Supprimer la colonne de la base de données pandas en utilisant del DF.nom de la colonne
lors de la suppression d'une colonne dans un DataFrame j'utilise:
del df['column_name']
et ça marche très bien. Pourquoi je ne peux pas utiliser ce qui suit?
del df.column_name
comme vous pouvez accéder à la colonne/série comme df.column_name , Je m'attends à ce que cela fonctionne.
13 réponses
il est difficile de faire fonctionner del df.column_name simplement à cause des limitations syntaxiques en Python. del df[name] est traduit en df.__delitem__(name) sous les couvertures par Python.
la meilleure façon de le faire dans pandas est d'utiliser drop :
df = df.drop('column_name', 1)
où 1 est le axe nombre ( 0 pour les lignes et 1 pour les colonnes.)
pour supprimer la colonne sans avoir à réattribuer df vous pouvez faire:
df.drop('column_name', axis=1, inplace=True)
enfin, de passer par la colonne numéro au lieu de par la colonne étiquette , essayez ceci pour supprimer, par exemple les 1ère, 2ème et 4ème colonnes:
df.drop(df.columns[[0, 1, 3]], axis=1) # df.columns is zero-based pd.Index
utiliser:
columns = ['Col1', 'Col2', ...]
df.drop(columns, inplace=True, axis=1)
supprimer une ou plusieurs colonnes en place. Notez que inplace=True a été ajouté dans les pandas v0.13 et ne fonctionne pas sur les anciennes versions. Vous devez affecter le résultat dans ce cas:
df = df.drop(columns, axis=1)
Drop par l'indice
supprimer les première, deuxième et quatrième colonnes:
df.drop(df.columns[[0,1,3]], axis=1, inplace=True)
supprimer la première colonne:
df.drop(df.columns[[0]], axis=1, inplace=True)
il y a un paramètre optionnel inplace de sorte que l'original
les données peuvent être modifiées sans créer de copie.
Sauté
sélection de colonne, Ajout, Suppression
supprimer la colonne column-name :
df.pop('column-name')
exemples:
df = DataFrame.from_items([('A', [1, 2, 3]), ('B', [4, 5, 6]), ('C', [7,8, 9])], orient='index', columns=['one', 'two', 'three'])
print df :
one two three
A 1 2 3
B 4 5 6
C 7 8 9
df.drop(df.columns[[0]], axis=1, inplace=True)
print df :
two three
A 2 3
B 5 6
C 8 9
three = df.pop('three')
print df :
two
A 2
B 5
C 8
la question réelle posée, manquée par la plupart des réponses ici est:
Pourquoi Je ne peux pas utiliser del df.column_name ?
nous devons d'abord comprendre le problème, ce qui nous oblige à plonger dans Python magic methods .
comme Wes le souligne dans sa réponse del df['column'] cartes au python méthode magique df.__delitem__('column') qui est mis en œuvre dans pandas pour supprimer la colonne
Toutefois, comme indiqué dans le lien ci-dessus à propos de python méthodes magiques :
En fait, del ne devrait jamais être utilisée en raison de la précarité de la situation en vertu de laquelle il est appelé; utiliser avec prudence!
vous pourriez soutenir que del df['column_name'] devrait pas être utilisé ou encouragé, et ainsi del df.column_name ne devrait même pas être envisagée.
Cependant, en théorie, del df.column_name pourrait être mis en œuvre pour travailler dans les pandas en utilisant la méthode magique __delattr__ . Cela pose cependant certains problèmes, des problèmes que la mise en œuvre de del df['column_name'] pose déjà, mais à un degré moindre.
Exemple De Problème
et si je définissais une colonne dans une base de données appelée "dtypes" ou "columns".
Alors que je veux supprimer ces colonnes.
del df.dtypes rend la méthode __delattr__ confuse comme si elle devait supprimer l'attribut "dtypes" ou la colonne "dtypes".
questions D'architecture derrière ce problème
- est un dataframe a collection de colonnes ?
- Est-ce qu'un dataframe est une collection de lignes ?
- est une colonne attribut d'une base de données?
Pandas répond:
- Oui, dans tous les sens
- Non, mais si vous le voulez, vous pouvez utiliser les méthodes
.ix,.locou.iloc. - Peut-être, voulez-vous lire les données? Ensuite Oui , sauf si le nom de l'attribut est déjà pris par un autre attribut appartenant au dataframe. Voulez-vous modifier données? Puis Non .
