Détecter la région de texte dans L'image en utilisant Opencv
j'ai une image et je veux y détecter les zones de texte.
j'ai essayé le projet TiRG_RAW_20110219 mais les résultats ne sont pas satisfaisants. Si l'image d'entrée est http://imgur.com/yCxOvQS, GD38rCa il produit http://imgur.com/yCxOvQS, GD38rCa#1 en sortie.
quelqu'un Peut-il suggérer quelques alternatives. Je voulais que cela améliore la sortie de tesseract en lui envoyant seulement la région de texte en entrée.
2 réponses
import cv2
def captch_ex(file_name):
img = cv2.imread(file_name)
img_final = cv2.imread(file_name)
img2gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, mask = cv2.threshold(img2gray, 180, 255, cv2.THRESH_BINARY)
image_final = cv2.bitwise_and(img2gray, img2gray, mask=mask)
ret, new_img = cv2.threshold(image_final, 180, 255, cv2.THRESH_BINARY) # for black text , cv.THRESH_BINARY_INV
'''
line 8 to 12 : Remove noisy portion
'''
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (3,
3)) # to manipulate the orientation of dilution , large x means horizonatally dilating more, large y means vertically dilating more
dilated = cv2.dilate(new_img, kernel, iterations=9) # dilate , more the iteration more the dilation
# for cv2.x.x
_, contours, hierarchy = cv2.findContours(dilated, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) # findContours returns 3 variables for getting contours
# for cv3.x.x comment above line and uncomment line below
#image, contours, hierarchy = cv2.findContours(dilated,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)
for contour in contours:
# get rectangle bounding contour
[x, y, w, h] = cv2.boundingRect(contour)
# Don't plot small false positives that aren't text
if w < 35 and h < 35:
continue
# draw rectangle around contour on original image
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 255), 2)
'''
#you can crop image and send to OCR , false detected will return no text :)
cropped = img_final[y :y + h , x : x + w]
s = file_name + '/crop_' + str(index) + '.jpg'
cv2.imwrite(s , cropped)
index = index + 1
'''
# write original image with added contours to disk
cv2.imshow('captcha_result', img)
cv2.waitKey()
file_name = 'your_image.jpg'
captch_ex(file_name)

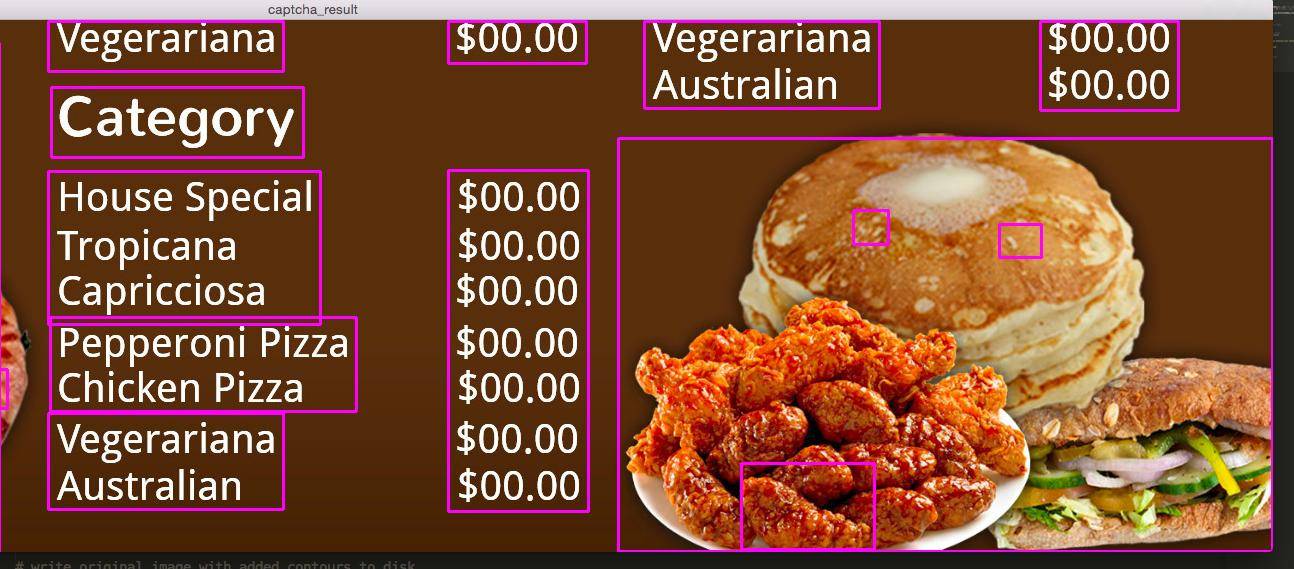
si cela ne vous dérange pas de vous salir les mains, vous pouvez essayer de faire pousser ces régions de texte en une plus grande région rectangulaire, que vous alimentez à tesseract tout d'un coup.
je suggérerais aussi d'essayer de limiter l'image plusieurs fois et d'alimenter chacun de ceux-ci à tesseract séparément pour voir si cela aide à tous. Vous pouvez comparer la sortie aux mots du dictionnaire pour déterminer automatiquement si un résultat OCR particulier est bon ou pas.