différences de heatmap / clustering par défaut dans R (heatplot versus heatmap.2)?
je compare deux façons de créer des heatmaps avec des dendrogrammes en R, une avec made4heatplot et un gplotsheatmap.2. Les résultats appropriés dépendent de l'analyse, mais j'essaie de comprendre pourquoi les valeurs par défaut sont si différentes, et comment obtenir que les deux fonctions donnent le même résultat (ou un résultat très similaire) pour que je comprenne tous les paramètres de la "boîte noire" qui entrent en jeu.
Ceci est l'exemple de données et des paquets:
require(gplots)
# made4 from bioconductor
require(made4)
data(khan)
data <- as.matrix(khan$train[1:30,])
regroupement des données avec heatmap.2 donne:
heatmap.2(data, trace="none")
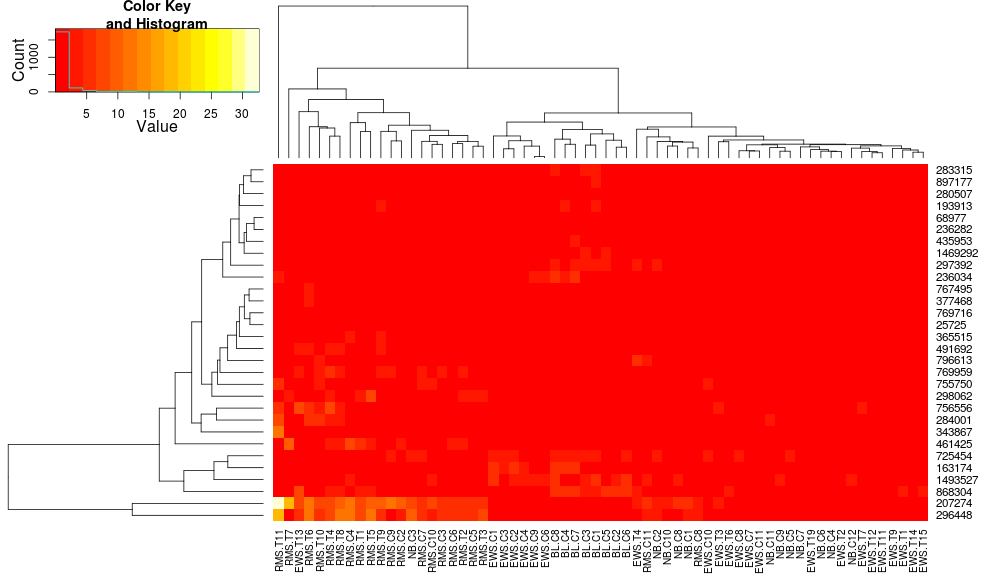
en utilisant heatplot donne:
heatplot(data)
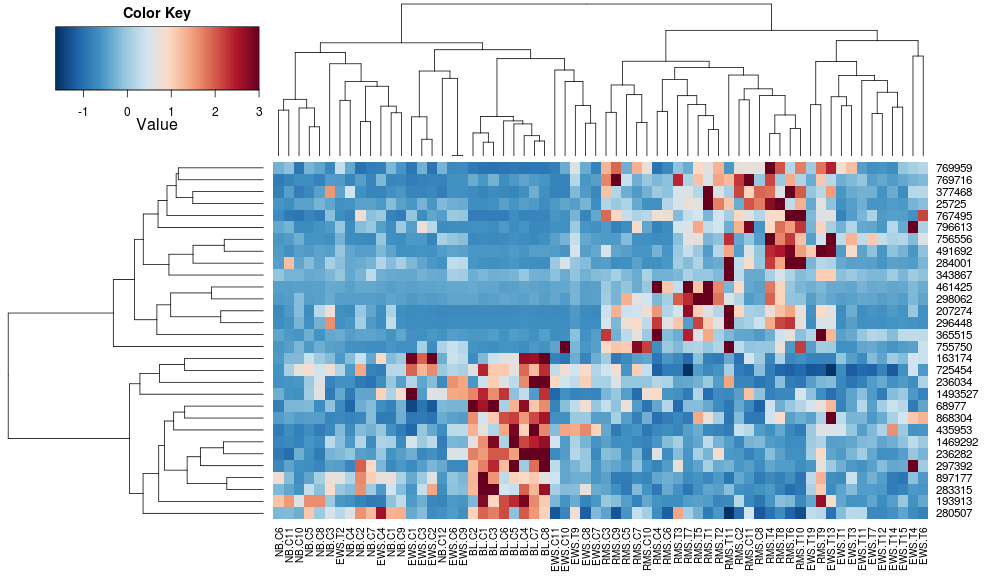
résultats et écaillements très différents au départ. heatplot les rà © sultats semblent plus raisonnables dans ce cas, donc j'aimerais comprendre quels paramÃtres ajouter à heatmap.2 pour l'obtenir à faire de même, car heatmap.2 a d'autres avantages / caractéristiques que je voudrais utiliser et parce que Je veux comprendre les ingrédients manquants.