TLDR;
Vous ne pouvez pas faire del df.column_name parce que les pandas a une assez sauvagement cultivé architecture qui doit être repensé pour ce genre de cognitive dissonance ne pas se produire à ses utilisateurs.
Protip:
N'utilisez pas df.column_name, Il est peut-être jolie, mais elle cause dissonance cognitive
Zen de Python citations qui s'inscrit ici:
Il y a plusieurs façons de supprimer une colonne.
Les colonnesil devrait y avoir une-et de préférence une seule-façon évidente de le faire.
sont parfois des attributs, mais parfois non.
les cas spéciaux ne sont pas assez spéciaux pour enfreindre les règles.
est-ce que del df.dtypes supprime l'attribut dtypes ou la colonne dtypes?
face à l'ambiguïté, refusez la tentation de deviner.
une belle addition est la possibilité de colonnes de chute seulement si elles existent . De cette façon, vous pouvez couvrir plus de cas d'utilisation, et il ne laissera tomber les colonnes existantes des étiquettes qui lui sont passées:
il suffit D'ajouter errors='ignore' , par exemple.:
df.drop(['col_name_1', 'col_name_2', ..., 'col_name_N'], inplace=True, axis=1, errors='ignore')
- c'est nouveau à partir de pandas 0.16.1. La Documentation est ici .
de la version 0.16.1 vous pouvez faire
df.drop(['column_name'], axis = 1, inplace = True, errors = 'ignore')
c'est une bonne pratique d'utiliser toujours la notation [] . Une raison est que la notation d'attribut ( df.column_name ) ne fonctionne pas pour les indices numérotés:
In [1]: df = DataFrame([[1, 2, 3], [4, 5, 6]])
In [2]: df[1]
Out[2]:
0 2
1 5
Name: 1
In [3]: df.1
File "<ipython-input-3-e4803c0d1066>", line 1
df.1
^
SyntaxError: invalid syntax
dans pandas 0.16.1+ vous pouvez laisser tomber les colonnes seulement si elles existent selon la solution Postée par @eiTanLaVi. Avant cette version, vous pouvez obtenir le même résultat via une liste de compréhension conditionnelle:
df.drop([col for col in ['col_name_1','col_name_2',...,'col_name_N'] if col in df],
axis=1, inplace=True)
Pandas de 0,21+ répondre
Pandas version 0.21 a modifié légèrement la méthode drop pour inclure à la fois les paramètres index et columns pour correspondre à la signature des méthodes rename et reindex .
df.drop(columns=['column_a', 'column_c'])
personnellement, je préfère utiliser le paramètre axis pour désigner les colonnes ou l'index parce que c'est le paramètre mot-clé prédominant utilisé dans presque toutes les méthodes pandas. Mais, maintenant vous avez quelques choix supplémentaires dans la version 0.21.
TL; DR
beaucoup d'efforts pour trouver une solution légèrement plus efficace. Difficile de justifier la complexité ajoutée tout en sacrifiant la simplicité de df.drop(dlst, 1, errors='ignore')
df.reindex_axis(np.setdiff1d(df.columns.values, dlst), 1)
préambule
Supprimer une colonne est sémantiquement la même chose que sélectionner les autres colonnes. Je vais vous montrer d'autres méthodes à envisager.
je me concentrerai aussi sur le solution générale consistant à supprimer plusieurs colonnes à la fois et à permettre la tentative de supprimer les colonnes absentes.
en utilisant ces solutions sont Générales et fonctionneront pour le cas simple aussi bien.
le programme d'Installation
Considérons le pd.DataFrame df et la liste pour supprimer dlst
df = pd.DataFrame(dict(zip('ABCDEFGHIJ', range(1, 11))), range(3))
dlst = list('HIJKLM')
df
A B C D E F G H I J
0 1 2 3 4 5 6 7 8 9 10
1 1 2 3 4 5 6 7 8 9 10
2 1 2 3 4 5 6 7 8 9 10
dlst
['H', 'I', 'J', 'K', 'L', 'M']
le résultat doit ressembler à:
df.drop(dlst, 1, errors='ignore')
A B C D E F G
0 1 2 3 4 5 6 7
1 1 2 3 4 5 6 7
2 1 2 3 4 5 6 7
puisque j'égalise la suppression d'une colonne à la sélection des autres colonnes, je vais le briser en deux types:
- "1519760920 l'Étiquette de" sélection
- sélection booléenne
Sélection D'Une Étiquette
nous commençons par la fabrication de la liste/tableau d'étiquettes qui représentent les colonnes que nous voulons maintenir et sans les colonnes que nous voulons supprimer.
