Création D'une base de données à partir des résultats D'ElasticSearch
j'essaie de construire une base de données dans pandas, en utilisant les résultats d'une requête très basique à ElasticSearch. Je reçois les Données dont j'ai besoin, mais c'est une question de trancher les résultats d'une manière de construire la bonne trame de données. Je ne me soucie vraiment que d'obtenir l'horodatage, et le chemin, de chaque résultat. J'ai essayé un peu différent es.les modèles de recherche.
Code:
from datetime import datetime
from elasticsearch import Elasticsearch
from pandas import DataFrame, Series
import pandas as pd
import matplotlib.pyplot as plt
es = Elasticsearch(host="192.168.121.252")
res = es.search(index="_all", doc_type='logs', body={"query": {"match_all": {}}}, size=2, fields=('path','@timestamp'))
cela donne 4 morceaux de données. [u'hits', u'_shards', u'took', u'timed_out']. Mes résultats sont à l'intérieur coup.
res['hits']['hits']
Out[47]:
[{u'_id': u'a1XHMhdHQB2uV7oq6dUldg',
u'_index': u'logstash-2014.08.07',
u'_score': 1.0,
u'_type': u'logs',
u'fields': {u'@timestamp': u'2014-08-07T12:36:00.086Z',
u'path': u'app2.log'}},
{u'_id': u'TcBvro_1QMqF4ORC-XlAPQ',
u'_index': u'logstash-2014.08.07',
u'_score': 1.0,
u'_type': u'logs',
u'fields': {u'@timestamp': u'2014-08-07T12:36:00.200Z',
u'path': u'app1.log'}}]
les seules choses qui m'importent, c'est d'obtenir le timestamp, et le chemin pour chaque coup.
res['hits']['hits'][0]['fields']
Out[48]:
{u'@timestamp': u'2014-08-07T12:36:00.086Z',
u'path': u'app1.log'}
Je ne peux pas pour la vie de moi comprendre qui obtenir ce résultat, dans une base de données dans pandas. Donc, pour les 2 résultats que j'ai retournés, Je m'attendrais à une base de données comme.
timestamp path
0 2014-08-07T12:36:00.086Z app1.log
1 2014-08-07T12:36:00.200Z app2.log
4 réponses
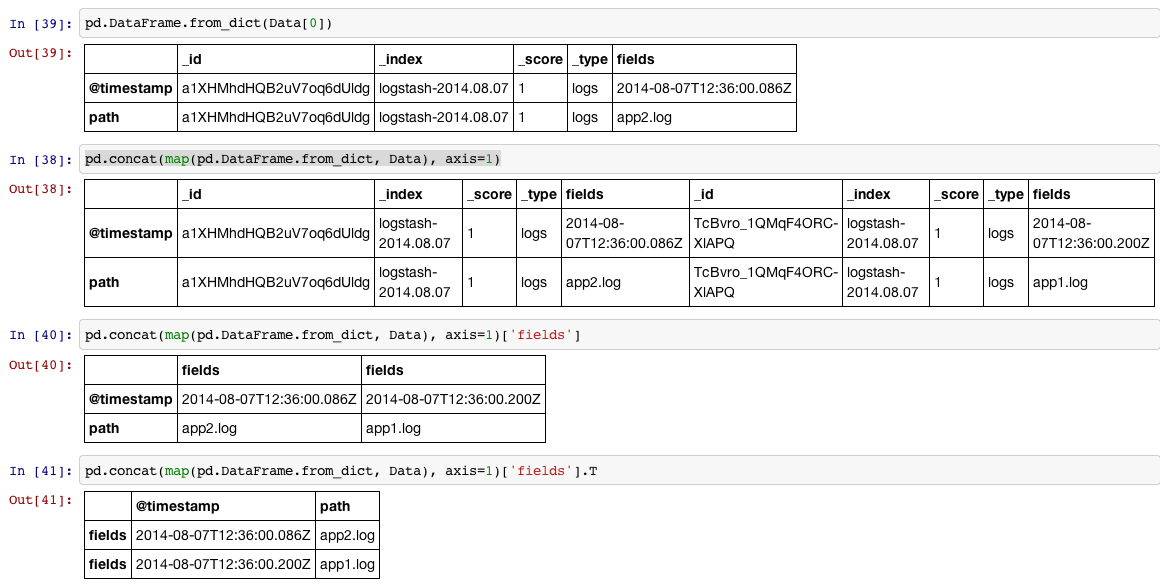
Il y a un beau jouet appelé pd.DataFrame.from_dict que vous pouvez utiliser dans ce genre de situation:
In [34]:
Data = [{u'_id': u'a1XHMhdHQB2uV7oq6dUldg',
u'_index': u'logstash-2014.08.07',
u'_score': 1.0,
u'_type': u'logs',
u'fields': {u'@timestamp': u'2014-08-07T12:36:00.086Z',
u'path': u'app2.log'}},
{u'_id': u'TcBvro_1QMqF4ORC-XlAPQ',
u'_index': u'logstash-2014.08.07',
u'_score': 1.0,
u'_type': u'logs',
u'fields': {u'@timestamp': u'2014-08-07T12:36:00.200Z',
u'path': u'app1.log'}}]
In [35]:
df = pd.concat(map(pd.DataFrame.from_dict, Data), axis=1)['fields'].T
In [36]:
print df.reset_index(drop=True)
@timestamp path
0 2014-08-07T12:36:00.086Z app2.log
1 2014-08-07T12:36:00.200Z app1.log
le Montrer en quatre étapes:
1, Lire chaque élément de la liste (qui est un dictionary) en DataFrame
2, On peut mettre tous les éléments dans la liste dans un grand DataFrame par concat en ce qui concerne la ligne, puisque nous allons faire l'étape#1 pour chaque élément, nous pouvons utiliser map pour le faire.