heatplot utilise le lien moyen avec la distance de corrélation de sorte que nous pouvons alimenter que dans heatmap.2 pour s'assurer que des regroupements similaires sont utilisés (basé sur:https://stat.ethz.ch/pipermail/bioconductor/2010-August/034757.html)
dist.pear <- function(x) as.dist(1-cor(t(x)))
hclust.ave <- function(x) hclust(x, method="average")
heatmap.2(data, trace="none", distfun=dist.pear, hclustfun=hclust.ave)
résultant dans:
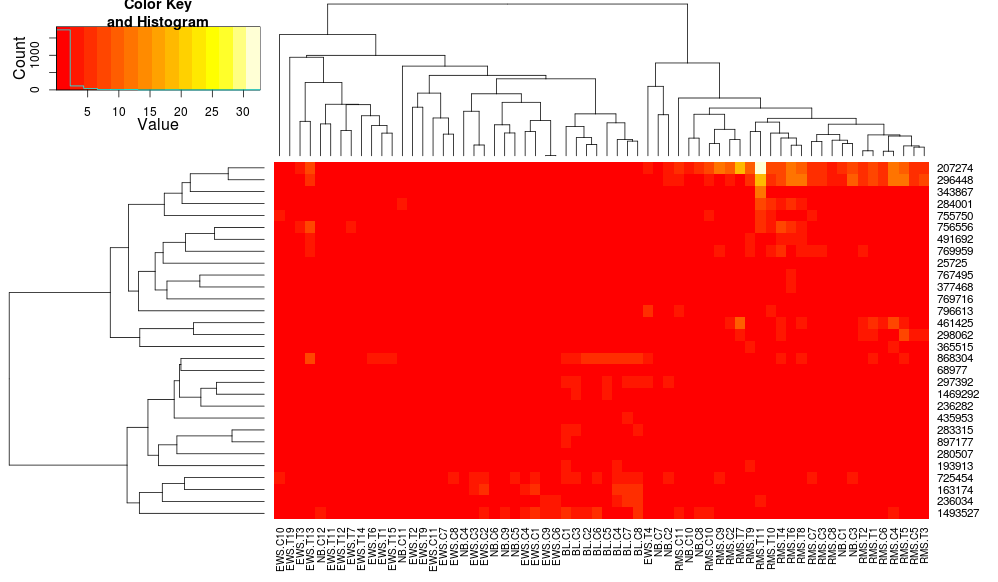
cela rend les dendrogrammes côté ligne plus semblables, mais les colonnes sont encore différentes et les échelles aussi. Il semble que heatplot échelles les colonnes en quelque sorte par défaut heatmap.2 ne fait pas cela par défaut. Si j'ajoute une ligne-échelle à heatmap.2, j'obtiens:
heatmap.2(data, trace="none", distfun=dist.pear, hclustfun=hclust.ave,scale="row")
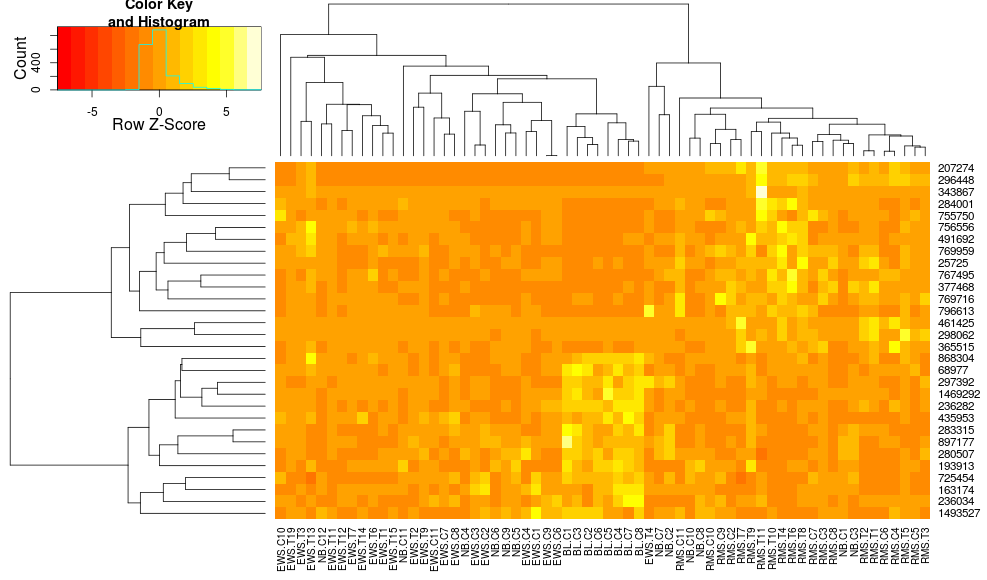
qui n'est toujours pas identique mais qui est plus proche. Comment puis-je reproduire heatplotrésultats heatmap.2? Quelles sont les différences?
