Différence entre les fonctions MPI Allgather et MPI Alltoall?
Quelle est la principale différence entre les fonctions MPI_Allgather et MPI_Alltoall dans MPI?
je veux dire quelqu'un peut-il me donner des exemples où MPI_Allgather sera utile et MPI_Alltoall ne sera pas? et vice-versa.
Je ne suis pas capable de comprendre la différence principale? Il semble que dans les deux cas, tous les processus envoient des éléments send_cnt à tous les autres processus participant au communicateur et les reçoivent?
Merci
3 réponses
une image dit plus de mille mots, donc voici plusieurs images d'art ASCII:
rank send buf recv buf
---- -------- --------
0 a,b,c MPI_Allgather a,b,c,A,B,C,#,@,%
1 A,B,C ----------------> a,b,c,A,B,C,#,@,%
2 #,@,% a,b,c,A,B,C,#,@,%
C'est le MPI_Gather, ce n'est que dans ce cas que tous les processus reçoivent les blocs de données, c'est-à-dire que l'opération est sans racine.
rank send buf recv buf
---- -------- --------
0 a,b,c MPI_Alltoall a,A,#
1 A,B,C ----------------> b,B,@
2 #,@,% c,C,%
(a more elaborate case with two elements per process)
rank send buf recv buf
---- -------- --------
0 a,b,c,d,e,f MPI_Alltoall a,b,A,B,#,@
1 A,B,C,D,E,F ----------------> c,d,C,D,%,$
2 #,@,%,$,&,* e,f,E,F,&,*
(regarde mieux si chaque élément est colorée par le rang qui l'envoie, mais...)
MPI_Alltoall fonctionne comme combinée MPI_Scatter et MPI_Gather - le tampon d'envoi dans chaque processus est divisé comme dans MPI_Scatter et puis chaque la colonne de morceaux est rassemblée par le processus respectif, dont le rang correspond au nombre de la colonne de morceaux. MPI_Alltoall peut aussi être considéré comme une opération de transposition globale, agissant sur des morceaux de données.
Est-il lorsque les deux opérations sont interchangeables? Pour répondre correctement à cette question, il suffit d'analyser les tailles des données dans le tampon d'envoi et des données dans le tampon de réception:
operation send buf size recv buf size
--------- ------------- -------------
MPI_Allgather sendcnt n_procs * sendcnt
MPI_Alltoall n_procs * sendcnt n_procs * sendcnt
la taille du tampon receive est en fait n_procs * recvcnt, mais MPI exige que le nombre d'éléments de base envoyés soit égal au nombre d'éléments de base reçus, donc si le même type de données MPI est utilisé dans les parties envoyer et recevoir de MPI_All..., puis recvcnt doit être égal à sendcnt.
Il est immédiatement évident que, pour la même taille des données reçues, la quantité de données envoyées par chaque processus est différent. Pour que les deux opérations soient égales, une condition nécessaire est que les dimensions des tampons envoyés dans les deux cas soient l'égalité, c'est à dire n_procs * sendcnt == sendcnt, qui n'est possible que si n_procs == 1, i.e. s'il n'y a qu'un seul processus, ou si sendcnt == 0, c'est à dire aucune donnée n'est envoyée à tous. Il n'y a donc pas de cas pratiquement viable où les deux opérations sont réellement interchangeables. Mais l'on peut simuler MPI_AllgatherMPI_Alltoall en répétant n_procs fois les mêmes données dans le tampon d'envoi (comme déjà noté par Tyler Gill). Ici c'est l'action de MPI_Allgather avec un élément d'envoyer des tampons:
rank send buf recv buf
---- -------- --------
0 a MPI_Allgather a,A,#
1 A ----------------> a,A,#
2 # a,A,#
Et ici même mis en œuvre avec MPI_Alltoall:
rank send buf recv buf
---- -------- --------
0 a,a,a MPI_Alltoall a,A,#
1 A,A,A ----------------> a,A,#
2 #,#,# a,A,#
L'inverse n'est pas possible - on ne peut pas simuler l'action de MPI_AlltoallMPI_Allgather dans le cas général.
ces deux screenshots ont une explication rapide:
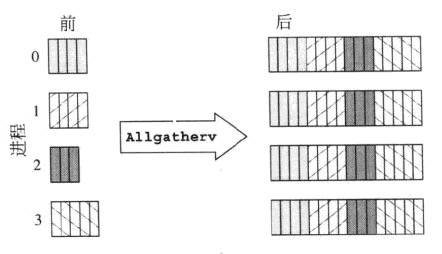
MPI_Allgatherv
MPI_Alltoallv
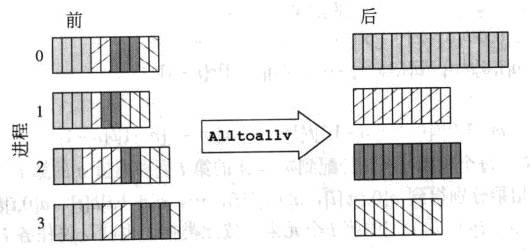
bien que ceci soit une comparaison entre MPI_Allgatherv et MPI_Alltoallv, mais cela explique aussi comment MPI_Allgather diffère de MPI_Alltoall.
bien que ces deux méthodes soient en effet très similaires, il semble y avoir une différence cruciale entre les deux.
MPI_Allgather se termine avec chaque processus ayant exactement les mêmes données dans son tampon de réception, et chaque processus apporte une valeur unique à l'ensemble du tableau. Par exemple, si chacun d'un ensemble de processus devait partager une valeur unique au sujet de son état avec tout le monde, chacun fournirait sa valeur unique. Ces valeurs seraient alors envoyées à tout le monde, donc tout le monde aurait une copie de la même structure.
MPI_Alltoall n'envoie pas les mêmes valeurs à l'autre processus. Au lieu de fournir une valeur unique qui devrait être partagée avec les autres processus, chaque processus spécifie une valeur pour chacun des autres processus. En d'autres termes, avec n Processus, chacun doit spécifier n valeurs à partager. Ensuite, pour chaque processeur j, sa valeur k'TH sera envoyée au traitement de l'indice k's j'th dans le tampon de réception. Ceci est utile si chaque processus dispose d'un message unique et unique pour chacun des processus.
en conclusion, les résultats de l'exécution de allgather et alltoall seraient les mêmes dans le cas où chaque processus remplirait son tampon d'envoi avec la même valeur. La seule différence serait que allgather serait probablement beaucoup plus efficace.