'indique un identificateur universel de ressources. Donc, pour parler de choses comme headers, cookies, etc. en ce qui concerne le repos n'est pas vraiment approprié. REST peut travailler sur n'importe quel protocole, même s'il se trouve que cela se fait régulièrement sur HTTP.
le principal déterminant est ceci: si vous envoyez un appel REST, qui est un URI, alors une fois que l'appel le fait avec succès au serveur, est-ce que L'URI renvoie le même contenu, en supposant qu'aucune transition n'ait été effectuée (PUT, POST, DELETE)? Ce test exclurait les erreurs ou les requêtes d'authentification retournées, car dans ce cas, la requête n'a pas encore été envoyée au serveur, c'est-à-dire au servlet ou à l'application qui retournera le document correspondant à l'URI donné.
de même, dans le cas d'un poste ou D'un PUT, pouvez-vous envoyer une URI/charge utile donnée, et indépendamment du nombre de fois que vous envoyez le message, il mettra toujours à jour les mêmes données, pour que Les GETs suivants donnent un résultat cohérent?
reste est sur les données de l'application, pas sur les informations de bas niveau nécessaires pour obtenir que les données transférées.
dans le billet de blog suivant, Roy Fielding a donné un bon résumé de toute L'idée de repos:
http://groups.yahoo.com/neo/groups/rest-discuss/conversations/topics/5841
" un système reposant progresse d'un état d'équilibre à la ensuite, et chacun de ces états stables est à la fois un État de départ potentiel et un potentiel de l'état final. C'est-à-dire: un système reposant est un inconnu nombre de composants obéissant à un ensemble de règles simples, tels qu'ils sont toujours au repos ou en transition d'un repos état à un autre Réparateur de l'état. Chaque état peut être complètement compris par la représentation(s) qu'elle contient et l'ensemble de les transitions qu'il fournit, avec les transitions limitée à un ensemble uniforme de actions pour être compréhensible. Le système peut être un diagramme d'état complexe, mais chaque agent utilisateur est seulement capable de voir un État à la fois (l'état d'équilibre actuel) et donc chacun l'état est simple et peut être analysé indépendamment. Un utilisateur, otoh, que, est capable de créer ses propres transitions à tout moment (par exemple, enter une URL, sélectionnez un signet, ouvrez un éditeur, etc.)."
pour en venir à la question de l'authentification, que ce soit au moyen de cookies ou de headers, aussi longtemps que l'information ne fait pas partie de L'URI et post charge utile, il n'a vraiment rien à voir avec le repos du tout. Donc, en ce qui concerne le fait d'être apatride, nous ne parlons que des données de la demande.
par exemple, pendant que l'utilisateur entre des données dans un écran GUI, le client garde une trace des champs qui ont été entrés, qui n'ont pas, des champs requis qui sont manquants, etc. C'est tout le contexte CLIENT, et ne doit pas être envoyé ou suivi par le serveur. Ce n' get sent to the server est l'ensemble complet des champs qui doivent être modifiés dans la ressource identifiée (par L'URI), de sorte qu'une transition se produit dans cette ressource d'un État RESTful à un autre.
ainsi, le client garde une trace de ce que l'utilisateur fait, et envoie seulement des transitions d'état logiquement complètes au serveur.
transaction HTTP, basic access authentication, n'est pas adapté pour RBAC, parce que basic access authentication utilise le nom d'utilisateur crypté:mot de passe à chaque fois pour identifier, alors que ce qui est nécessaire dans RBAC est le rôle que l'utilisateur veut utiliser pour un appel spécifique. RBAC ne valide pas les permissions sur le nom d'utilisateur, mais sur les rôles.
vous pourriez tric autour de concatenate comme ceci: usernameRole: mot de passe, mais c'est une mauvaise pratique, et il est également inefficace parce que quand un l'Utilisateur a plus de rôles, le moteur d'authentification devrait tester tous les rôles dans la concaténation, et que chaque appel à nouveau. Cela détruirait l'un des plus grands avantages techniques du RBAC, à savoir un test d'autorisation très rapide.
de sorte que ce problème ne peut pas être résolu en utilisant l'authentification d'accès de base.
pour résoudre ce problème, le maintien de session est nécessaire, et cela semble, selon certaines réponses, en contradiction avec le repos.
C'est ce que j'aime dans la réponse que le repos ne doit pas être traité comme une religion. Dans les affaires complexes, dans les soins de santé, par exemple, RBAC est absolument commun et nécessaire. Et il serait dommage qu'ils ne soient pas autorisés à utiliser le repos parce que tous les concepteurs D'outils de repos traiteraient le repos comme une religion.
pour moi il n'y a pas beaucoup de façons de maintenir une session sur HTTP. On peut utiliser des cookies, avec un sessionId, ou un en-tête avec un sessionId.
Si quelqu'un a une autre idée je serai heureux de l'entendre.
- les Sessions ne sont pas agitées
- voulez-vous dire ce service de repos pour l'utilisation http seulement ou j'ai eu smth tort? La session basée sur les cookies ne doit être utilisée que pour own(!) services basés sur http! (Il pourrait être un problème de travailler avec cookie, par exemple à partir de Mobile/Console/bureau/etc.)
- si vous fournissez un service reposant aux développeurs 3d, n'utilisez jamais de session basée sur les Cookies, utilisez plutôt des tokens pour éviter les problèmes de sécurité.