edit2: il semble que l'une des principales différences est que heatplot redimensionne les données avec les lignes et les colonnes, en utilisant:
if (dualScale) {
print(paste("Data (original) range: ", round(range(data),
2)[1], round(range(data), 2)[2]), sep = "")
data <- t(scale(t(data)))
print(paste("Data (scale) range: ", round(range(data),
2)[1], round(range(data), 2)[2]), sep = "")
data <- pmin(pmax(data, zlim[1]), zlim[2])
print(paste("Data scaled to range: ", round(range(data),
2)[1], round(range(data), 2)[2]), sep = "")
}
c'est ce que j'essaie d'importer à mon appel à heatmap.2. La raison pour laquelle je l'aime est parce qu'il rend les contrastes plus grands entre les valeurs basses et élevées, alors que juste passer zlimheatmap.2 est simplement ignoré. Comment puis-je utiliser cette "double échelle" tout en préservant le regroupement le long des colonnes? Tout ce que je veux, c'est la hausse de contraste que vous obtenez avec:
heatplot(..., dualScale=TRUE, scale="none")
par rapport au faible contraste que vous obtenez avec:
heatplot(..., dualScale=FALSE, scale="row")
toutes les idées sur ce point?
1 réponses
Les principales différences entre heatmap.2 et heatplot fonctions sont les suivantes:
heatmap.2, en tant que par défaut utilise euclidienne mesure d'obtenir la matrice de distance et complet méthode d'agglomération pour le groupement, alors que heatplot utilise corrélation et moyenne méthode d'agglomération, respectivement.
heatmap.2 calcule la matrice de distance et exécute la segmentation algorithme avant mise à l'échelle, alors que heatplot (quand
dualScale=TRUE) clusters déjà réduit de données.heatmap.2 réordonne le dendrogramme en fonction des valeurs moyennes de la ligne et de la colonne, comme décrit ici.
paramètres par défaut( p. 1) peut être simplement modifié dans heatmap.2, en fournissant customdistfun et hclustfun arguments. Toutefois p. 2 et 3 ne peuvent pas être facilement traitées, sans modifier le code source. Donc heatplot fonction agit comme un wrapper pour heatmap.2. Tout d'abord, il applique la transformation nécessaire aux données, calcule la matrice de distance, regroupe les données, puis utilise heatmap.2 fonctionnalité seulement pour tracer le heatmap avec les paramètres ci-dessus.
dualScale=TRUE argument dans la fonction heatplot, n'applique que le centrage et la mise à l'échelle basés sur les lignes ( description). Ensuite, il réaffecte les extrêmes ( description) des données graduées à zlim valeurs:
z <- t(scale(t(data)))
zlim <- c(-3,3)
z <- pmin(pmax(z, zlim[1]), zlim[2])