-
df.columns.difference(dlst)Index(['A', 'B', 'C', 'D', 'E', 'F', 'G'], dtype='object') -
np.setdiff1d(df.columns.values, dlst)array(['A', 'B', 'C', 'D', 'E', 'F', 'G'], dtype=object) -
df.columns.drop(dlst, errors='ignore')Index(['A', 'B', 'C', 'D', 'E', 'F', 'G'], dtype='object') -
list(set(df.columns.values.tolist()).difference(dlst))# does not preserve order ['E', 'D', 'B', 'F', 'G', 'A', 'C'] -
[x for x in df.columns.values.tolist() if x not in dlst]['A', 'B', 'C', 'D', 'E', 'F', 'G']
colonnes des étiquettes
Pour comparer le processus de sélection, supposons:
cols = [x for x in df.columns.values.tolist() if x not in dlst]
alors nous pouvons évaluer
-
df.loc[:, cols] -
df[cols] -
df.reindex(columns=cols) -
df.reindex_axis(cols, 1)
que tous évaluent à:
A B C D E F G
0 1 2 3 4 5 6 7
1 1 2 3 4 5 6 7
2 1 2 3 4 5 6 7
Tranche Booléenne
nous pouvons construire un tableau / liste de booléens pour trancher
-
~df.columns.isin(dlst) -
~np.in1d(df.columns.values, dlst) -
[x not in dlst for x in df.columns.values.tolist()] -
(df.columns.values[:, None] != dlst).all(1)
colonnes de booléen
À des fins de comparaison
bools = [x not in dlst for x in df.columns.values.tolist()]
-
df.loc[: bools]
que tous évaluent à:
A B C D E F G
0 1 2 3 4 5 6 7
1 1 2 3 4 5 6 7
2 1 2 3 4 5 6 7
Timing Robuste
fonctions
setdiff1d = lambda df, dlst: np.setdiff1d(df.columns.values, dlst)
difference = lambda df, dlst: df.columns.difference(dlst)
columndrop = lambda df, dlst: df.columns.drop(dlst, errors='ignore')
setdifflst = lambda df, dlst: list(set(df.columns.values.tolist()).difference(dlst))
comprehension = lambda df, dlst: [x for x in df.columns.values.tolist() if x not in dlst]
loc = lambda df, cols: df.loc[:, cols]
slc = lambda df, cols: df[cols]
ridx = lambda df, cols: df.reindex(columns=cols)
ridxa = lambda df, cols: df.reindex_axis(cols, 1)
isin = lambda df, dlst: ~df.columns.isin(dlst)
in1d = lambda df, dlst: ~np.in1d(df.columns.values, dlst)
comp = lambda df, dlst: [x not in dlst for x in df.columns.values.tolist()]
brod = lambda df, dlst: (df.columns.values[:, None] != dlst).all(1)
Test
res1 = pd.DataFrame(
index=pd.MultiIndex.from_product([
'loc slc ridx ridxa'.split(),
'setdiff1d difference columndrop setdifflst comprehension'.split(),
], names=['Select', 'Label']),
columns=[10, 30, 100, 300, 1000],
dtype=float
)
res2 = pd.DataFrame(
index=pd.MultiIndex.from_product([
'loc'.split(),
'isin in1d comp brod'.split(),
], names=['Select', 'Label']),
columns=[10, 30, 100, 300, 1000],
dtype=float
)
res = res1.append(res2).sort_index()
dres = pd.Series(index=res.columns, name='drop')
for j in res.columns:
dlst = list(range(j))
cols = list(range(j // 2, j + j // 2))
d = pd.DataFrame(1, range(10), cols)
dres.at[j] = timeit('d.drop(dlst, 1, errors="ignore")', 'from __main__ import d, dlst', number=100)
for s, l in res.index:
stmt = '{}(d, {}(d, dlst))'.format(s, l)
setp = 'from __main__ import d, dlst, {}, {}'.format(s, l)
res.at[(s, l), j] = timeit(stmt, setp, number=100)
rs = res / dres
rs