3, puis on accède aux colonnes marquées avec 'fields'
4, Nous vous voulez probablement tourner le DataFrame 90 degrés (transposer) et reset_index si nous voulons que l'indice de la valeur par défaut int séquence.
ou vous pouvez utiliser la fonction json_normalize de pandas:
from pandas.io.json import json_normalize
df = json_normalize(res['hits']['hits'])
et ensuite filtrer le dataframe de résultat par les noms de colonne
Mieux encore, vous pouvez utiliser le fantastique pandasticsearch bibliothèque:
from elasticsearch import Elasticsearch
es = Elasticsearch('http://localhost:9200')
result_dict = es.search(index="recruit", body={"query": {"match_all": {}}})
from pandasticsearch import Select
pandas_df = Select.from_dict(result_dict).to_pandas()
voici un peu de code que vous pourriez trouver utile pour votre travail. C'est simple, et extensible, mais il m'a été épargné beaucoup de temps lorsque face à juste "saisir" quelques données D'ElasticSearch à analyser.
Si vous voulez juste pour récupérer toutes les données d'un index donné et doc_type de votre localhost vous pouvez faire:
df = ElasticCom(index='index', doc_type='doc_type').search_and_export_to_df()
vous pouvez utiliser n'importe lequel des arguments que vous utilisez habituellement dans elasticsearch.recherche (la), ou spécifier un hôte différent. Vous pouvez également choisir d'inclure le _id ou non, et d'indiquer si les données sont dans "_source" ou des "champs" (il essaie de deviner). Il essaie également de convertir les valeurs de champ par défaut (mais vous pouvez désactiver cette option).
Voici le code:
from elasticsearch import Elasticsearch
import pandas as pd
class ElasticCom(object):
def __init__(self, index, doc_type, hosts='localhost:9200', **kwargs):
self.index = index
self.doc_type = doc_type
self.es = Elasticsearch(hosts=hosts, **kwargs)
def search_and_export_to_dict(self, *args, **kwargs):
_id = kwargs.pop('_id', True)
data_key = kwargs.pop('data_key', kwargs.get('fields')) or '_source'
kwargs = dict({'index': self.index, 'doc_type': self.doc_type}, **kwargs)
if kwargs.get('size', None) is None:
kwargs['size'] = 1
t = self.es.search(*args, **kwargs)
kwargs['size'] = t['hits']['total']
return get_search_hits(self.es.search(*args, **kwargs), _id=_id, data_key=data_key)
def search_and_export_to_df(self, *args, **kwargs):
convert_numeric = kwargs.pop('convert_numeric', True)
convert_dates = kwargs.pop('convert_dates', 'coerce')
df = pd.DataFrame(self.search_and_export_to_dict(*args, **kwargs))
if convert_numeric:
df = df.convert_objects(convert_numeric=convert_numeric, copy=True)
if convert_dates:
df = df.convert_objects(convert_dates=convert_dates, copy=True)
return df
def get_search_hits(es_response, _id=True, data_key=None):
response_hits = es_response['hits']['hits']
if len(response_hits) > 0:
if data_key is None:
for hit in response_hits:
if '_source' in hit.keys():
data_key = '_source'
break
elif 'fields' in hit.keys():
data_key = 'fields'
break
if data_key is None:
raise ValueError("Neither _source nor fields were in response hits")
if _id is False:
return [x.get(data_key, None) for x in response_hits]
else:
return [dict(_id=x['_id'], **x.get(data_key, {})) for x in response_hits]
else:
return []