pour correspondre à la sortie de la fonction heatplot, j'aimerais proposer deux solutions:
I-ajouter de nouvelles fonctionnalités au code source -> heatmap.3
Le code peut être trouvé ici. N'hésitez pas à parcourir les révisions pour voir les modifications apportées à heatmap.2 la fonction. En résumé, j'ai introduit les options suivantes:
- transformation de z-score est effectuée avant le regroupement (clustering):
scale=c("row","column") - les valeurs extrêmes peuvent être réassignées dans les données scalées:
zlim=c(-3,3) - option pour désactiver le réarrangement du dendrogramme:
reorder=FALSE
Un exemple:
# require(gtools)
# require(RColorBrewer)
cols <- colorRampPalette(brewer.pal(10, "RdBu"))(256)
distCor <- function(x) as.dist(1-cor(t(x)))
hclustAvg <- function(x) hclust(x, method="average")
heatmap.3(data, trace="none", scale="row", zlim=c(-3,3), reorder=FALSE,
distfun=distCor, hclustfun=hclustAvg, col=rev(cols), symbreak=FALSE)
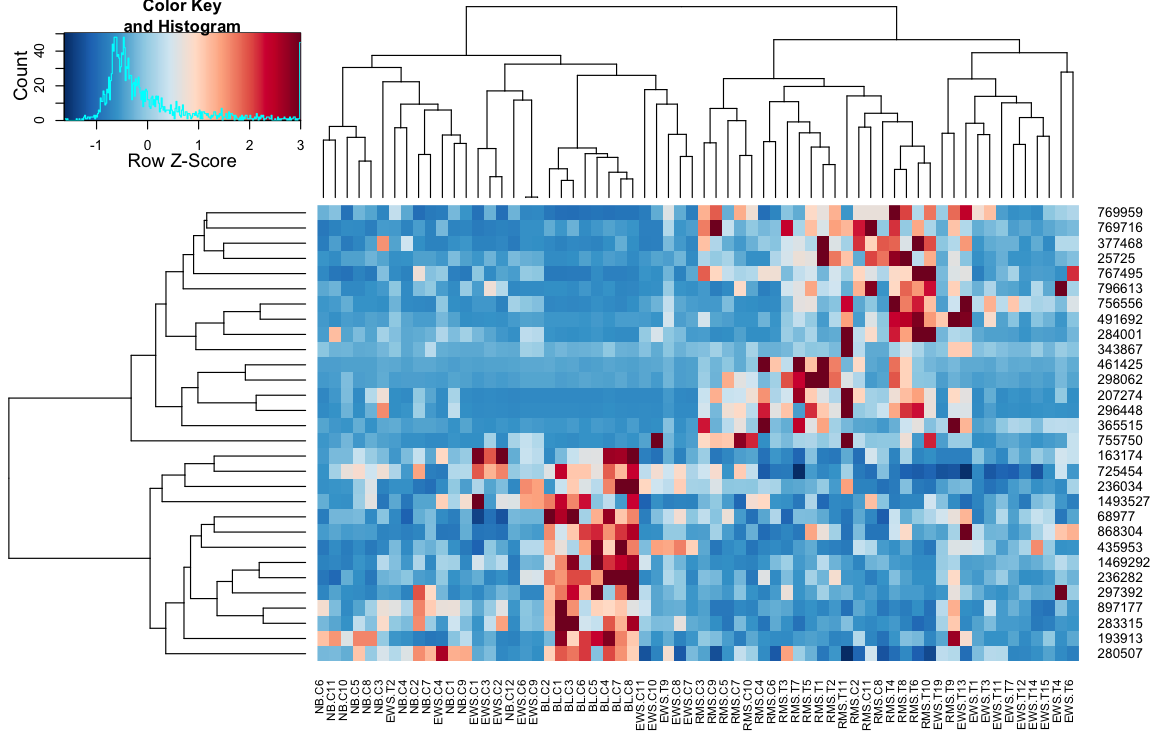
II - définir une fonction qui fournit tous les arguments requis pour l' heatmap.2
si vous préférez utiliser le heatmap original.2, le zClust la fonction (ci-dessous) reproduit toutes les étapes effectuées par heatplot. Il fournit (dans un format de liste) la matrice de données graduées, la rangée et les dendrogrammes de colonne. Ceux-ci peuvent être utilisés comme entrée dans heatmap.2 fonction:
# depending on the analysis, the data can be centered and scaled by row or column.
# default parameters correspond to the ones in the heatplot function.
distCor <- function(x) as.dist(1-cor(x))
zClust <- function(x, scale="row", zlim=c(-3,3), method="average") {
if (scale=="row") z <- t(scale(t(x)))
if (scale=="col") z <- scale(x)
z <- pmin(pmax(z, zlim[1]), zlim[2])
hcl_row <- hclust(distCor(t(z)), method=method)
hcl_col <- hclust(distCor(z), method=method)
return(list(data=z, Rowv=as.dendrogram(hcl_row), Colv=as.dendrogram(hcl_col)))
}
z <- zClust(data)
# require(RColorBrewer)
cols <- colorRampPalette(brewer.pal(10, "RdBu"))(256)
heatmap.2(z$data, trace='none', col=rev(cols), Rowv=z$Rowv, Colv=z$Colv)
Quelques commentaires supplémentaires concernant heatmap.2(3) fonctionnalités:
symbreak=TRUEest recommandé lors de l'application d'échelle. Il ajustera l'échelle de couleur, de sorte qu'il se brise autour de 0. Dans l'exemple actuel, le les valeurs négatives = bleu, tandis que les valeurs positives = rouge.col=bluered(256)peut fournir une solution colorante alternative, et il ne nécessite pas de bibliothèque RColorBrewer.