10 30 100 300 1000
Select Label
loc brod 0.747373 0.861979 0.891144 1.284235 3.872157
columndrop 1.193983 1.292843 1.396841 1.484429 1.335733
comp 0.802036 0.732326 1.149397 3.473283 25.565922
comprehension 1.463503 1.568395 1.866441 4.421639 26.552276
difference 1.413010 1.460863 1.587594 1.568571 1.569735
in1d 0.818502 0.844374 0.994093 1.042360 1.076255
isin 1.008874 0.879706 1.021712 1.001119 0.964327
setdiff1d 1.352828 1.274061 1.483380 1.459986 1.466575
setdifflst 1.233332 1.444521 1.714199 1.797241 1.876425
ridx columndrop 0.903013 0.832814 0.949234 0.976366 0.982888
comprehension 0.777445 0.827151 1.108028 3.473164 25.528879
difference 1.086859 1.081396 1.293132 1.173044 1.237613
setdiff1d 0.946009 0.873169 0.900185 0.908194 1.036124
setdifflst 0.732964 0.823218 0.819748 0.990315 1.050910
ridxa columndrop 0.835254 0.774701 0.907105 0.908006 0.932754
comprehension 0.697749 0.762556 1.215225 3.510226 25.041832
difference 1.055099 1.010208 1.122005 1.119575 1.383065
setdiff1d 0.760716 0.725386 0.849949 0.879425 0.946460
setdifflst 0.710008 0.668108 0.778060 0.871766 0.939537
slc columndrop 1.268191 1.521264 2.646687 1.919423 1.981091
comprehension 0.856893 0.870365 1.290730 3.564219 26.208937
difference 1.470095 1.747211 2.886581 2.254690 2.050536
setdiff1d 1.098427 1.133476 1.466029 2.045965 3.123452
setdifflst 0.833700 0.846652 1.013061 1.110352 1.287831
fig, axes = plt.subplots(2, 2, figsize=(8, 6), sharey=True)
for i, (n, g) in enumerate([(n, g.xs(n)) for n, g in rs.groupby('Select')]):
ax = axes[i // 2, i % 2]
g.plot.bar(ax=ax, title=n)
ax.legend_.remove()
fig.tight_layout()
ceci est relatif au temps qu'il faut pour exécuter df.drop(dlst, 1, errors='ignore') . Il semble qu'après tous ces efforts, nous n'améliorons que modestement nos performances.
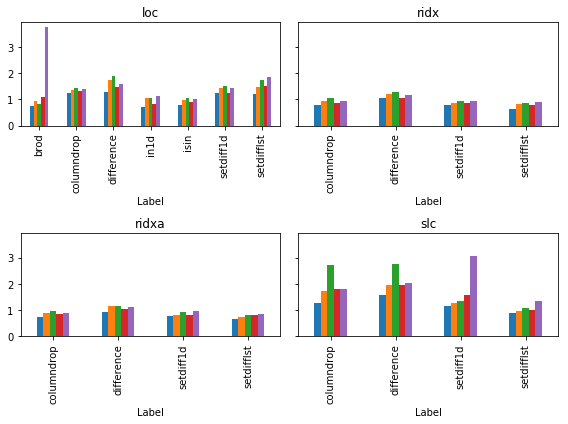
si les meilleures solutions utiliser reindex ou reindex_axis sur le hack list(set(df.columns.values.tolist()).difference(dlst)) . Une seconde proche et encore très légèrement meilleure que drop est np.setdiff1d .
rs.idxmin().pipe(
lambda x: pd.DataFrame(
dict(idx=x.values, val=rs.lookup(x.values, x.index)),
x.index
)
)
idx val
10 (ridx, setdifflst) 0.653431
30 (ridxa, setdifflst) 0.746143
100 (ridxa, setdifflst) 0.816207
300 (ridx, setdifflst) 0.780157
1000 (ridxa, setdifflst) 0.861622
la syntaxe des points fonctionne en JavaScript, mais pas en Python.
- Python:
del df['column_name'] - JavaScript:
del df['column_name']oudel df.column_name
une autre façon de supprimer une colonne dans la base de données Pandas
si vous n'êtes pas à la recherche de suppression en Place, alors vous pouvez créer une nouvelle datagramme en spécifiant les colonnes en utilisant DataFrame(...) fonction comme
my_dict = { 'name' : ['a','b','c','d'], 'age' : [10,20,25,22], 'designation' : ['CEO', 'VP', 'MD', 'CEO']}
df = pd.DataFrame(my_dict)
créer une nouvelle base de données comme
newdf = pd.DataFrame(df, columns=['name', 'age'])
, Vous obtenez un résultat aussi bon que ce que vous obtenez avec del / déposer